Spark Core 核心知识--RDD
目录
1、Spark核心功能
1.1 SparkContext
1.2 存储体系
1.3 计算引擎
1.4 部署模式
2、Spark扩展功能
2.1 Spark
2.2 Spark Streaming
2.3 Spark Graphx
2.4 Spark MLlib
3、Spark核心概念
4、Spark 基本架构
5、Spark 编程模型
6、RDD
6.1、RDD 概述
6.1.1、什么是 RDD
6.1.2、RDD 的属性
6.2、创建 RDD
6.3、RDD 的编程 API
6.3.1、Transformation
6.3.3、WordCount 中的 RDD
6.4、RDD 的依赖关系
6.4.1、窄依赖和宽依赖对比
6.4.2、窄依赖和宽依赖总结
6.4.3、Lineage
6.5、DAG 生成
6.6、RDD 缓存
6.6.1、RDD 的缓存方式
7.1、Broadcast Variables(广播变量)
7.1.1、为什么要定义广播变量
7.1.2、如何定义和还原一个广播变量
7.1.3、注意事项
7.2、Accumulators(累加器)
7.2.1、为什么要定义累加器
7.2.2、图解累加器
7.2.3、如果定义和还原一个累加器
7.2.4、注意事项
1、Spark核心功能

Spark Core 提供 Spark 最基础的最核心的功能,主要包括:
1.1 SparkContext
通常而言,DriverApplication 的执行与输出都是通过 SparkContext 来完成的,在正式提交 Application 之前,首先需要初始化 SparkContext。SparkContext 隐藏了网络通信、分布式 部署、消息通信、存储能力、计算能力、缓存、测量系统、文件服务、Web 服务等内容, 应用程序开发者只需要使用 SparkContext 提供的 API 完成功能开发。 SparkContext 内置的 DAGScheduler 负责创建 Job,将 DAG 中的 RDD 划分到不同的 Stage, 提交 Stage 等功能。 SparkContext 内置的 TaskScheduler 负责资源的申请、任务的提交及请求集群对任务的调度 等工作。
1.2 存储体系
Spark 优先考虑使用各节点的内存作为存储,当内存不足时才会考虑使用磁盘,这极大地 减少了磁盘 I/O,提升了任务执行的效率,使得 Spark 适用于实时计算、流式计算等场景。 此外,Spark 还提供了以内存为中心的高容错的分布式文件系统 Tachyon 供用户进行选择。 Tachyon 能够为 Spark 提供可靠的内存级的文件共享服务。
1.3 计算引擎
计算引擎由 SparkContext 中的 DAGScheduler、RDD 以及具体节点上的 Executor 负责执行 的 Map 和 Reduce 任务组成。DAGScheduler 和 RDD 虽然位于 SparkContext 内部,但是在 任务正式提交与执行之前将 Job 中的 RDD 组织成有向无关图(简称 DAG)、并对 Stage 进 行划分决定了任务执行阶段任务的数量、迭代计算、shuffle 等过程。
1.4 部署模式
由于单节点不足以提供足够的存储及计算能力,所以作为大数据处理的 Spark 在SparkContext 的 TaskScheduler 组件中提供了对 Standalone 部署模式的实现和 YARN、Mesos 等分布式资源管理系统的支持。通过使用 Standalone、YARN、Mesos、kubernetes、Cloud 等部署模式为 Task 分配计算资源,提高任务的并发执行效率。除了可用于实际生产环境 的 Standalone、YARN、Mesos、kubernetes、Cloud 等部署模式外,Spark 还提供了 Local 模式和 local-cluster 模式便于开发和调试。
2、Spark扩展功能
为了扩大应用范围,Spark 陆续增加了一些扩展功能,主要包括:
2.1 Spark
SQL 由于 SQL 具有普及率高、学习成本低等特点,为了扩大 Spark 的应用面,因此增加了对 SQL 及 Hive 的支持。Spark SQL 的过程可以总结为:首先使用 SQL 语句解析器(SqlParser) 将 SQL 转换为语法树(Tree),并且使用规则执行器(RuleExecutor)将一系列规则(Rule) 应用到语法树,最终生成物理执行计划并执行的过程。其中,规则包括语法分析器 (Analyzer)和优化器(Optimizer)。 Hive 的执行过程与 SQL 类似。
2.2Spark Streaming
2.2 Spark Streaming
Spark Streaming与Apache Storm类似,也用于流式计算。Spark Streaming支持Kafka、Flume、 Twitter、MQTT、ZeroMQ、Kinesis 和简单的 TCP 套接字等多种数据输入源。输入流接收器 (Receiver)负责接入数据,是接入数据流的接口规范。Dstream 是 Spark Streaming 中所 有数据流的抽象,Dstream 可以被组织为 DStreamGraph。Dstream 本质上由一系列连续的 RDD 组成。
2.3 Spark Graphx
Spark 提 供 的 分 布 式 图 计 算 框 架 。 GraphX 主 要 遵 循 整 体 同 步 并 行 计 算 模 式 (BulkSynchronous Parallell,简称 BSP)下的 Pregel 模型实现。GraphX 提供了对图的抽象 Graph,Graph 由顶点(Vertex)、边(Edge)及继承了 Edge 的 EdgeTriplet(添加了 srcAttr 和 dstAttr 用来保存源顶点和目的顶点的属性)三种结构组成。GraphX 目前已经封装了最 短路径、网页排名、连接组件、三角关系统计等算法的实现,用户可以选择使用。
2.4 Spark MLlib
Spark 提供的机器学习框架。机器学习是一门涉及概率论、统计学、逼近论、凸分析、算 法复杂度理论等多领域的交叉学科。MLlib 目前已经提供了基础统计、分类、回归、决策 树、随机森林、朴素贝叶斯、保序回归、协同过滤、聚类、维数缩减、特征提取与转型、 频繁模式挖掘、预言模型标记语言、管道等多种数理统计、概率论、数据挖掘方面的数 学算法。
3、Spark核心概念

4、Spark 基本架构
从集群部署的角度来看,Spark 集群由以下部分组成:
Cluster Manager:Spark 的集群管理器,主要负责资源的分配与管理。集群管理器分配的资 源属于一级分配,它将各个 Worker 上的内存、CPU 等资源分配给应用程序,但是并不负责 对 Executor 的资源分配。目前,Standalone、YARN、Mesos、K8S,EC2 等都可以作为 Spark 的集群管理器。
Master:Spark 集群的主节点。
Worker:Spark 集群的工作节点。对 Spark 应用程序来说,由集群管理器分配得到资源的 Worker 节点主要负责以下工作:创建 Executor,将资源和任务进一步分配给 Executor,同步 资源信息给 Cluster Manager。
Executor:执行计算任务的一些进程。主要负责任务的执行以及与 Worker、Driver Application 的信息同步。

Driver Appication:客户端驱动程序,也可以理解为客户端应用程序,用于将任务程序转换 为 RDD 和 DAG,并与 Cluster Manager 进行通信与调度。
这些组成部分之间的整体关系如下图所示:

Spark 计算平台有两个重要角色,Driver 和executor,不论是 StandAlone 模式还是YARN 模式, 都是 Driver 充当 Application 的 master 角色,负责任务执行计划生成和任务分发及调度; executor 充当 worker 角色,负责实际执行任务的 task,计算的结果返回 Driver。
5、Spark 编程模型
Spark 应用程序从编写到提交、执行、输出的整个过程如下图所示:
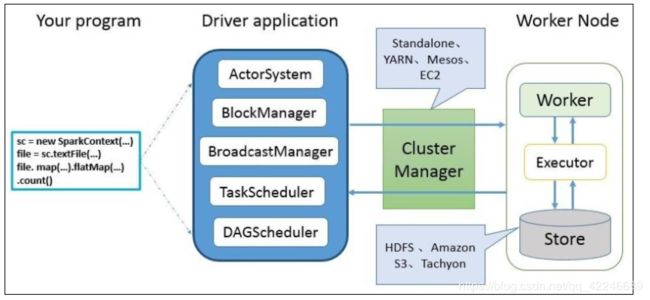
图中描述的步骤如下:
1、用户使用 SparkContext 提供的 API(常用的有 textFile、sequenceFile、runJob、stop 等) 编写Driver Application程序。此外SQLContext、HiveContext及StreamingContext对SparkContext 进行封装,并提供了 SQL、Hive 及流式计算相关的 API。
2、使用 SparkContext 提交的用户应用程序,首先会使用 BlockManager 和 BroadcastManager 将任务的 Hadoop 配置进行广播。然后由 DAGScheduler 将任务转换为 RDD 并组织成 DAG, DAG 还将被划分为不同的 Stage。最后由 TaskScheduler 借助 ActorSystem 将任务提交给集群 管理器(ClusterManager)。
3、集群管理器(ClusterManager)给任务分配资源,即将具体任务分配到 Worker 上,Worker 创建 Executor 来处理任务的运行。Standalone、YARN、Mesos、kubernetes、EC2 等都可以作 为 Spark 的集群管理器。
计算模型:

RDD 可以看做是对各种数据计算模型的统一抽象,Spark 的计算过程主要是 RDD 的迭代计算 过程,如上图。RDD 的迭代计算过程非常类似于管道。分区数量取决于 partition 数量的设 定,每个分区的数据只会在一个 Task 中计算。所有分区可以在多个机器节点的 Executor 上 并行执行。
6、RDD
6.1、RDD 概述
6.1.1、什么是 RDD
RDD(Resilient Distributed Dataset)叫做分布式数据集,是 Spark 中最基本的数据抽象,它 代表一个不可变、可分区、里面的元素可并行计算的集合。RDD 具有数据流模型的特点: 自动容错、位置感知性调度和可伸缩性。RDD 允许用户在执行多个查询时显式地将工作集缓 存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
可以从三个方面来理解:
1、数据集 DataSet:故名思议,RDD 是数据集合的抽象,是复杂物理介质上存在数据的一 种逻辑视图。从外部来看,RDD 的确可以被看待成经过封装,带扩展特性(如容错性)的数 据集合。
2、分布式 Distributed:RDD 的数据可能在物理上存储在多个节点的磁盘或内存中,也就是 所谓的多级存储。
3、弹性 Resilient:虽然 RDD 内部存储的数据是只读的,但是,我们可以去修改(例如通 过 repartition 转换操作)并行计算计算单元的划分结构,也就是分区的数量。
你将 RDD 理解为一个大的集合,将所有数据都加载到内存中,方便进行多次重用。第一, 它是分布式的,可以分布在多台机器上,进行计算。第二,它是弹性的,我认为它的弹性体 现在每个 RDD 都可以保存内存中,如果某个阶段的 RDD 丢失,不需要从头计算,只需要提 取上一个 RDD,再做相应的计算就可以了
6.1.2、RDD 的属性
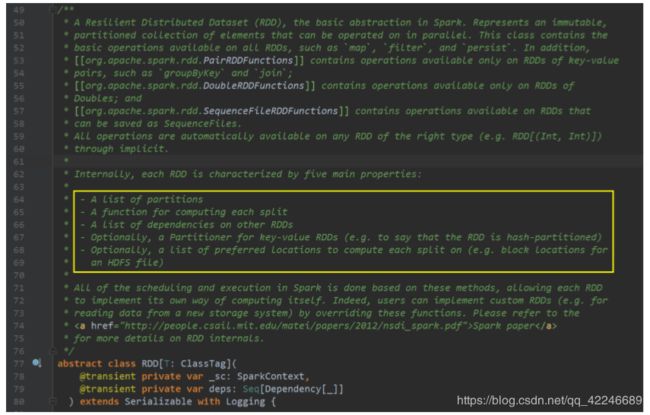
1、A list of partitions:一组分片(Partition),即数据集的基本组成单位

2、A function for computing each split:一个计算每个分区的函数,也就是算子

3、A list of dependencies on other RDDs:RDD 之间的依赖关系:宽依赖和窄依赖 RDD 的每次转换都会生成一个新的 RDD,所以 RDD 之间就会形成类似于流水线一样的前后 依赖关系。在部分分区数据丢失时,Spark 可以通过这个依赖关系重新计算丢失的分区数据, 而不是对 RDD 的所有分区进行重新计算。

产生的子 RDD 分区与父 RDD 分区之间是多对多的关系。
2、部分依赖:父 RDD 的一个 partition 中的部分数据与 RDD x 的一个 partition 相关,而另一 部分数据与 RDD x 中的另一个 partition 有关。 例如,groupByKey 操作产生的 ShuffledRDD 中的每个分区依赖于父 RDD 的所有分区中的部分 元素。
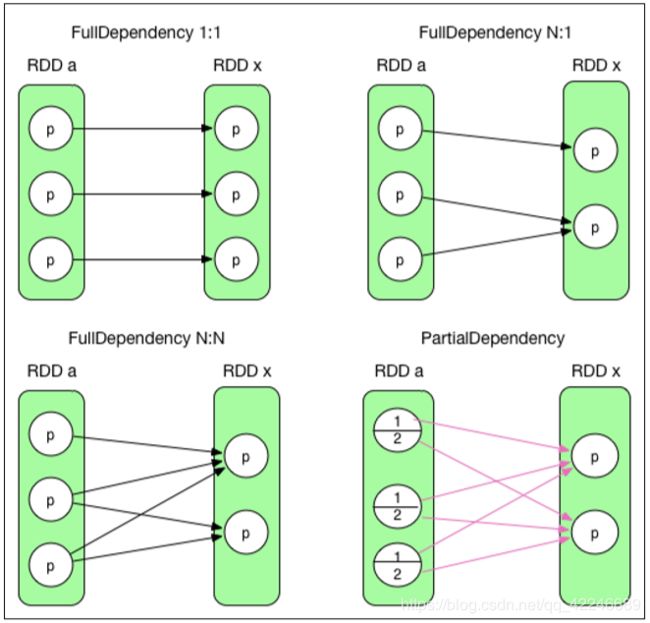
在 Spark 中,完全依赖是 NarrowDependency(黑色箭头),部分依赖是 ShuffleDependency ( 红 色 箭 头 ),而 NarrowDependency 又 可 以 细 分 为 [1:1]OneToOneDependency 、 [N:1]NarrowDependency 和[N:N]NarrowDependency,还有特殊的 RangeDependency (只在 UnionRDD 中使用)。
需要注意的是,对于[N:N]NarrowDependency很少见,最后生成的依赖图和ShuffleDependency 没什么两样。只是对于父 RDD 来说,有一部分是完全依赖,有一部分是部分依赖。所以也 只有[1:1]OneToOneDependency 和[N:1]NarrowDependency 两种情况。
4、Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned): 一个 Partitioner,即 RDD 的分片函数。 当前 Spark 中实现了两种类型的分片函数,一个是基于哈希的 HashPartitioner,另外一个是 基于范围的 RangePartitioner。只有对于于 key-value 的 RDD,才会有 Partitioner,非 key-value的 RDD 的 Parititioner 的值是 None。Partitioner 函数不但决定了 RDD 本身的分片数量,也决 定了 parent RDD Shuffle 输出时的分片数量。

6.2、创建 RDD
创建 RDD 主要有两种方式:官网解释 There are two ways to create RDDs: parallelizing an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, or any data source offering a Hadoop InputFormat.
1、由一个已经存在的 Scala 数据集合创建 val rdd = sc.parallelize(Array(1,2,3,4,5,6,7,8)) val rdd = sc.makeRDD(Array(1,2,3,4,5,6,7,8))
2、由外部存储系统的数据集创建,包括本地的文件系统,还有所有 Hadoop 支持的数据集, 比如 HDFS、Cassandra、HBase 等 val rdd = sc.textFile("hdfs://myha01/spark/wc/input/words.txt")
3、扩展 从 HBase 当中读取 从 ElasticSearch 中读取
6.3、RDD 的编程 API
官网: http://spark.apache.org/docs/latest/rdd-programming-guide.html#resilient-distributed-datasetsrdds
6.3.1、Transformation
官网:http://spark.apache.org/docs/latest/rdd-programming-guide.html#transformations
RDD 中的所有转换(Transformation)都是延迟加载的,也就是说,它们并不会直接计算结 果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当 发生一个要求返回结果给 Driver 的动作时,这些转换才会真正运行。这种设计让 Spark 更加 有效率地运行。
常用的 Transformation:
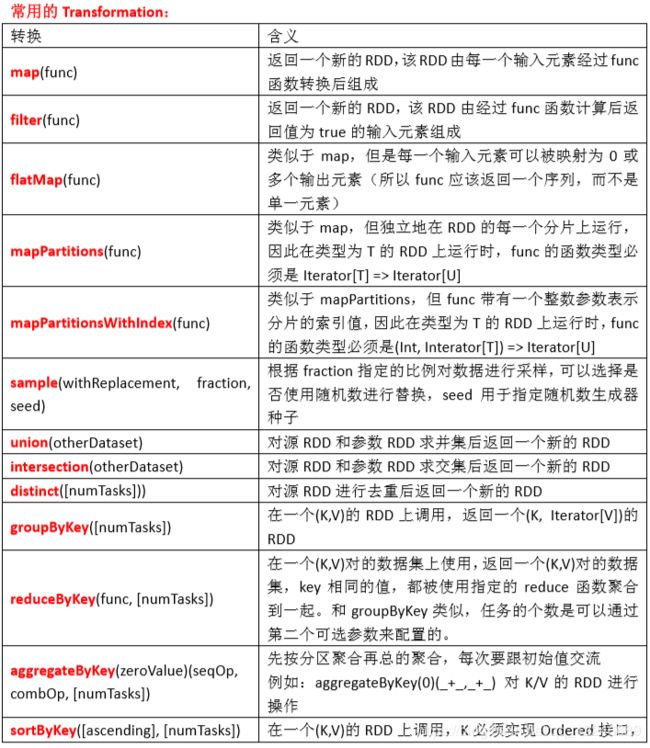

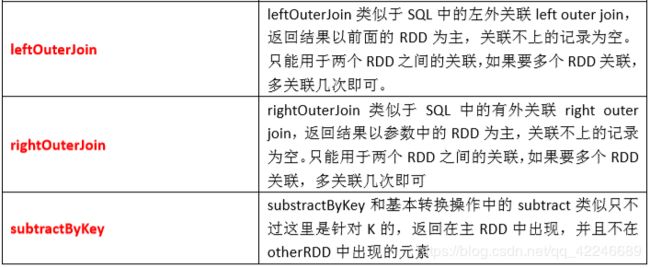
总结: Transformation 返回值还是一个 RDD。它使用了链式调用的设计模式,对一个 RDD 进行计 算后,变换成另外一个 RDD,然后这个 RDD 又可以进行另外一次转换。这个过程是分布式 的
6.3.2、Action
官网:http://spark.apache.org/docs/latest/rdd-programming-guide.html#actions
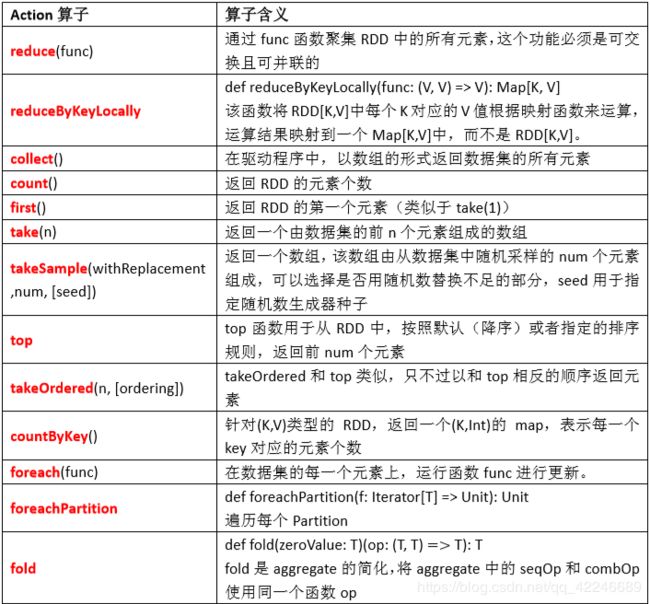

总结: Action 返回值不是一个 RDD。它要么是一个 Scala 的普通集合,要么是一个值,要么是空, 最终或返回到 Driver 程序,或把 RDD 写入到文件系统中
6.3.3、WordCount 中的 RDD
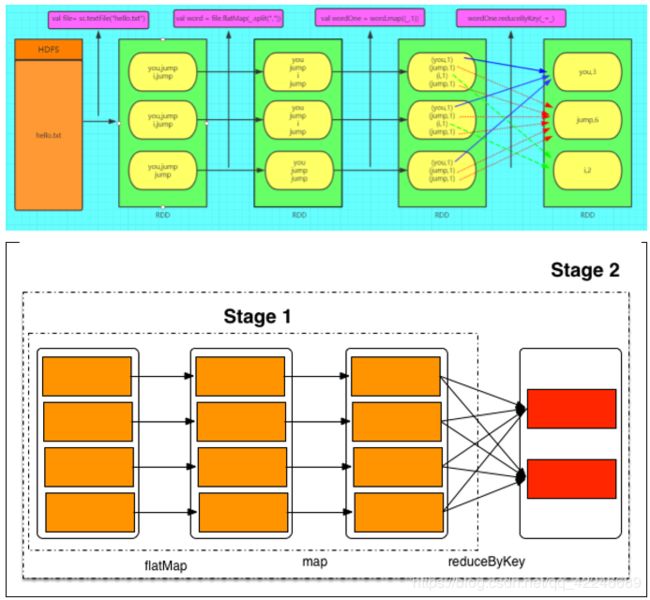
那么问题来了,请问在下面这一句标准的 wordcount 中到底产生了几个 RDD 呢??? sc.textFile("hdfs://myha01/wc/input/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
6.4、RDD 的依赖关系
RDD 和它依赖的父 RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和 宽依赖(wide dependency)

6.4.1、窄依赖和宽依赖对比
窄依赖指的是每一个父 RDD 的 Partition 最多被子 RDD 的一个 Partition 使用 总结:窄依赖我们形象的比喻为独生子女,窄依赖的函数有:map, filter, union, join(父 RDD 是 hash-partitioned ), mapPartitions, mapValues
宽依赖指的是多个子 RDD 的 Partition 会依赖同一个父 RDD 的 Partition 总结:窄依赖我们形象的比喻为超生,宽依赖的函数有:groupByKey、partitionBy、reduceByKey、 sortByKey、join(父 RDD 不是 hash-partitioned )
6.4.2、窄依赖和宽依赖总结
在这里我们是从父 RDD 的 partition 被使用的个数来定义窄依赖和宽依赖,因此可以用一句 话概括下:如果父 RDD 的一个 Partition 被子 RDD 的一个 Partition 所使用就是窄依赖,否则 的话就是宽依赖。因为是确定的 partition 数量的依赖关系,所以 RDD 之间的依赖关系就是 窄依赖;由此我们可以得出一个推论:即窄依赖不仅包含一对一的窄依赖,还包含一对固定 个数的窄依赖。
一对固定个数的窄依赖的理解:即子 RDD 的 partition 对父 RDD 依赖的 Partition 的数量不会 随着 RDD 数据规模的改变而改变;换句话说,无论是有 100T 的数据量还是 1P 的数据量, 在窄依赖中,子 RDD 所依赖的父 RDD 的 partition 的个数是确定的,而宽依赖是 shuffle 级别 的,数据量越大,那么子 RDD 所依赖的父 RDD 的个数就越多,从而子 RDD 所依赖的父 RDD 的 partition 的个数也会变得越来越多。
6.4.3、Lineage
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(即 血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行 为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据 分区。
6.5、DAG 生成
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就就形成了DAG, 根据 RDD 之间的依赖关系的不同将 DAG 划分成不同的 Stage,对于窄依赖,partition 的转换 处理在 Stage 中完成计算。对于宽依赖,由于有 Shuffle 的存在,只能在 parent RDD 处理完 成后,才能开始接下来的计算,因此宽依赖是划分 Stage 的依据。
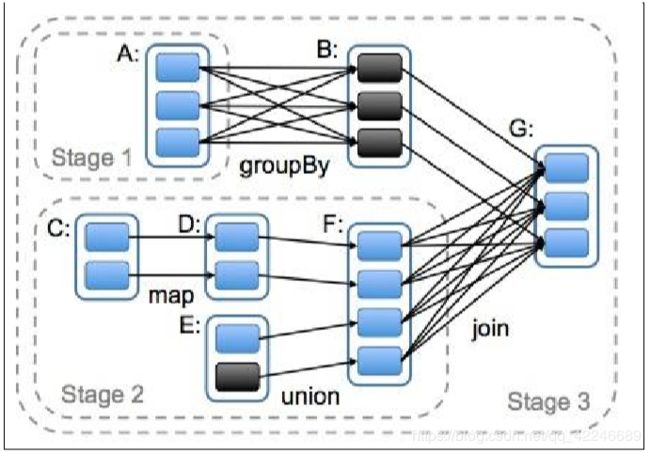
在 spark 中,会根据 RDD 之间的依赖关系将 DAG 图(有向无环图)划分为不同的阶段,对 于窄依赖,由于 partition 依赖关系的确定性,partition 的转换处理就可以在同一个线程里完 成,窄依赖就被 spark 划分到同一个 stage 中,而对于宽依赖,只能等父 RDD shuffle 处理完 成后,下一个 stage 才能开始接下来的计算。
因此 spark 划分 stage 的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个 stage; 遇到窄依赖就将这个 RDD 加入该 stage 中。因此在上图中 RDD C,RDD D,RDD E,RDD F 被 构建在一个 stage 中,RDD A 被构建在一个单独的 Stage 中,而 RDD B 和 RDD G 又被构建在 同一个 stage 中。
在 spark 中,Task 的类型分为 2 种:ShuffleMapTask 和 ResultTask
简单来说,DAG 的最后一个阶段会为每个结果的 partition 生成一个 ResultTask,即每个 Stage 里面的 Task 的数量是由该 Stage 中最后一个 RDD 的 Partition 的数量所决定的!而其余所有 阶段都会生成 ShuffleMapTask;之所以称之为 ShuffleMapTask 是因为它需要将自己的计算结 果通过 shuffle 到下一个 stage 中;也就是说上图中的 stage1 和 stage2 相当于 MapReduce 中 的 Mapper,而 ResultTask 所代表的 stage3 就相当于 MapReduce 中的 reducer。
在之前动手操作了一个 WordCount 程序,因此可知,Hadoop 中 MapReduce 操作中的 Mapper 和 Reducer 在 spark 中的基本等量算子是 map 和 reduceByKey;不过区别在于:Hadoop 中的 MapReduce 天生就是排序的;而 reduceByKey 只是根据 Key 进行 reduce,但 spark 除了这两 个算子还有其他的算子;因此从这个意义上来说,Spark 比 Hadoop 的计算算子更为丰富。
6.6、RDD 缓存
Spark 速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存个数据集。当 持久化某个 RDD 后,每一个节点都将把计算的分片结果保存在内存中,并在对此 RDD 或衍 生出的 RDD 进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD 相关的持久化 和缓存,是 Spark 最重要的特征之一。可以说,缓存是 Spark 构建迭代式算法和快速交互式 查询的关键。
6.6.1、RDD 的缓存方式
RDD 通过 persist 方法或 cache 方法可以将前面的计算结果缓存,但是并不是这两个方法被 调用时立即缓存,而是触发后面的 action 时,该 RDD 将会被缓存在计算节点的内存中,并 供后面重用。
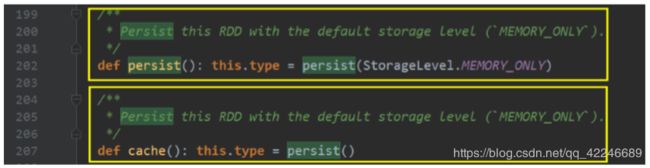
通过查看源码发现 cache 最终也是调用了 persist 方法,默认的存储级别都是仅在内存存储一 份,Spark 的存储级别还有好多种,存储级别在 object StorageLevel 中定义的。

缓存有可能丢失,或者存储存储于内存的数据由于内存不足而被删除,RDD 的缓存容错机制 保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD 的一系列转换,丢失的数据 会被重算,由于 RDD 的各个 Partition 是相对独立的,因此只需要计算丢失的部分即可,并 不需要重算全部 Partition。
7、Shared Variables(共享变量)
在 Spark 程序中,当一个传递给 Spark 操作(例如 map 和 reduce)的函数在远程节点上面运行 时,Spark 操作实际上操作的是这个函数所用变量的一个独立副本。这些变量会被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。通常跨任务的读 写变量是低效的,但是,Spark 还是为两种常见的使用模式提供了两种有限的共享变量: 广播变(Broadcast Variable)和累加器(Accumulator)
官网:http://spark.apache.org/docs/latest/rdd-programming-guide.html#shared-variables
7.1、Broadcast Variables(广播变量)
7.1.1、为什么要定义广播变量
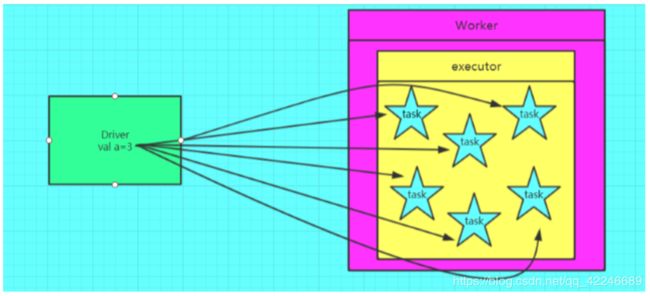
如果我们要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由 Driver 端进行分发,一般来讲,如果这个变量不是广播变量,那么每个 task 就会分发一份, 这在 task 数目十分多的情况下 Driver 的带宽会成为系统的瓶颈,而且会大量消耗 task 服务 器上的资源,如果将这个变量声明为广播变量,那么知识每个 executor 拥有一份,这个 executor 启动的 task 会共享这个变量,节省了通信的成本和服务器的资源。
没有使用广播变量:
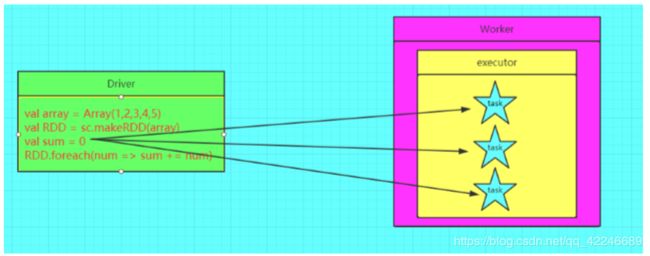
使用了广播变量之后:

7.1.2、如何定义和还原一个广播变量
定义:
val a = 3
val broadcast = sc.broadcast(a) 还原:
val c = broadcast.value 7.1.3、注意事项
1、能不能将一个 RDD 使用广播变量广播出去? 不能,因为 RDD 是不存储数据的。可以将 RDD 的结果广播出去。
2、广播变量只能在 Driver 端定义,不能在 Executor 端定义。
3、在 Driver 端可以修改广播变量的值,在 Executor 端无法修改广播变量的值。
4、如果 executor 端用到了 Driver 的变量,如果不使用广播变量在 Executor 有多少 task 就有 多少 Driver 端的变量副本。
5、如果 Executor 端用到了 Driver 的变量,如果使用广播变量在每个 Executor 中都只有一份 Driver 端的变量副本。
7.2、Accumulators(累加器)
7.2.1、为什么要定义累加器
在 Spark 应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数 据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在 被改变时不会在 driver 端进行全局汇总,即在分布式运行时每个 task 运行的只是原始变量的 一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分 布式计数的功能。
7.2.2、图解累加器
错误的图解:
正确的图解:
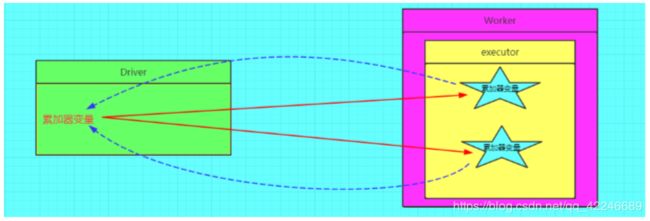
7.2.3、如果定义和还原一个累加器
定义累加器:
val a = sc.longAccumulator(0) 7.2.4、注意事项
1、累加器在 Driver 端定义赋初始值,累加器只能在 Driver 端读取最后的值,在 Excutor 端更 新。
2、累加器不是一个调优的操作,因为如果不这样做,结果是错的
转载的大哥请标明出处:https://blog.csdn.net/qq_42246689/article/details/86253396