LeetCode刷题总结1~50
LeetCode刷题总结1~50
- 1. Two Sum
- 2. Add Two Numbers
- 5. Longest Palindromic Substring
- 6. ZigZag Conversion
- 12. Integer to Roman
- 13. Roman to Integer
- 14. Longest Common Prefix
- 15. 3Sum
- 17. Letter Combinations of a Phone Number
- 19. Remove Nth Node From End of List
- 21. Merge Two Sorted Lists
- 38. Count and Say
- 39. Combination Sum
- 40. Combination Sum II
- 46. Permutations
- 48. Rotate Image
- 49. Group Anagrams
1. Two Sum

思路:map的使用
只需要一遍遍历,将target-nums[i]的值存入map中,在遍历的同时,若找到map中存在映射,则输出。
2. Add Two Numbers
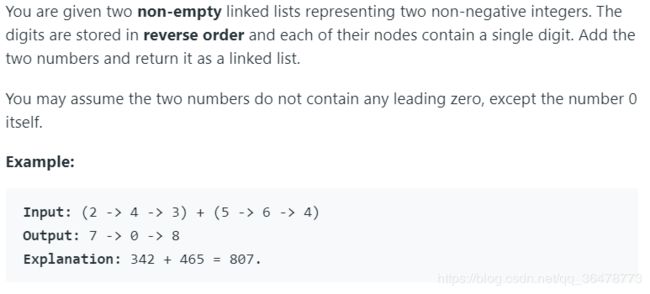
思路:单链表模拟

需要注意头结点的使用,以及最高位进位溢出需要申请新的结点;此题最好申请一个新的链表去做,因为不知道原来的l1和l2的长短情况,不方便使用两者中的谁来存下计算结果。
使用头结点的优势:
- **第1个位置的插入删除更加方便
- 统一空表和非空表的处理**
使用头结点可以避免繁琐的判断及额外指针操作
5. Longest Palindromic Substring

思路:此题为经典的最长回文子串问题,有多种解法:
- Brute Force:三层循环,每次截取
i~j间的子串,然后反转子串reverse(),判断是否相等; - Dynamic Programming:We can define
dp[i,j]as the following:
if the substring is a palindrome,thendp[i,j]=1
elsedp[i,j]=0
therefore we havep[i,j]=p[i-1,j+1]+s[i]==s[j]
The base cases are:
dp[i,i]=1;dp[i,i+1]=(s[i]==s[i+1])
3.Expand Around Center(自己做的,略有差异):we try to find the middle place in the Palindromic Substring,for example,aba,herebis the place we want to find out.But we should take care of this ,when the length of the Palindromic Substring is even ,such asabba,in this situation we can’t just find the middle place.
one solution of this , we can fill ‘#’ into the whole string.For example ,a#b#aanda#b#b#a,and we find that any situation is considered ,so we can just find the mid,and then we define two points which calledleftandright,and then move it back and forth,we can easily find the max Palindromic Substring.
6. ZigZag Conversion
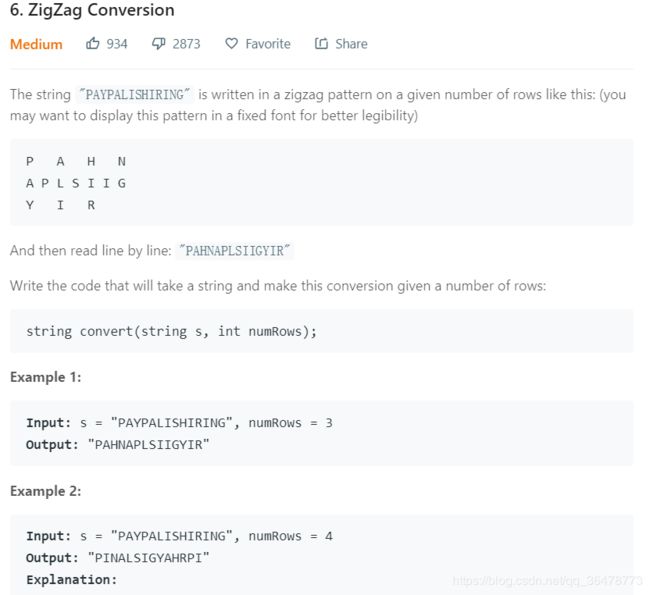
思路:一遍for循环即可,将每行的所有字符都存在字符串数组中,巧妙使用外指针step,每次往下时step++,到count==numRows-1时往回退,step–。
12. Integer to Roman

class Solution {
public:
//15.14---15.21
string intToRoman(int num) {
int a[]={1,4,5,9,10,40,50,90,100,400,500,900,1000};
string s[]={"I","IV","V","IX","X","XL","L","XC","C","CD","D","CM","M"};
string ans="";
for(int i=12;i>=0;i--){
while(num-a[i]>=0){ // 只要num比当前值大则减去当前(已经保证最大)
ans +=s[i];
num=num-a[i];
}
}
return ans;
}
};
13. Roman to Integer
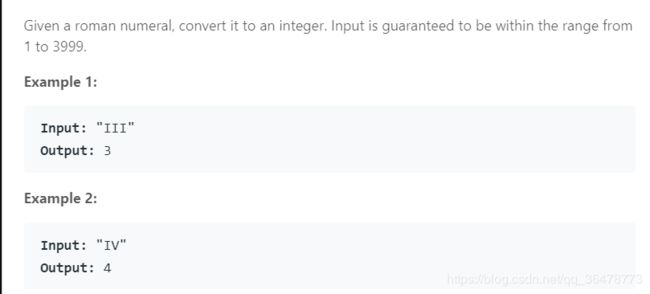
思路:与上一题一样,只不过这里是从后往前遍历字符串,若后面的字符比当前字符还小,则为减,否则为加。
14. Longest Common Prefix

思路:
- 暴力:两层for循环,第一层取出每个字符数组,第二层去比较每个字符数组的第j个字母是否相同。
- O(N)复杂度:先用
sort()对字符串数组排序,此时只需比较第一个字符串和最后一个字符串的公共前缀即可(其他已按照字典序排好序了)。
15. 3Sum

思路:
这里主要注意两个技巧:
- 先给数组排好序
- 跳过重复的数字
class Solution {
public:
vector> threeSum(vector& nums) {
sort(nums.begin(), nums.end()); // 先排好序
vector> res;
for ( int i=0; i0) && (nums[i]==nums[i-1]))
continue;
int l = i+1, r = nums.size()-1;
while (l0) r--; // 大了则往左靠
else if (s<0) l++; // 小则往右靠
else { // 等于0即已经找到
res.push_back(vector {nums[i], nums[l], nums[r]});
while (nums[l]==nums[l+1]) l++; //相等则直接跳过
while (nums[r]==nums[r-1]) r--;
l++; r--; // 左指针右移,右指针左移
}
}
}
return res;
}
};
17. Letter Combinations of a Phone Number

思路:
回溯法
递归形式:dfs(combination,next_digits),其中combination=combination+letter,即为dfs(combination + letter, next_digits[1:])
19. Remove Nth Node From End of List

注意:
- 此题最好用带头结点的单链表。
- 此处没有定义结构体符号,需要使用
struct 结构体名来表示。可以使用typedef struct ListNode {}或者在}加上ListNode
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
ListNode* s =(struct ListNode*)malloc(sizeof(struct ListNode)); // 申请空间
s->next=head;
head=s;
思路1: Two pass algorithm
删除倒数第i个结点,即为删除下标为length-i的结点。
两次循环,第一次循环记录下链表长度,第二次找到要删的结点。
思路2:One pass algorithm
双指针法,指针first从头结点开始往后查找,指针second始终保持和first相差n-1的单位差,当first指针到达末尾时,删除second指针对应结点即可。
21. Merge Two Sorted Lists

先说下数组从小到大排序的思路:
例数组a[]={1,2,4,5,6,7} b[]={2,4,5,8,9};
记数组a的指针i,数组b指针j,判断
if(a[i]>b[j])
j++;
else
i++;
再看单链表的做法(此处的难度就是单链表不能提前知道长度,且每次都需要判断p->next==NULL)
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
ListNode *dummy = new ListNode(0);
ListNode *cur = dummy;
while (l1 && l2) { //l1和l2非空
if (l1->val < l2->val) { // l1小一点
cur->next = l1;
l1 = l1->next;
} else {
cur->next = l2;
l2 = l2->next;
}
cur = cur->next; // 指针后移
}
if (l1) // l1非空
cur->next = l1;
else
cur->next = l2;
return dummy->next;
}
38. Count and Say
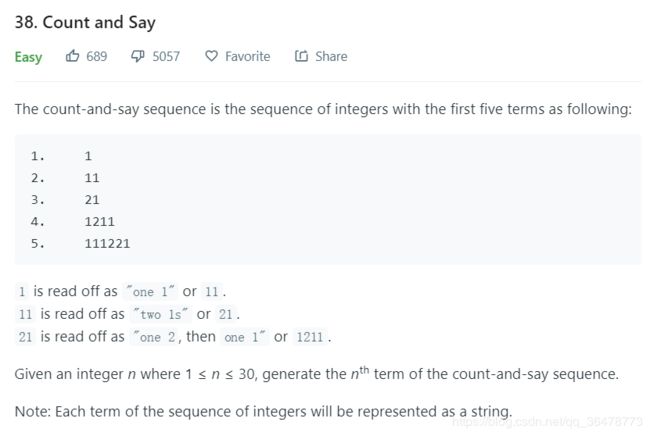
暴力破解:
class Solution {
public:
string countAndSay(int n) {
string str="1";
while(n>1){
//计算每次的结果
int len=str.size();
string s="";
for(int i=0;i<len;i++){
int num=getRepeatNum(str.at(i),str.substr(i)); // 计数当前字符连续出现个数
s=s+(char)(num+'0')+str[i];
i=i+num-1;
}
str=s;
n--;
}
return str;
}
int getRepeatNum(char x,string s){
int ct=1;
for(int i=0;i<s.size()-1;i++){
if(s[i]==s[i+1])
ct++;
else
break;
}
return ct;
}
};
递归版本:
注意控制递归的结果,由题意可知,可由f(n-1)——>f(n),故该递归是个自顶向下递归求解,且自底向上返回计算结果。
伪代码如下:
if 满足递归出口
return;
fun() // 自顶向下递归,遇到底层开始返回求解
do sth. // 计算
return result;
class Solution {
public:
string countAndSay(int n)
{
if(n==1) return "1";
string res,tmp = countAndSay(n-1); // recursion
char c= tmp[0]; // 第一个字符
int count=1;
for(int i=1;i39. Combination Sum

该题需要注意的是,在写的时候把按照习惯我把dfs函数设置成void类型,但函数需要return ans,故应该把数组设置为传引用的格式,即vector.
另外,该题为可以某样本可以无限拿取,递归函数的索引应为当前下标,即
dfs(i,target-candidates[i],ans,temp,candidates); // 下标为i而不是index
若为不可无限拿取,则索引改为i+1。
class Solution {
public:
vector> combinationSum(vector& candidates, int target) {
// 版本一 递归
vector> ans;
vector temp;
sort(candidates.begin(),candidates.end());
dfs(0,target,ans,temp,candidates); // 注意,需要传引用!!!
return ans;
}
void dfs(int index,int target,vector> &ans,vector temp,vector candidates){
if(target==0){
ans.push_back(temp);
}
if(target<0)
return ;
for(int i=index;i 40. Combination Sum II

此题与上题不一样的就是数组内部可以重复,但元素不可重复选取。上题已经讨论过,只需将dfs的索引改为i+1即可。
另外,题目的坑在于元素有重复,我们可以先试用sort()排序,之后剪枝判断,例如
int a[]= {1,1,2,3,4,7},此时递归时只需要计算第一个元素的结果,跳过重复的元素。
剪枝如下:
其中,i>index表示for循环刚经历一遍,此时i已经到达下一个元素,index仍然停留在起始位,也就是前一位, 单独使用candidates[i]==candidates[i-1] 会溢出。
if (i>index&&candidates[i]==candidates[i-1] ){
continue;
}
递归版本代码如下:
class Solution {
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
// 版本一 递归
vector<vector<int>> ans;
// set> ans;
vector<int> temp;
sort(candidates.begin(),candidates.end());
dfs(0,target,ans,temp,candidates); // 注意,需要传引用!!!
return ans;
}
void dfs(int index,int target,vector<vector<int>> &ans,vector<int> temp,vector<int> candidates){
if(target==0){
ans.push_back(temp);
}
if(target<0)
return ;
for(int i=index;i<candidates.size();i++){
if (i>index&&candidates[i]==candidates[i-1] ){
continue;
}
temp.push_back(candidates[i]);
dfs(i+1,target-candidates[i],ans,temp,candidates); // 下标为i而不是index
temp.pop_back();
}
}
};
46. Permutations

思路:
使用c++的库函数next_permutation(),注意需要先sort排序。
class Solution {
public:
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int>> ans;
sort(nums.begin(),nums.end());
ans.push_back(nums);
while(next_permutation(nums.begin(),nums.end())){
ans.push_back(nums);
}
return ans;
}
};
48. Rotate Image
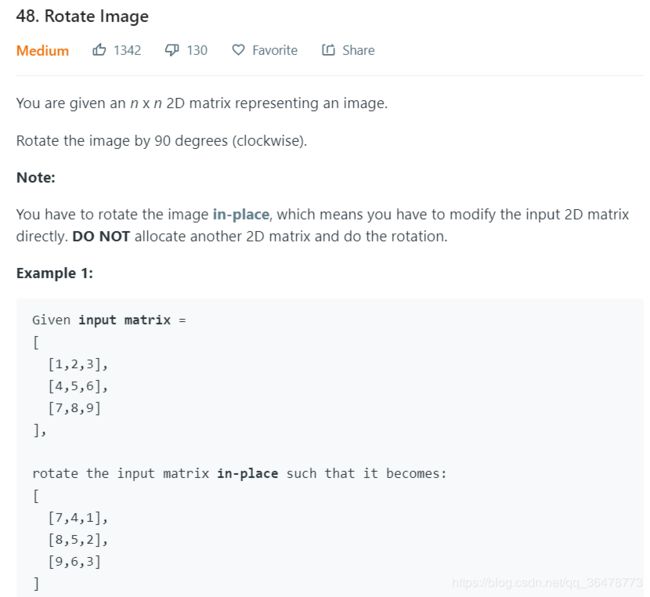
思路:
通用的方法:
- 顺时针
/*
* clockwise rotate
* first reverse up to down, then swap the symmetry
* 1 2 3 7 8 9 7 4 1
* 4 5 6 => 4 5 6 => 8 5 2
* 7 8 9 1 2 3 9 6 3
*/
void rotate(vector > &matrix) {
reverse(matrix.begin(), matrix.end());
for (int i = 0; i < matrix.size(); ++i) {
for (int j = i + 1; j < matrix[i].size(); ++j)
swap(matrix[i][j], matrix[j][i]);
}
}
- 逆时针
/*
* anticlockwise rotate
* first reverse left to right, then swap the symmetry
* 1 2 3 3 2 1 3 6 9
* 4 5 6 => 6 5 4 => 2 5 8
* 7 8 9 9 8 7 1 4 7
*/
void anti_rotate(vector<vector<int> > &matrix) {
for (auto vi : matrix) reverse(vi.begin(), vi.end());
for (int i = 0; i < matrix.size(); ++i) {
for (int j = i + 1; j < matrix[i].size(); ++j)
swap(matrix[i][j], matrix[j][i]);
}
}
49. Group Anagrams

思路:对每个字符串进行排序,使用map存下键值,例:"aet":{"eat","tea","ate"}.注意STL模板的使用。
另外,for auto循环可以起到迭代器的遍历效果。
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string>> mp;
for (string s : strs) {
string t = s;
sort(t.begin(), t.end());
mp[t].push_back(s);
}
vector<vector<string>> anagrams;
for (auto p : mp) {
anagrams.push_back(p.second);
}
return anagrams;
}
};