论文理解——Audio Adversarial Examples:Targeted Attacks on Speech-to-Text
0-Abstract
本文构建了有关语音识别的定向语音对抗样本,给定任意音频波形,可以产生99.9%相似的另一个音频波形,且可以转录为所选择的任何短语。作者将基于白盒迭代优化攻击应用于DeepSpeech模型(端到端语音识别),实验显示,它具有100%的成功率。
1-Introduction
1.1Existing work
当前对对抗样本的研究大多基于图像空间,包括图像分类、图像生成模型、图像分割、面部检测等,而在音频空间研究较少,其中最常见的是自动语音识别。其中最先进的定向语音识别攻击是一种名为Houdini的新型方法,它只能构建和语音对抗样本语音相似的短语
1.2Contributions
在本文中,作者通过攻击DeepSpeech模型证明了定向对抗样本攻击存在于音频空间。通过给定任意自然波形x,能够构造几乎听不见的扰动δ,但是x +δ被识别为任何期望的短语。由任意声波开始,通过把语音嵌入不被识别为语音的音频中,通过选择silence作为目标,可以实现隐藏音频到语音to文本系统中
2-Background
2.1Neural Network & Speech Recogniton
将音频视为N维向量x,每个元素xi是一个有符号的16位值,MFC将音频分为50帧每秒,并且将每帧映射到频域。
标准的神经网络分类模型采用一输入并在所有输出标签上产生一个概率密度输出,而语音to文本系统中,有指数级可能的标签,这是计算上不可行的。因此,语音识别系统通常使用递归神经网络,将音频声波映射到单个字符概率分布序列,而不是整个短语。
2.2Connectionist Temporal Classication
Connectionist Temporal Classication是在输入和输出序列之间的比对未知时训练序列到序列神经网络的方法。
X:输入域——单帧的输入
Y:范围(字母a-z,空格,ε)
f:神经网络 f:X^N-->[0,1]^(N·|Y|)以N帧x∈X的序列作为输入,并在每个帧的输出域上返回概率分布。
![]() :xi∈X,其标签j属于Y的概率
:xi∈X,其标签j属于Y的概率
p:代表一个短语,一系列的字符
定义:
1)去除所有连续重复的字母
2)去除所有的ε
e.g. 序列 a a b ε ε b将被处理为 a b b
同时,我们可以得到
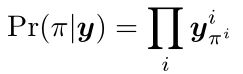
从而,
![]()
用于训练网络的损失函数是所需短语的负对数概率:
![]()
最后,为了将矢量y解码为短语p,我们搜索最适合y的短语p:

即找到一个p使Pr(p|y)最大。
而由于要运算C(x)需要搜索指数级的空间,它通常按照以下两种方式被估算:
(1)Greedy Decoding。它搜索最可能的对齐,并减少这个对齐从而获取转录的短语。
![]()
(2)Beam Search Decoding。它同时评估多个对齐的概率,然后选择最可能的短语p
2.3Adversarial Examples
对于任意一个x,它产生一个和x相似的x',但C(x)≠C(x')
2.4Targeted Adversarial Examples
定向对抗样本攻击是一种更有力的攻击方式:不仅x和x'的分类结果不同,神经网络还必须选择一个特定的标签(由对手确定的)给x'。
3-Audio Adversarial Examples
3.1Threat Model & Evaluation Benchmark
3.1.1Theat Model
给定音频波形x和目标转录y,我们的任务是构造另一个音频波形x'=x+δ,使得x和x'听起来相似,但实际上C(x')=y。只有当神经网络的输出和目标短语完全匹配才算成功。
在之前的研究中,我们假定了一个白盒测试,其对手完全了解它的模型和参数。在之后的研究中,我们尝试将攻击延展到黑盒攻击中。同时,我们假定对抗样本是被直接分类而没有引入任何噪声。
3.1.2Distortion Metric
应该如何量化引入扰动后的失真呢?
用分贝来测量失真:一个对数指标,用于测量音频样本的相对响度:
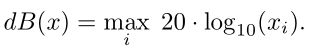
可以简化为:
![]()
因为引入的扰动比原始信号更安静,所以失真是负数,其值越小表示越安静的失真。
3.1.3Evaluation Benchmark
为了评估攻击的有效性,作者在Mozilla Common Voice数据集的前100个测试实例上构建了有针对性的音频对抗样本。对于每个样本,针对10个不同的不正确转录,随机选择,使得(a)转录不正确,以及(b)理论上可以达到该目标。
3.2An Initial Formulation
这里将构建对抗性样本的问题表达为一个优化问题:给出一个自然的例子x和任何目标短语t,我们只需要求得一个最小的dBx(δ),使得:
![]()
在之前的工作中,已经将该式转化为![]() ,其损失函数被构造称 l(x'.t)≤0 <==>C(x')=t,参数c协调了对抗性和保持接近原始样本的相对重要性。
,其损失函数被构造称 l(x'.t)≤0 <==>C(x')=t,参数c协调了对抗性和保持接近原始样本的相对重要性。
两个问题:
(1)使用CTC损失函数:l(x',t)=CTC-Loss(x',t)。对于这个损失函数,某个方向可能成立( l(x',t)≤0 => C(x')=t )但反之不然。但这也意味着结果也是对抗性的,只是可能不是最小的扰动。
(2)当使用l∞ 作为失真的尺度时,优化过程通常在结果附近摆动而不集中。我们将![]() 转化为求
转化为求 ,其中τ足够大。当获得了部分结果δ*后,减小τ,恢复最小化,重复上述过程知道找不到结果。
,其中τ足够大。当获得了部分结果δ*后,减小τ,恢复最小化,重复上述过程知道找不到结果。
最后,通过使用Adam 优化器,设置学习率为10,最大迭代次数为5000,解决了最小化问题。
3.2.1Evaluation
我们能够生成有定向对抗样本,每个源 - 目标对成功100%,平均扰动为-31dB,它大致是在一个安静环境下周围的声音和一个人说话的声音的对比。
同时,目标短语越长,定向的难度越大:每个额外的字符大约会增加0.1dB的扰动;源短语越长,越容易成为给定转录的目标。这两者之间可以相互抵消。
3.3Improved Loss Function
以下内容针对于Greedy decoding:
为了最小化CTC损失,优化器使转录短语的每个方面都更类似于目标短语。尽管已经具有该标签,但是将物品分类为更强烈的物品作为所需标签的效果导致设计更有效的损失函数:

一旦y的概率大于任何其他东西,优化器就不再通过使用该标签对其进行更强烈的分类来减少损失。
将该损失函数应用到音频域:

由于某些字符转录识别困难,为了使它们也被转录,选择一个足够大的c,它必须比所需的更大。
因此将上式转换为

其中,Li(x,πi) = l(f(x)^i,πi)
为了计算这个损失函数,需要选择一个对齐π ,采用以下两步攻击:
(1)x0:使用CTC损失的对抗样本。提取由x0引起的对齐π (通过运算π = arg maxi f(x0)^i)用于第二步
(2)固定对齐π ,使用上述改进了的损失函数![]() 产生一个较小失真的对抗样本x',采用梯度下降的方式,δ=x0-x进行运算。
产生一个较小失真的对抗样本x',采用梯度下降的方式,δ=x0-x进行运算。
3.3.1Evaluation
生成的对抗性示例现在只能保证对Greedy decoder有效
 (视觉无法区分)
(视觉无法区分)
3.4Audio Information Density
3.5Starting from Non-Speech
我们不仅可以将一个人的语音转录为不正确的文本,也能将任意非语音音频样本转换为任意目标短语。
为了评估这种攻击的有效性,采用来自不包含语音的古典音乐的五秒剪辑和Common Voice数据集中包含的目标短语。但这种攻击需要更多的计算工作(我们执行20,000次迭代下降迭代),总失真略大,平均为-20dB
3.6Targeting Silence
增加DeepSpeech无法转录的对抗性噪声来隐藏语音。
虽然执行此攻击而不进行修改(仅通过空短语)是有效的,但如果我们将silence定义为仅重复空格字符的任意长度序列,则可以略微改进。
为了获取这个silence,我们让:

我们发现定位silence比定位目标短语更容易:当失真小于原始信号低于-45dB,我们可以将任何短语变为静音。这也解释了为什么音频越长,构建对抗样本更容易:长的短语包括耕读的声音,对手可以使不需要的声音silence,从而获得与目标几乎匹配的子序列,而短的则需要合成以前不存在的新字符。
4-Audio Adversarial Example Properties
4.1 Evaluating Single-Step Methods
Goodfellow等人认为,由于神经网络的局部线性特性,对抗性的例子在很大程度上是有效的。
FGSM证明它在图像空间是适用的。FGSM在损失函数的梯度方向上采用:给定具有损失函数l的网络F,通过![]() 计算对抗性样本。对于图像中的每个像素,此攻击询问“我们应该在哪个方向上修改此像素以最大限度地减少损失?”然后同时在每个像素的该方向上迈出一小步。此攻击可以直接应用于音频,更改单个样本而不是像素。
计算对抗性样本。对于图像中的每个像素,此攻击询问“我们应该在哪个方向上修改此像素以最大限度地减少损失?”然后同时在每个像素的该方向上迈出一小步。此攻击可以直接应用于音频,更改单个样本而不是像素。
然而,由于计算MFCC时引入的固有非线性,以及多轮LSTM的深度,在输出中引入了很大程度的非线性,我们发现这种单步攻击的方式在音频对抗样本领域却并不是高效的。

在图3中,我们比较了在已知对抗性示例的方向上行进时CTC损失的值与在快速梯度符号方向上行进相比的值。虽然最初(靠近源音频样本),快速梯度方向在减少损失函数方面更有效,但它快速平稳并且之后不会减小。另一方面,使用基于迭代优化的攻击找到最终导致对抗性示例的方向。 (只有当CTC损失低于10时,该短语才能正确转录。)
4.2Robustnss of Adversarial Examples
构建对各种形式的噪声具有鲁棒性的对抗样本是可能的。
4.2.1Robustness to pointwise noise
给定对抗样本x0,将逐点随机噪声σ添加到x0并返回C(x +σ)将导致x0失去其对抗性标记,即使失真σ足够小以允许正常示例保留其分类。
我们生成一个高置信度的对抗性样本x0,并利用Expectation over Transforms生成一个对抗这个合成-30dB噪声的对抗性样本,当我们这样做时,对抗性扰动增加大约10dB。
4.2.2Robustness to MP3 compression
我们利用straight-through estimator来构建对MP3压缩具有鲁棒性的对抗样本。假设MP3压缩的梯度是恒等函数,通过计算CTC-Loss的梯度,我们生成对抗样本x0,使得C(MP3(x 0))被分类为目标标签。虽然单个梯度步骤可能不正确,但总体而言,梯度平均值变得有用。这使我们能够生成具有大约15dB较大失真的对抗性示例,这些失真对于MP3压缩仍然很稳健。
5-Open Questions
- Can these attacks be played over-the-air?
本文中构建的音频对抗性示例在通过空中播放后不会保持对抗性,因此存在有限的现实世界威胁
- Do universal adversarial perturbations exist?
在图像的空间上,可以构造单个扰动δ,当应用于任意图像x时,将使其分类不正确。这些攻击在音频上会很强大,并且会对应于可以播放的扰动,以使任何其他波形识别为目标短语。
- Are audio adversarial examples transferable?
给定音频样本x,是否可以生成单个扰动δ,使得对于多个分类器fi,fi(x +δ)= y。
可转移性被认为是神经网络的基本属性[34],使构建强大的防御变得非常复杂,并且允许攻击者进行黑盒攻击。
- Which existing defenses can be applied audio?
对抗性样本的所有现有防御仅在图像域上进行了评估。如果防御者的目标是产生一个强大的神经网络,那么它应该提高对所有领域的对抗性例子的抵抗力,而不仅仅是对图像的抵抗力。
6-Conclusion
证明了定向音频对抗样本在自动语音识别方面是有效的。通过基于优化的攻击被应用到端到端,我们能够通过仅添加轻微失真将任何音频波形转换为任何目标转录,并获得100%的成功。同时,可以使音频每秒最多转录50个字符(理论上的最大值),使音乐转录为任意语音,并隐藏语音不被转录。
我们提出初步证据表明音频对抗性示例与图像上的对象具有不同的属性,表明线性不适用于音频域。