Zookeeper分布式过程协同 (part II)
第一节忘记了?不要紧,传送门:死磕Zookeeper分布式过程协同
了解Zookeeper
Zookeeper基础
应⽤间需要共享⽤于协作的原语(具有原子性的一段代码),⽤于协作需求的服务的⽅法往往是:提供原语列表、暴露每个原语的实例化调⽤方法,以及控制这些实例。⽐如,可以说分布式锁机制组成了⼀个重要的原语,暴露出创建(create)、获取(acquire)和释放(release)三个调⽤⽅法。
这种设计存在⼀些缺陷:⾸先,要么预先提出⼀份详尽的原语列表,要么提供API的扩展,以便引⼊新的原语;其次,这种⽅式实现原语的服务使得应⽤丧失了灵活性。
ZooKeeper并不直接暴露原语, 取⽽代之,它暴露了由⼀⼩部分调⽤⽅法组成的类似⽂件系统的API,以便允许应⽤实现⾃⼰的原语。
通常使⽤菜谱(recipes)表⽰这些原语的实现。recipes包括ZooKeeper操作和维护⼀个⼩型的数据节点(znode),znode采⽤类似于⽂件系统的层级树状结构进⾏管理。
下图描述了znode树的结构,根节点包含4个⼦节点,其中三个⼦节点拥有下⼀级节点,其中叶⼦节点存储了数据信息。

针对⼀个znode,节点不包含数据往往隐含了重要的信息。⽐如,在主-从模式的中,主节点的znode没有数据,表⽰当前还没有选举出主节点。
图中涉及的⼀些其他znode节点在主-从模式的配置中⾮常有⽤:
·/workers 节点作为⽗节点,其下每个znode⼦节点保存了系统中⼀个可用从节点信息,它有⼀个从节点(foot.com:2181)。
·/tasks 节点作为⽗节点,其下每个znode⼦节点保存了所有已经创建并等待从节点执⾏的任务的信息,主-从模式的应用的客户端在/tasks下添加 ⼀个znode⼦节点,用来表示⼀个新任务,并等待任务状态的znode节点。
·/assign 节点作为⽗节点,其下每个znode⼦节点保存了分配到某个从节点的⼀个任务信息,当主节点为某个从节点分配了⼀个任务,就会在 /assign 下增加⼀个⼦节点。
API概述
如果⼀个znode节点包含任何数据,数据存储为字节数组(byte array)。字节数组的具体格式特定于每个应⽤的实现,ZooKeeper并不直接提供解析的⽀持。
ZooKeeper的API暴露了以下⽅法:
create/path data 创建⼀个名为/path的znode节点,并包含数据data。
delete/path 删除名为/path的znode。
exists/path 检查是否存在名为/path的节点。
setData/path data 设置名为/path的znode的数据为data。
getData/path 返回名为/path节点的数据信息。
getChildren/path 返回所有/path节点的所有⼦节点列表。
【注意】ZooKeeper并不允许局部写⼊或读取znode节点的数据。当设置znode节点的数据或读取时,znode节点的内容会被整个替换或全部读取进来。
ZooKeeper客户端连接到ZooKeeper服务,通过API调⽤来建⽴会话(session)。
znode的不同类型
新建znode,需要指定该节点的类型(mode),不同类型决定了znode节点不同的⾏为⽅式。
持久节点和临时节点
znode节点可以是持久节点(persistent),或是临时节点(ephemeral)。持久的节点只能通过调⽤delete来进⾏删除(如 /path)。临时的 znode相反,当创建该节点的客户端崩溃或关闭了与ZooKeeper的连接时,节点就会被删除。
持久znode节点很重要,通过持久类型的znode节点为应⽤保存数据,即使znode节点的创建者不再属于应⽤系统,数据也可以保存下来⽽不丢失。例如,在主-从模式例⼦中,即使分配任务的主节点已经崩溃了,从节点可以依然保存任务的分配情况。
临时znode节点传达应⽤某些⽅⾯的信息,当创建者的会话有效时,这些信息需有效保存。例如,在主-从模式的例⼦中,当主节点创建的znode节点为临时节点,该节点的存在意味着现在有⼀个主节点,且主节点状态处于正常运⾏。如果主节点消失后,该znode节点仍然存在,那么系统将⽆法监测到主节点崩溃。这样就可以阻⽌系统继续进⾏,这个znode节点和主节点⼀起消失。我们也在从节点中使⽤临时的znode,如果⼀个从节点失效,那么会话将会过期,之后 znode/workers 也将⾃动消失。
⼀个临时znode,在以下两种情况下将会被删除:
1.当创建该znode节点的客户端的会话因超时或主动关闭中⽌。
2.当某个客户端(不⼀定是创建者)主动删除该节点。
临时的znode节点在其创建者的会话过期时会被删除,所以不允许临时节点拥有⼦节点。
有序节点
znode节点可以设置为有序节点(sequential)。⼀个唯一的单调递增的整数分配给有序的znode节点。当创建有序节点时,⼀个序号会被追加到路径之后。例如,如果⼀个客户端创建了⼀个有序znode节点,其路径为 /tasks/task- ,ZooKeeper会分配⼀个序号(如1),并将这个数字追加到路径后,即该znode节点为 /tasks/task-1 。通过创建具有唯一名称的znode节点实现了znode节点的有序,直观地查看znode的创建顺序。
监视与通知
当以远程服务的⽅式访问ZooKeeper,每次访问znode节点时,客户端都需要获得节点中的内容,这样做的代价⾮常⼤,导致更⾼的延迟。并且ZooKeeper需要做更多的操作。
考虑下图中的例⼦,常见的轮询问题:第⼆次调⽤ getChildren/tasks 返回了相同的值(空的集合)。
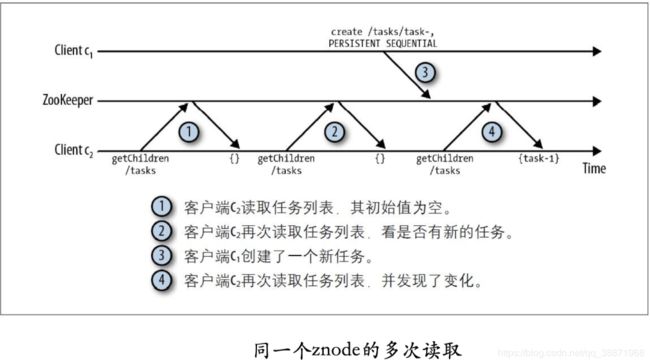
为了替换客户端的轮询,选择基于通知(notification)的机制:客户端向ZooKeeper注册需要设置接收通知的znode节点,通过对znode节点设置监视点(watch)来接收通知。监视点是⼀个单次触发的操作,即监视点会触发⼀个通知。为了接收多个通知,客户端必须在每次通知后设置⼀个新的监视点。
下图增加了监视点的情况下,当节点 /tasks 发⽣变化时,客户端会收到⼀个通知,并从ZooKeeper读取⼀个新值。
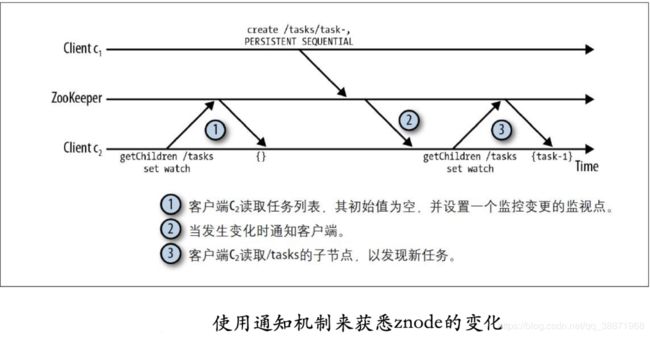
因为通知机制是单次触发,所以客户端接收⼀个znode节点的变更通知并设置新的监视点(watch)时, znode节点可能会有变化(不要担⼼,不会错过状态的变化)。
看⼀个例⼦来说明它到底是怎么⼯作的。假设事件按以下顺序发⽣:
1.客户端c1 设置监视点来监控 /tasks 数据的变化。
2.客户端c2 连接后,向 /tasks 中添加了⼀个新的任务。
3.客户端c1 接收通知。
4.客户端c1 设置新的监视点,在设置完成前,第三个客户端c3连接后,向/tasks中添加了⼀个新的任务。
客户端c1设置了新的监视点,但由于c3添加数据的变更并没有触发对c1的通知。为了观察这个变更,在设置新的监视点前,c1实际上需要读取节点 /tasks 的状态,通过在设置监视点前读取ZooKeeper的状态。这样,c1就不会错过任何变更。
通知机制的⼀个重要保障是,对同⼀个znode的操作,先向客户端传送通知,然后再对该节点进⾏变更。如果客户端对⼀个znode设置了监视点, ⽽该znode发⽣了两个连续更新。第⼀次更新后,客户端在观察第⼆次变化前就接收到了通知,然后读取znode中的数据。
通知机制阻⽌了客户端所观察的更新顺序,虽然ZooKeeper的状态变化传递给某些客户端时更慢,但需要保障客户端以全局的顺序来观察ZooKeeper的状态。
ZooKeeper可以定义不同类型的通知,依赖于设置监视点对应的通知类型。客户端可以设置多种监视点,如监控znode的数据变化、监控znode⼦节点的变化、监控znode的创建或删除。为了设置监视点,可以使⽤任何API中的调⽤来读取ZooKeeper的状态,在调⽤这些API时,传⼊⼀个 watcher对象或使⽤默认的watcher。
znode版本
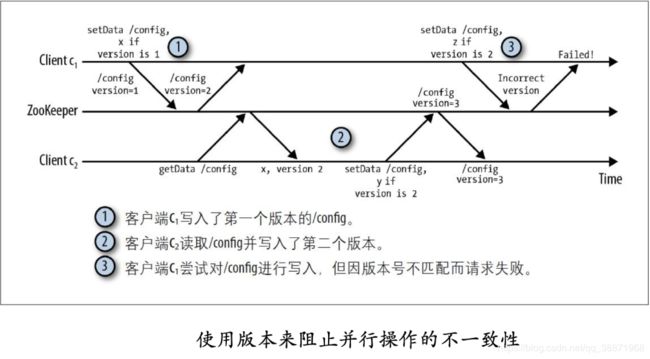
每⼀个znode都有版本号,它随着每次数据变化⽽⾃增。两个API操作可以有条件地执⾏:setData和delete。这两个调⽤以版本号作为转⼊参数,只有当转⼊参数的版本号与服务器上的版本号⼀致时调⽤才会成功。 当多个ZooKeeper客户端对同⼀个znode进⾏操作时,版本的使⽤就会显得尤为重要。
例如,假设客户端c1对 znode/config 写⼊了⼀些配置信息,如果另⼀个客户端c2同时更新了这个znode,此时c1的版本号已经过期,c1调⽤ setData ⼀定不会成功。
使⽤版本机制有效避免了以上情况。在这个例⼦中,c1在写⼊数据时使⽤的版本⽆法匹配,使得操作失败,下图描述了这个情况。
Zookeeper架构
应⽤通过客户端库来对ZooKeeper实现了调⽤;客户端库负责与ZooKeeper服务器端进⾏交互。
下图展⽰了客户端与服务器端之间的关系。每⼀个客户端导⼊客户端库,之后便可以与任何ZooKeeper的节点进⾏通信。
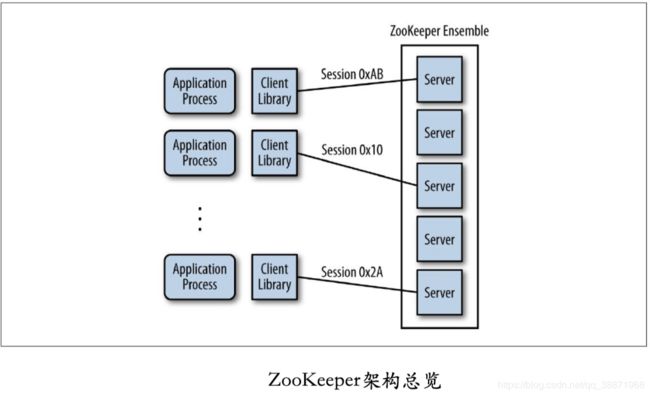
ZooKeeper服务器端运⾏于两种模式下:独⽴模式(standalone)和仲裁模式(quorum)。
独⽴模式⼏乎与其术语所描述的⼀样:有⼀个单独的服务器,ZooKeeper状态⽆法复制。
仲裁模式下,包含⼀组ZooKeeper服务器,称为ZooKeeper集合(ZooKeeper ensemble),它们之间可以进⾏状态的复制,并同时服务于客户端的请求。从这个角度出发,使⽤术语“ZooKeeper集合”来表⽰⼀个服务器设施,这⼀设施可以由独⽴模式的⼀个服务器组成,也可以仲裁模式下的多个服务器组成。
ZooKeeper仲裁
仲裁模式下,ZooKeeper会复制集群中的所有服务器的数据树。但如果让客户端等待每个服务器完成数据保存后才能继续,会产生严重的延迟问题。在公共管理领域,法定⼈数是指进⾏⼀项投票所需的⽴法者的最⼩数量。⽽在ZooKeeper中,则是指为了使ZooKeeper⼯作必须有效运⾏的服务器的最⼩数量。这个数字也是服务器告知客户端安全保存数据前,需要保存客户端数据的服务器的最⼩个数。例如,我们⼀共有5个ZooKeeper服务器,但法定数为3个,这样,只要任何3个服务器保存了数据,客户端就可以继续,⽽其他两个服务器最终也将捕获到数据,并保存数据。
选择法定数准确的⼤⼩是⼀个⾮常重要的事。法定的数量需要保证不管系统发⽣延迟或崩溃,服务主动确认的任何更新请求需要保持下去,直到另⼀个请求代替它。
为了明⽩这到底是什么意思,让我们先来通过⼀个例⼦来看看,如果法定⼈数太⼩,会如何出错。假设有5个服务器并设置法定⼈数为2,现在服务器s1和s2确认它们需要对⼀个请求创建的 znode/z 进⾏复制,服务再返回客户端,指出znode创建完成。现在假设在复制新的znode到其他服务器之前,服务器s1和s2 与其他服务器和客户端发⽣了长时间的分区隔离,整个服务的状态仍然正常,因为基于我们的假设设定法定⼈数为2,⽽现在还有 3个服务器,但这3个服务器将⽆法发现新的znode/z。因此,对创建节点 /z 的请求是⾮持久化的。
这就是第1章中讲述的脑裂场景的例⼦。为了避免这个问题,这个例⼦中,法定⼈数的⼤⼩必须⾄少为3,即集合中5个服务器的多数原则。为了能正常⼯作,集合中⾄少要有3个有效的服务器。为了确认⼀个请求对状态的更新是否成功完成,这个集合同时需要⾄少3个服务器确认已经完成了数 据的复制操作。因此,如果要保证集合可以正常⼯作,对任何更新操作的 成功完成,⾄少要有1个有效的服务器来保存更新的副本(即⾄少在⼀ 个节点上合理的法定⼈数存在交集)。
通过使⽤多数⽅案,我们就可以容许f个服务器的崩溃,在这⾥,f为⼩于集合中服务器数量的⼀半。例如,如果有5个服务器,可以容许最多f=2个崩溃。在集合中,服务器的个数并不是必须为奇数,只是使⽤偶数会使得系统更加脆弱。假设在集合中使⽤4个服务器,那么多数原则对应的数 量为3个服务器。然⽽,这个系统仅能容许1个服务器崩溃,因为两个服务 器崩溃就会导致系统失去多数原则的状态。因此,在4个服务器的情况下, 我们仅能容许⼀个服务器崩溃,⽽法定⼈数现在却更⼤,这意味着对每个 请求,我们需要更多的确认操作。底线是我们需要争取奇数个服务器。
同时允许法定数不同于多数原则。
会话
在对ZooKeeper集合执⾏任何请求前,⼀个客户端必须先与服务建⽴会 话。会话的概念⾮常重要,对ZooKeeper的运⾏也⾮常关键。客户端提交给 ZooKeeper的所有操作均关联在⼀个会话上。当⼀个会话因某种原因⽽中⽌ 时,在这个会话期间创建的临时节点将会消失。
当客户端通过某⼀个特定语⾔套件来创建⼀个ZooKeeper句柄时,它就 会通过服务建⽴⼀个会话。客户端初始连接到集合中某⼀个服务器或⼀个 独⽴的服务器。客户端通过TCP协议与服务器进⾏连接并通信,但当会话 ⽆法与当前连接的服务器继续通信时,会话就可能转移到另⼀个服务器 上。ZooKeeper客户端库透明地转移⼀个会话到不同的服务器。
会话提供了顺序保障,这就意味着同⼀个会话中的请求会以FIFO(先 进先出)顺序执⾏。通常,⼀个客户端只打开⼀个会话,因此客户端请求将全部以FIFO顺序执⾏。如果客户端拥有多个并发的会话,FIFO顺序在多 个会话之间未必能够保持。⽽即使⼀个客户端中连贯的会话并不重叠,也 未必能够保证FIFO顺序。下⾯的情况说明如何发⽣这种问题:
1。客户端建立了⼀个会话,并通过两个连续的异步调用来创建/tasks 和/workers。
2。第⼀个会话过期。
3。客户端创建另⼀个会话,并通过异步调用创建/assign。 在这个调⽤顺序中,可能只有/tasks和/assign成功创建了,因为第⼀个 会话保持了FIFO顺序,但在跨会话时就违反了FIFO顺序。