1.项目要求
文法要求:
(1)从文件读入,每条产生式占用一行
(2)文法为LL(1)文法
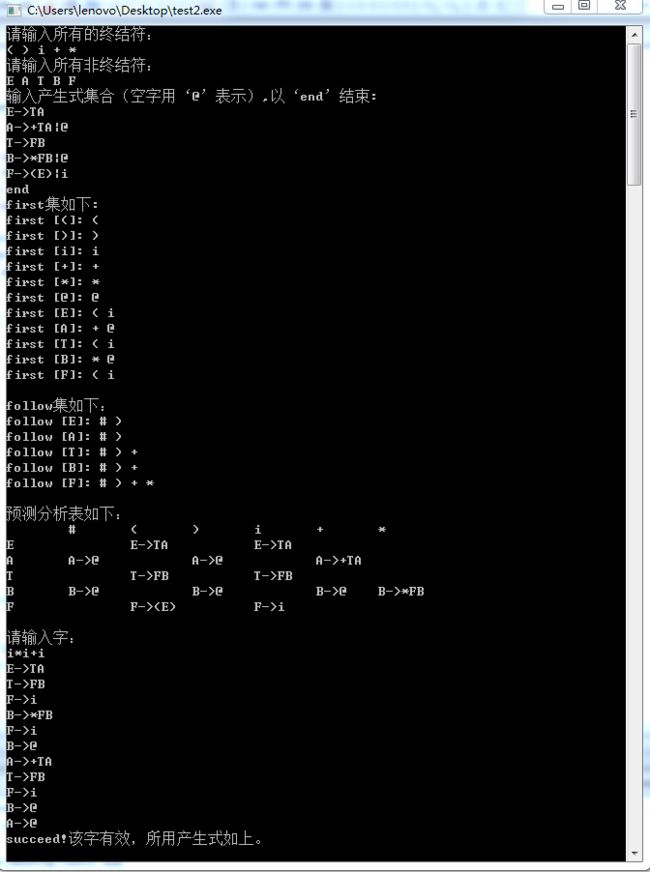
从文件中读入文法,从键盘上输入待分析的符号串,采用 LL(1)分析算法判断该符号串是否为该文法的句子。
2.实验思路:
首先实现集合FIRST(X)构造算法和集合FOLLOW(A)构造算法,再根据FIRST和FOLLOW集合构造出预测分析表,并对指定的句子打印出分析栈的分析过程,判断是否为该文法的句子。
3.实验原理
(1)first集的算法思想
如果产生式右部第一个字符为终结符,则将其计入左部first集
如果产生式右部第一个字符为非终结符执行以下步骤
求该非终结符的first集
将该非终结符的非$first集计入左部的first集
若存在$,则将指向产生式的指针右移
若不存在$,则停止遍历该产生式,进入下一个产生式
若已经到达产生式的最右部的非终结符,则将$加入左部的first集
处理数组中重复的first集中的终结符
(2)follow集的算法思想
对于文法G中每个非终结符A构造FOLLOW(A)的办法是,连续使用下面的规则,直到每个FOLLOW不在增大为止.
对于文法的开始符号S,置#于FOLLOW(S)中;
若A->aBb是一个产生式,则把FIRST(b)\{ε}加至FOLLOW(B)中;
若A->aB是一个产生式,或A->aBb是一个产生式而b=>ε(即ε∈FIRST(b))则把FOLLOW(A)加至FOLLOW(B)中
(3)生成预测分析表的算法思想
构造分析表M的算法是:
对文法G的每个产生式A->a执行第二步和第三步;
对每个终结符a∈FIRST(a),把A->a加至M[A,a]中;
若ε∈FIRST(a),则把任何b∈FOLLOW(A)把A->a加至M[A,b]中;
把所有无定义的M[A,a]标上出错标志.
(4)对符号串的分析过程
预测分析程序的总控程序在任何时候都是按STACK栈顶符号X和当前的输入符号行事的,对于任何(X,a),总控程序
每次都执行下述三种可能的动作之一;
若X=a=”#”,则宣布分析成功,停止分析过程.
若X=a≠”#”,则把X从STACK栈顶逐出,让a指向下一个输入符号.
若X是一个非终结符,则查看分析表M,若M[A,a]中存放着关于X的一个产生式,那么,首先把X逐出STACK栈顶,然后把产生式的右部符号串按反序一一推进STACK栈(若右部符号为ε,则意味着不推什么东西进栈).在把产生式的右部符号推进栈的同时应做这个产生式相应得语义动作,若M[A,a]中存放着”出错标志”,则调用出错诊察程序ERROR.
4.实验代码
#include
#include
#include
实验输入及程序运行输出结果: