Kafka的安装部署(分布式部署安装)
官网:http://kafka.apache.org/quickstart
Kafka强依赖ZK,如果想要使用Kafka,就必须安装ZK,Kafka中的消费偏置信息、kafka集群、topic信息会被存储在ZK中。有人可能会说我在使用Kafka的时候就没有安装ZK,那是因为Kafka内置了一个ZK,一般我们不使用它。
kafka 在CDH当中kafka是独立分支(跟zookeeper的版本可以不一样)
一:准备工作
1.zookeeper部署
[root@yws85 zookeeper-3.4.6]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/software/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
[root@yws85 zookeeper-3.4.6]#
[root@yws86 zookeeper-3.4.6]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/software/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader
[root@yws86 zookeeper-3.4.6]#
[root@yws87 zookeeper-3.4.6]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/software/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
[root@yws87 zookeeper-3.4.6]#
如何看kafka_2.11 - 0.10.0.1.tgz
scala 是 2.11 版本
kafak是 0.10.0.1 kafka版本(生产上用0.10版本足以,没有必要使用官网提供的更高版本,生产求稳,)
问题:那为什么非得选择0.10.这个版本呢
kafka 后面对接Spark Streaming
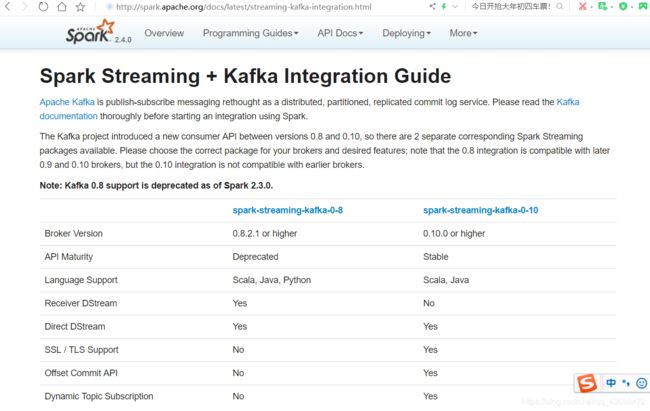
网址连接:http://spark.apache.org/docs/latest/streaming-kafka-integration.html
2.JDK部署
3. scala部署
scala-2.11.8.tgz
tar -xzvf scala-2.11.8.tgz(解压)
chown -R scala-2.11.8(修改权限)
ln -s scala-2.11.8 scala(设置软连接)
(配置环境变量)
export SCALA_HOME=/opt/software/scala-2.11.8
export PATH=$SCALA_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$FLINK_HOME/bin:$PATH
4.事先有的zk,不确定zk是否有kafka残留信息
cd zookeeper/bin
./zkCli.sh
ls / (根目录看一下有没有)
help
rmr /kafka
[zk: localhost:2181(CONNECTED) 2] ls /kafka
[controller_epoch, brokers, admin, isr_change_notification, consumers, config]
[zk: localhost:2181(CONNECTED) 3] rmr /kafka
生产上很常见,一旦kafka出现问题,需要重新部署的时候,一定要清理干净在部署
二:下载
kafka下载网址:http://mirrors.hust.edu.cn/apache/kafka/0.10.2.2/
[root@yws87 kafka]# mkdir logs (创建存储目录)
[root@yws87 config]# vi server.properties (相当于broker配置服务端)
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=3
port=9092
host.name=192.168.0.87
日志
# A comma seperated list of directories under which to store log files
log.dirs=/opt/software/kafka/logs
(这里之前使用了软连接,操作方便,如果版本多更容易乱)
zookeeper关联(本身带zookeeper,这里会有默认配置,我们是集群这里要进行如下配置)
zookeeper.connect=192.168.0.85:2181,192.168.0.86:2181,192.168.0.87:2181/kafka
注意:/kafka我们在这里加了一个这个,,
原因:是因为kafka文件下有很多文件夹。这样操作更方便管理,和日后删除
然后scp复制到另外2台机器,在配置文件中更改
三:启动
[root@yws87 kafka]# nohup bin/kafka-server-start.sh config/server.properties &
[1] 19455
[root@yws87 kafka]# nohup: ignoring input and appending output to ‘nohup.out’
[root@yws87 kafka]#
[root@yws87 kafka]# tail -F nohup.out
[root@yws87 config]# jps
21234 Jps
10590 QuorumPeerMain
19455 Kafka