关于数据准确性,精益求精,神策数据矢志不渝的坚持


你是否遭遇过以下场景?
老板:“你提交的报告,怎么和我查的不一样?”
业务部:“ERP 后台显示成单 687 笔,你怎么告诉我成单 620 笔?”
运营:“你给我的转化率,为何比实际成单算的转化率低?”
显然,数据准确性,常常成为企业爆发内战的导火索。
数据驱动时代,数据准确性即将成为进一步数字化、精细化的硬性指标,特别是越来越注重用户行为分析的今天,精益求精,是历史的趋势,也是神策数据相信的未来。
事实上,排除掉人为因素,或技术能力限制,不可抗因素导致的数据上报不及时或丢失,一般情况下 App 端约占 1%,Web 端约占 5%。这在过去历史数据的洪流中可能激不起波澜,但在做精细化运营的今天,用户行为路径中哪怕只丢失 1% 的数据,也可能影响分析结果或错失机遇。
比如,漏斗分析、留存分析、归因分析等模型均为多步骤组合,丢失任一环节的数据均可能影响最终的结果。
举个例子某电商的漏斗模型为:浏览商品详情页-加入购物车-提交订单-支付订单,一般数据是实时采集上报,但在极端情况下,部分用户在提交订单的数据丢失,那么相关环节的转化率将不准确,分析结果也会出现误差。
再比如,若未上报的这 1% 的数据,涵盖极其关键的甚至决定性的事件数据,将造成连带影响,如影响数据的完整性。
举个例子,神策数据支持用户未登录的匿名行为与登录后的行为打通,还原完整的用户全链条。在该过程中,存在一个关键事件,用户登录的当下绑定未登录之前的行为,如果丢失了这个事件,用户登录前的行为就无法匹配了,因为用户行为链条是环环相扣的。
综上,在精益求精的大数据时代,丢失哪怕不到 1% 的数据,也会牵一发而动全身。因此,神策坚持使数据准确,且保证数据与真实场景发生的当时当刻吻合,不容一丝侥幸与意外。
一、关于数据准确性,你必须知道的事
纵观大部分数据应用,数据处理可以划分为如下五个步骤,每个步骤都可能影响数据准确性:

图 1 数据处理的五个步骤
总体上看,排除人为因素,通常数据准确性的问题可抽象为 3 种情况:
1. 统计口径差异
如 App 启动,很多统计工具使用设备 ID 计算用户,将导致同一个登录 ID 在多设备使用的情况下使 uv=N。而神策数据使用神策 ID 进行计算,可使同一个登录 ID 在多设备使用的情况下 uv=1。
2. 代码采集异常
如客户端使用匿名 ID 上报数据,服务端使用登录 ID 上传数据,导致同一用户没有关联,系统识别为两个用户导致用户总量不一致,神策数据使用同一 ID 上报全端数据,支持企业打通用户登录前后行为。
3. 数据上报延迟或丢失
数据上报往往是通过 http 或者 https 请求进行传输,因此网络稳定性和 App 使用异常均极大的影响上报的及时性。
在这三方面中,数据上报延迟或丢失存在非技术原因的不可抗因素导致,如下图。
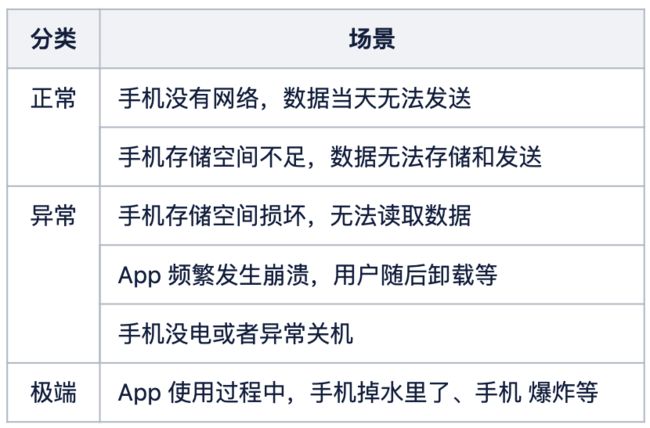
表 1 数据延迟场景
在以上场景中,用户产生了数据,但却因为非数据采集技术原因导致了数据的丢失或延迟。针对这一特殊情况,你会选择在事后进行数据的回溯,还是忽略未实时上报的数据?
大多数的直觉答案是“利用数据回溯,保证数据准确性”,但数据回溯还面临两大难题:其一,由于技术能力限制只能让数据延迟或丢失;其二,同一天的数据在不同周期查看会发生变化,如何向用户解释?
因此,大部分数据分析平台服务提供商选择了牺牲数据准确性,与之不同,神策数据精研技术,通过数据的回溯与补充助力企业坚守数据准确性的红线。
二、可解释性 VS 准确性,神策数据的坚持
面对变幻莫测的现实情况,极端情况下的数据准确性和可解释性总是不可兼得——极端情况下数据的丢失易让人接受,复杂技术下坚守的数据准确却令人费解。
技术壁垒从不是神策数据的难题,但面对客户潜在的不解,又该如何抉择?神策坚持选择数据准确性。
1. 看似正确的“错误”,数据不应该变化?
在数据分析行业中,为保证数据的可解释性,基本上企业会以当天 23 点 59 分 59 秒截止进行数据的结算。由于数据分析系统历史的技术框架限制,后续即使有延迟数据也不会进行数据的补充。长期以往,各企业习惯了以当天结算的数据为准,即不管时间周期如何变化,仅看某一天的数据是固定不变的,成为大家默认的规则。当数据发生变化,常常会被冠上“数据不准确”的帽子。
“忽略特殊情况下未上报的数据”只是历史遗留问题,却被误认为“正确的事”。因此,变化的数据,无疑将增加解释成本。更难的是,数据并不是给 1 个人看的,每个人都可能提出数据变化的质疑。
首先,数据分析的人会困惑数据的变化;其次,即使给数据分析的人进行了清晰的说明,但向上汇报时,又会衍生新的可解释性问题。举个例子,数据分析师 A 做了一个报告给老板,报告中记录周一日活为 14000,但老板周五看的时候发现周一日活为 14500,因此,数据分析师 A 可能会迎来老板的质疑,这给 A 带来困扰,甚至该负面情绪可能并不会因为解释而消除。
历史遗留问题加上解释成本,让很多数据分析企业望而却步,有的是出于技术能力限制,有的是无法面对“约定俗成”的质疑。但神策数据,选择坚守信念,只做正确的事情。
三、敢为人先,神策数据以变制变
“把事情做到极致”是神策数据的做事原则。在数据准确性这件事上,哪怕付出更多的技术资源和解释成本,也坚持为“给客户带来价值”负责,面对疑虑,坦然应对。
神策数据选择以变制变。目前,使用神策数据的企业数据产生后,存在 10 天的回溯期,在此期间查询相关的数据均可能发生变化,10 天之后回溯完毕,数据将不再变化。
以下,为神策数据 SDK 缓存上报数据的场景:
1. 强杀场景,用户主动关闭
对于 Android 用户来说,用户常用的关闭 App 的方式就是退到后台将 App 划掉,对于这种场景,埋点数据会缓存在本地,未及时上传,比如退出事件,需要用户下次打开时进行上报。
2. 多进程触发数据采集
对于 Android App 来说,多进程场景是很普遍的场景,比如推送场景,或者一些来电服务的 App,经常活动的是子进程,对于这种在子进程埋点业务数据比较多的场景,需要在主进程启动时才会将缓存在本地的数据进行上报。
3. 没有网络或网络信号较差
在电梯或地铁里由于网络信号较差时,可能会出现埋点数据无法上报的情况,造成本地缓存埋点数据的情况,需要用户在网络条件状况良好时,重新进行数据上报。
4. App 异常退出
App 异常是最普遍的一个场景了,当 App 出现异常退出时,可能会造成部分埋点数据无法及时上传,待用户下次打开 App 时重新上传。
5. iOS 被动启动
在 iOS 中,当 App 由于一些原因(例如静默推送)被动启动时,采集的所有事件会在 App 下次启动时上传数据。
俗话说,“你不能解决问题,你就会成为问题”。在面对数据准确性的历史挑战,神策数据选择了更艰难的一条路,这条路虽然会偶遇客户的不解,但其终点是给客户带来更大的价值,神策数据矢志不渝。同时,若客户因特殊原因,理解背景后仍坚持保持数据不变,我们也给予了灵活的策略,可将回溯周期降低为 24 小时。此外,神策也会优化产品,如增加小提示,促进客户的理解。
在过去的 5 年里,神策数据服务了 1000 余家企业,未来将为更多的企业解决数据根基问题。背负着客户的未来,神策数据面对历史的难题,坚持以变应变,以变制变,力求在大数据时代,为即将到来的数据准确性变革领航,更为客户保驾护航。
立足于重构中国互联网数据根基的愿景,关于数据准确性,神策数据捍卫到底,决不允许一丝的侥幸与意外。
✎✎✎
【更多内容】
银行 4.0 时代,打开客户标签五扇门,高效赋能数据化运营
还没真正理解用户标签体系?看这篇就够了!
神策数据保险行业解决方案,正式上线官网!



点击“阅读原文”,体验 demo~