python初步学习-python模块之 os、sys、random、itertools、colorsys模块
一、os模块
os 模块在运维工作中是很常用的一个模块。通过os模块调用系统命令。os模块可以跨平台使用。
说明:os模块是对操作系统进行调用的接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
os.pardir#获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2')#可生成多层递归目录
os.removedirs('dirname1')#若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname')#生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname')#删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname')#列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove()#删除一个文件
os.rename("oldname","newname")#重命名文件/目录
os.stat('path/filename')#获取文件/目录信息
os.sep#输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep#输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep#输出用于分割文件路径的字符串
os.name#输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command")#运行shell命令,直接显示
os.environ#获取系统环境变量
os.path.abspath(path)#返回path规范化的绝对路径
os.path.split(path)#将path分割成目录和文件名二元组返回
os.path.dirname(path)#返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path)#返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path)#如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path)#如果path是绝对路径,返回True
os.path.isfile(path)#如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path)#如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]])#将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path)#返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path)#返回path所指向的文件或者目录的最后修改时间
在 import os的时候,建议使用import os而非from os import *。这样可以避免os.open()不会覆盖内置函数open().
(1)os.name()
判断系统类型
import os
print os.name
# linux和Unix系统会返回`posix`
# windows 系统会返回`nt`
(2)os.system()
执行系统命令的模块,返回命令执行的状态码,开启一个子shell执行命令
import os
cmd = 'ifconfig'
retval = os.system(cmd)
print retval
# 结果为 0
# 表示命令执行成功,否则为失败
(3)os.popen()
popen也是去执行一个命令,不过相比system(cmd),os.popen(command [, mode='r' [, bufsize]]),参数更多,而且是开启一个管道去执行。
- cmd - 执行的命令
- mode - 模式权限可以是'r'(默认)或'w'
- buffering - 0意味着无缓冲;1意味着行缓冲;其它正值表示使用参数大小的缓冲(大概值,以字节为单位)。负的bufsize意味着使用系统的默认值,一般来说,对于tty设备,它是行缓冲;对于其它文件,它是全缓冲。如果没有改参数,使用系统的默认值。(不明白????)
import os
cmd = 'mkdir nwdir'
a = os.popen(cmd)
print a
print type(a)
#返回结果
#
# (4)os.listdir(path)
打印指定目录的文件,返回一个列表
import os
a = os.listdir('/tmp')
print a
(5)os.getcwd()
返回当前绝对路径,返回类型为str
import os
a = os.getcwd()
print a(6)os.chdir(path)
改变当前路径
import os
print os.getcwd()
os.chdir(/tmp/aaa)
print os.getcwd()
(7)os.mkdir()
mkdir(path [, mode=0755])
默认权限是0755
如果目录已存在,会异常OSError
(8)os.remove(path)
删除文件,只能删除文件
(9)os.rmdir(path)
删除目录,只能删除目录
回到顶部
(10)os.path
该模块主要是针对路径的操作。
(11)os.path.abspath(path)
返回绝对路径,主要有引号
import os
print os.path.abspath('.')
#结果
D:\Python\project
(12)os.path.basename(path)
返回文件名,类似linux 中的basename命令
import os
print os.path.basename('D:\Python\project')
#结果
project(13)os.path.dirname(path)
返回文件路径,不包含文件名,类似linux中的dirname命令
import os
print os.path.dirname('D:\Python\project')
#结果
D:\Python(14)os.path.exists(path)
判断路径是否存在,存在返回True,不存在返回False
a = 'D:\Python\project11111'
print os.path.exists(a)
#结果
False类似这种:
| 命令 | 说明 |
|---|---|
| os.path.isfile | 判断是否是文件 |
| os.path.isdir | 判断是否是目录 |
| os.path.isline | 判断是否是个链接文件 |
| os.path.ismount | 判断是否是挂载点 |
| os.path.isabs | 判断是否是绝对路径 |
(15)os.path.join(path1,path2)
把 path1、path2文件或目录合并成一个路径
二、sys模块
sys模块包含了与Python解释器和它的环境有关的函数。当Python执行import sys语句的时候,它在sys.path变量中所列目录中寻找sys.py模块。如果找到了这个文件,这个模块的主块中的语句将被运行,然后这个模块将能够被你 使用 。注意,初始化过程仅在我们 第一次 输入模块的时候进行。另外,“sys”是“system”的缩写。Sys模块函数之多,我只能选取自己认为比较实用的一些函数列在此处。借马云找员工的说法,”找最合适的而不是最天才的”,这句话,我个人觉得在很多方面都能适应,学习也不在话下。Sys模块功能的确很多,但我们应该将重点放在那些功能才是最适合我们的,为此,我列的这些函数,就是我认为比较适合我以后开发的函数。
1
2
3
4
5
6
7
8
sys.argv#命令行参数List,第一个元素是程序本身路径
sys.exit(n)#退出程序,正常退出时exit(0)
sys.version#获取Python解释程序的版本信息
sys.maxint#最大的Int值
sys.path#返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform#返回操作系统平台名称
sys.stdout.write('please:')
val=sys.stdin.readline()[:-1]
(1)sys.argv
很多人会想,我如何给我的程序在外部传递参数呢?这个,就可以实现。如:
Tesy.py
Import sys
Print sys.argv[number]
一般情况下,number为0是这个脚本的名字,1,2…则为命令行下传递的参数.如:
Test.py脚本内容:
import sys
print sys.argv[0]
print sys.argv[1]
print sys.argv[2]
print sys.argv[3]
那么
[root@databak scripts]# python test.py arg1 arg2 arg3
test.py
arg1
arg2
arg3
看到,对应的关系了吗?
sys模块中的argv变量通过使用点号指明——sys.argv——这种方法的一个优势是这个名称不会与任何在你的程序中使用的argv变量冲突。另外,它也清晰地表明了这个名称是sys模块的一部分。
sys.argv变量是一个字符串的 列表 (列表会在后面的章节详细解释)。特别地,sys.argv包含了 命令行参数 的列表,即使用命令行传递给你的程序的参数。
这里,当我们执行python using_sys.py we are arguments的时候,我们使用python命令运行using_sys.py模块,后面跟着的内容被作为参数传递给程序。Python为我们把它存储在sys.argv变量中。
记住,脚本的名称总是sys.argv列表的第一个参数。所以,在这里,'using_sys.py'是sys.argv[0]、'we'是sys.argv[1]、'are'是sys.argv[2]以及'arguments'是sys.argv[3]。注意,Python从0开始计数,而非从1开始。
(2)sys.platform
大家都知道,当今的程序比较流行的是跨平台。简单的说就是这段程序既可以在windows下,换到linux下也可以不加修改的运行起来,听起来就不错。所以,这个函数就可以派上用场了。
假设,我们想实现一个清除终端,linux下用clear, windows下用cls
Ostype=sys.platform()
If ostype==”linux” or ostype==”linux2”:
Cmd=”clear”
Else:
Cmd=”cls”
(3) sys.exit(n)
执行至主程序的末尾时,解释器会自动退出. 但是如果需要中途退出程序, 你可以调用sys.exit 函数, 它带有一个可选的整数参数返回给调用它的程序. 这意味着你可以在主程序中捕获对sys.exit 的调用。(注:0是正常退出,其他为不正常,可抛异常事件供捕获!)
sys.exit从python程序中退出,将会产生一个systemExit异常,可以为此做些清除除理的工作。这个可选参数默认正常退出状态是0,以数值为参数的范围为:0-127。其他的数值为非正常退出,还有另一种类型,在这里展现的是strings对象类型。
(4)sys.path
大家对模块都有一定了解吧?大家在使用模块的某一个功能前,是不是需要导入呢?答案是需要。那import,__import__命令就不用提干嘛的了吧。那大家在执行import module_name的时候,python内部发生了什么呢?简单的说,就是搜索module_name。根据sys.path的路径来搜索module.name
>>> sys.path
['', '/usr/local/lib/python24.zip', '/usr/local/lib/python2.4', '/usr/local/lib/python2.4/plat-freebsd4', '/usr/local/lib/python2.4/lib-tk', '/usr/local/lib/python2.4/lib-dynload', '/usr/local/lib/python2.4/site-packages']
大家以后写好的模块就可以放到上面的某一个目录下,便可以正确搜索到了。当然大家也可以添加自己的模块路径。Sys.path.append(“mine module path”).
sys.path包含输入模块的目录名列表。我们可以观察到sys.path的第一个字符串是空的——这个空的字符串表示当前目录也是sys.path的一部分,这与PYTHONPATH环境变量是相同的。这意味着你可以直接输入位于当前目录的模块。否则,你得把你的模块放在sys.path所列的目录之一。首先,我们利用import语句 输入 sys模块。基本上,这句语句告诉Python,我们想要使用这个模块。sys模块包含了与Python解释器和它的环境有关的函数。
(5)sys.modules
This is a dictionary that maps module names to modules which have already been loaded. This can be manipulated to force reloading of modules and other tricks.
Python.org手册里已经说的很明白了。
For names in sys.modules.keys():
If names != ’sys’:
(6)sys.stdin,sys.stdout,sys.stderr
stdin , stdout , 以及stderr 变量包含与标准I/O 流对应的流对象. 如果需要更好地控制输出,而print 不能满足你的要求, 它们就是你所需要的. 你也可以替换它们, 这时候你就可以重定向输出和输入到其它设备( device ), 或者以非标准的方式处理它们
三、random模块
random() 函数中常见的函数如下
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import random
print( random.randint(1,10) ) # 产生 1 到 10 的一个整数型随机数
print( random.random() ) # 产生 0 到 1 之间的随机浮点数
print( random.uniform(1.1,5.4) ) # 产生 1.1 到 5.4 之间的随机浮点数,区间可以不是整数
print( random.choice('tomorrow') ) # 从序列中随机选取一个元素
print( random.randrange(1,100,2) ) # 生成从1到100的间隔为2的随机整数
a=[1,3,5,6,7] # 将序列a中的元素顺序打乱
random.shuffle(a)
print(a)1.random.random()
#用于生成一个0到1的
随机浮点数:0<= n < 1.0
import random
random.random()
2.random.uniform(a,b)
#用于生成一个指定范围内的随机符点数,两个参数其中一个是上限,一个是下限。如果a > b,则生成的随机数n: a <= n <= b。如果 a 四、sys模块
itertools是python内置的模块,使用简单且功能强大,这里尝试汇总整理下,并提供简单应用示例;如果还不能满足你的要求,欢迎加入补充。
使用只需简单一句导入:import itertools
(1)chain()
与其名称意义一样,给它一个列表如 lists/tuples/iterables,链接在一起;返回iterables对象。
letters = ['a', 'b', 'c', 'd', 'e', 'f']
booleans = [1, 0, 1, 0, 0, 1]
print(list(itertools.chain(letters,booleans)))
# ['a', 'b', 'c', 'd', 'e', 'f', 1, 0, 1, 0, 0, 1]
print(tuple(itertools.chain(letters,letters[3:])))
# ('a', 'b', 'c', 'd', 'e', 'f', 'd', 'e', 'f')
print(set(itertools.chain(letters,letters[3:])))
# {'a', 'd', 'b', 'e', 'c', 'f'}
print(list(itertools.chain(letters,letters[3:])))
# ['a', 'b', 'c', 'd', 'e', 'f', 'd', 'e', 'f']
for item in list(itertools.chain(letters,booleans)):
print(item)(2)count()
生成无界限序列,count(start=0, step=1) ,示例从100开始,步长为2,循环10,打印对应值;必须手动break,count()会一直循环。
i = 0
for item in itertools.count(100,2):
i += 1
if i > 10 : break
print(item) (3)filterfalse ()
Python filterfalse(contintion,data) 迭代过滤条件为false的数据。如果条件为空,返回data中为false的项;
booleans = [1, 0, 1, 0, 0, 1]
numbers = [23, 20, 44, 32, 7, 12]
print(list(itertools.filterfalse(None,booleans)))
# [0, 0, 0]
print(list(itertools.filterfalse(lambda x : x < 20,numbers)))
(4)compress()
返回我们需要使用的元素,根据b集合中元素真值,返回a集中对应的元素。
print(list(itertools.compress(letters,booleans)))
# ['a', 'c', 'f']
(5)starmap()
针对list中的每一项,调用函数功能。starmap(func,list[]) ;
starmap(pow, [(2,5), (3,2), (10,3)]) --> 32 9 1000
>>> from itertools import *
>>> x = starmap(max,[[5,14,5],[2,34,6],[3,5,2]])
>>> for i in x:
>>> print (i)
14
34
5(6)repeat()
repeat(object[, times]) 重复times次;
repeat(10, 3) --> 10 10 10(7)dropwhile()
dropwhile(func, seq );当函数f执行返回假时, 开始迭代序列
dropwhile(lambda x: x<5, [1,4,6,4,1]) --> 6 4 1(8)takewhile()
takewhile(predicate, iterable);返回序列,当predicate为true是截止。
takewhile(lambda x: x<5, [1,4,6,4,1]) --> 1 4(9)islice()
islice(seq[, start], stop[, step]);返回序列seq的从start开始到stop结束的步长为step的元素的迭代器
for i in islice("abcdef", 0, 4, 2):#a, c print i(10)product()
product(iter1,iter2, ... iterN, [repeat=1]);创建一个迭代器,生成表示item1,item2等中的项目的笛卡尔积的元组,repeat是一个关键字参数,指定重复生成序列的次数
# product('ABCD', 'xy') --> Ax Ay Bx By Cx Cy Dx Dy # product(range(2), repeat=3) --> 000 001 010 011 100 101 110 111
for i in product([1, 2, 3], [4, 5], [6, 7]): print i(1, 4, 6)(1, 4, 7)(1, 5, 6)(1, 5, 7)(2, 4, 6)(2, 4, 7)(2, 5, 6)(2, 5, 7)(3, 4, 6)(3, 4, 7)(3, 5, 6)(3, 5, 7)(11)permutations()
permutations(p[,r]);返回p中任意取r个元素做排列的元组的迭代器
for i in permutations([1, 2, 3], 3): print i(1, 2, 3)(1, 3, 2)(2, 1, 3)(2, 3, 1)(3, 1, 2)(3, 2, 1) (12)combinations()
combinations(iterable,r);创建一个迭代器,返回iterable中所有长度为r的子序列,返回的子序列中的项按输入iterable中的顺序排序
note:不带重复
for i in combinations([1, 2, 3], 2): print i(1, 2)(1, 3)(2, 3)(13)combinations_with_replacement()
同上, 带重复 例子:
for i in combinations_with_replacement([1, 2, 3], 2): print i(1, 1)(1, 2)(1, 3)(2, 2)(2, 3)(3, 3)应用示例
求质数序列中1,3,5,7,9,11,13,15三个数之和为35的三个数;
def get_three_data(data_list,amount): for data in list(itertools.combinations(data_list, 3)): if sum(data) == amount: print(data)#(7, 13, 15)#(9, 11, 15)五、colorsys模块
colorsys模块提供了用于RGB和YIQ/HLS/HSV颜色模式的双向转换的接口。它提供了六个函数,其中三个用于将RGB转YIQ/HLS/HSV,另外三个用于将YIQ/HLS/HSV转为RGB。
colorsys.rgb_to_yiq(r, g, b)
colorsys.rgb_to_hls(r, g, b)
colorsys.rgb_to_hsv(r, g, b)
colorsys.yiq_to_rgb(y, i, q)
colorsys.hls_to_rgb(h, l, s)
colorsys.hsv_to_rgb(h, s, v)
需要注意的是:除了I和Q之外的其他参数取值都是在[0, 1]范围内的浮点数。所以传入RGB参数的时候还需要额外做一个除以255的操作。
>>> import colorsys
>>> colorsys.rgb_to_hsv(30/255, 50/255, 160/255)
(0.6410256410256411, 0.8125, 0.6274509803921569)具体的转换算法在这就不介绍了,源码里都有,也就100多行,有兴趣阅读源码的同学可以在Python根目录/Lib目录下找到colorsys.py这个源文件。在这主要介绍一下模块中涉及到的四种颜色模型。
RGB
RGB是一种相加色,也就是根据红绿蓝三种光的相互叠加来显示不同的颜色,RGB三个字母分别代表红色Red、绿色Green和蓝色Blue。那些分辨率比较小的的显示器用手机拍出照片后放大看,就可以看到由红绿蓝三种颜色的发光管共同组成的一个像素,像素的颜色就是由这三个发光管的亮度决定的。
HSL和HSV
HLS也就是人们常说的HSL,分别代表色相Hue,亮度Lightness和饱和度Saturation。HSV也就是HSB,用过Photoshop的同学应该对HSB不陌生,它的三个字母分别代表色相Hue,饱和度Saturation和明度Value(Brightness)。
RGB在数学上可以用一个平面直角坐标系来表示,三个坐标轴分别代表红绿蓝三色的色值。但是用RGB来表示颜色时,颜色的变化对于人类来说并不是很直观,于是就产生了HSL和HSV。HSL和HSV通过对颜色信息的进一步封装,使其通过一种人类更加容易感知的形式来表示颜色变化。(色调的变化、亮度的变化、色彩纯度的变化)
HSL和HSV通过对RGB颜色模型进行变换,将原本的平面直角坐标系转换为一个圆柱坐标系。HSL颜色模型的顶端是白色,底端是黑色,可以用一个双六角锥体来表现。而HSV颜色模型可以用一个倒六角锥体来表示,锥体的顶点是黑色。下图来自英文维基百科,展现了RGB是怎么转换为HSL和HSV的:
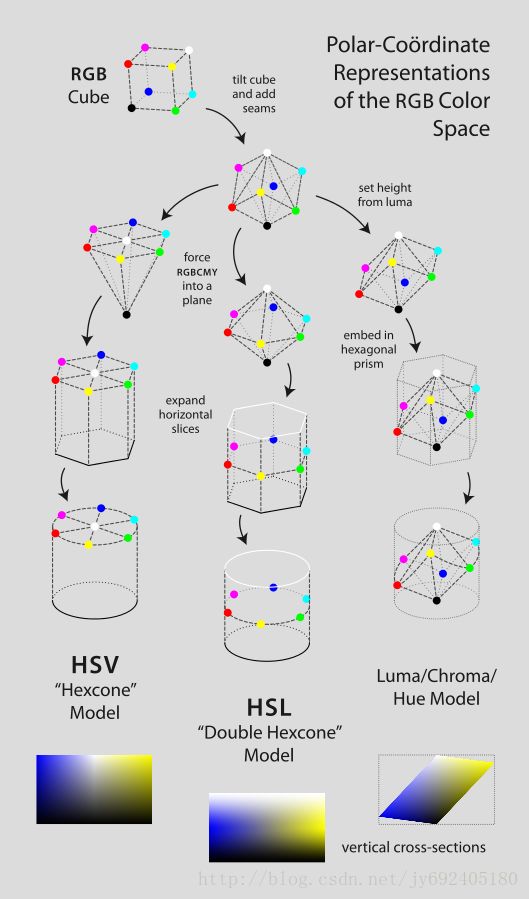
注意:这两个颜色模型中对于色相的定义是相同的,但各自对于饱和度的定义是不同的。
下面两张同样来自维基百科的图片展示了这两个模型的差异:
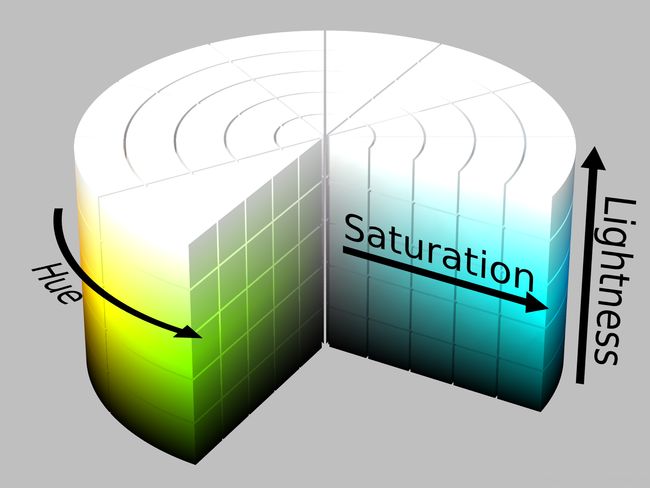
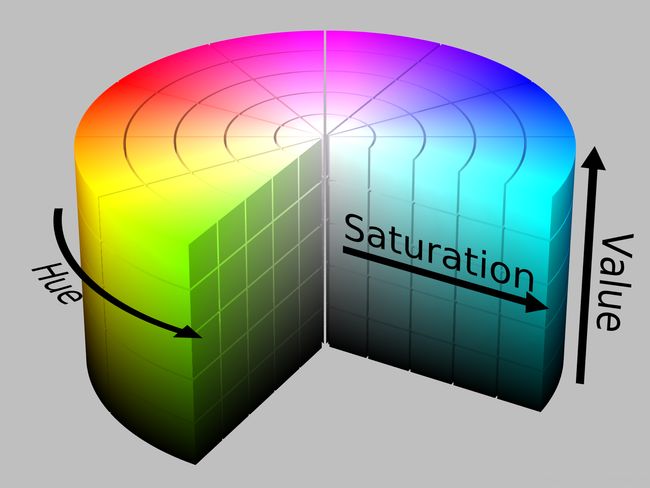
YIQ
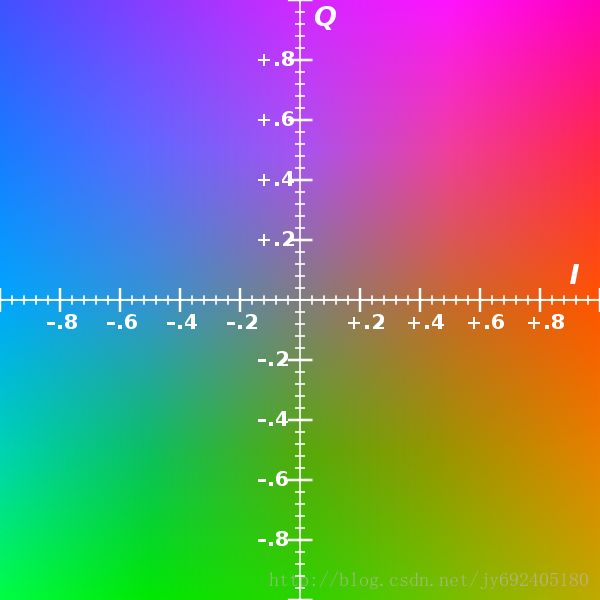
YIQ颜色模型使用亮度Luminance和色度Chrominance来表示颜色。用一组坐标来表示颜色的变化,Q表示了颜色色调由紫到绿的变化,I表示了颜色色调由橙到蓝的变化。
关于YIQ的特点,百度百科-颜色空间作了以下总结
总结
其实模块和源码倒没有什么难的,难的是几个颜色模型的概念,在bing和百度上找到的中文资料都非常有限。如果有读者对这方面感兴趣的,推荐你们读一下下面链接里的参考资料,有条件的最好买图像处理方面的专业书籍来看。