RCNN极其细致初学者阅读笔记
版权声明:本文由 Kathy 投稿
1、 Introduction
1.1 R-CNN and SPPnet
R-CNN的弊端:
多阶段(3)的训练过程
训练的时间和空间开销大
速度过慢
R-CNN的问题症结在于其不能共享计算,而SPPnet改进了这个问题,通过对整张图卷积得到特征图,从这张特征图上进行region proposal而能够共享卷积的计算结果,加速了 R-CNN;后通过空间金字塔池化实现了任意尺度图像的输入。
SPPnet的问题在于:训练仍是多阶段的;特征提取后仍需存放到磁盘造成大的开销;不像R-CNN,其微调算法不能更新金字塔池化之前的卷积层,从而限制了网络的深度。
1.2 contribution
提出Fast R-CNN,其优点为:
更高的检测精度mAP
训练时单阶段的
训练过程可以更新所有层网络参数
无需为特征图缓存消耗内存
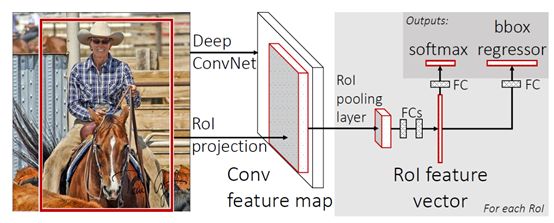
2、 Fast R-CNN architecture and training
网络结构为:
输入整张图片,通过卷积池化提取特征图
在特征图上提取RoI (region of interest),相当于region proposal 阶段。
RoI Pooling输出固定尺寸的RoI特征图(尺度降为1的简易版SPP)
FCs映射得到固定维度的特征向量
对特征向量分别进行分类(获得K+1维结果,类别+背景)和回归(获得K4维结果,每类的box定位)
注意这个观点:为什么说Fast R-CNN的训练将多阶段压缩为单阶段?之前的R-CNN是先region proposal,在SVM分类,再回归box三部分,这里第一阶段不变,但是训练部分的后两个阶段被合并了。理解:R-CNN训练了SVM和FC分别用于分类和回归,而Fast R-CNN只训练了一个网络,既能分类也能回归,两者相互促进。虽然看上去网络的最后分类和回归分流并列了,但是两者的学习是共同反馈,指导网络参数的调整的,优化的是一个网络,所以时间和内存开销都小了。(Faster R-CNN甚至把非训练的 region proposal也放到网络上去了,三位一体)

2.1 The RoI pooling layer
RoI pooling就是level=1的SPP,在每个bin内作最大值池化。略有不同的是,SPP计算了pooling的步长,池化利用了图像每个像素;而RoI pooling则计算bin的尺寸后,直接在bin内取最大值池化,相当于stride=size(bin),这样势必会舍掉很多边缘像素(于是有了Rolalign)
一个认识:有没有量化误差、够不够精确,看的不单是简单的像素级丢失,而是输出对于输入的响应。比如RoIpooling和RoIAlign相比,将输入进行像素或者尺寸的变化,后者的变化很及时和明显,而前者就显得迟钝和不灵敏(因为像素丢失和maxpooling,相比之下卷积计算就比maxpooling好一些)。再比如SPP用到了每个像素,会比RoIpooling灵敏,但是如果特征图尺寸20.520.5,显然也不如RoIAlign。
2.2 Initializing from pre-trained networks
从预训练模型的基础上开始实验,需要做三个改动:
最后一个池化层(后面就是FC了)替换为RoI pooling层,尺寸设置根据后面FC的匹配来确定
将最后一个FC层替换为两个并行的子层,分别用于分类和回归
网络设置两个输入:图片及其RoI。(注意,在Fast R-CNN,region proposal还不属于网络,它是SS算法预处理的结果)
2.3 Fine-tuning for detection
通过反向传播可以更新网络的所有权重参数,这一点是SPPnet做不到的(没看懂为什么);提出有效利用共享参数训练,也无非是借鉴SPP,先提取特征图,再提取RoI,每张图的卷积特征是一样的,所以这些RoI共享计算;三阶段的合并单模型学习。
Multi-task loss

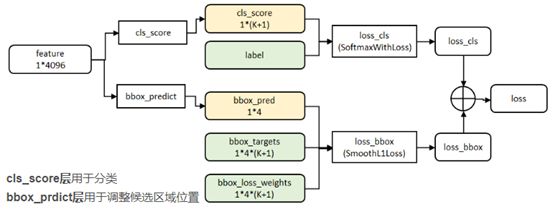
由于将分类和回归任务统一训练,损失函数必然是多任务的,具体形式如下:
![]()
![]()
先看损失函数的输入,p是RoI特征向量的分类结果,由softmax输出得到的 K+1维的类概率向量,通过下标索引p0,...pk;u,v分别是RoI的ground truth label的类别和坐标; tu是真实类别u的实际回归(预测)结果;(坐标归一化过)
右边分为两个函数:第一个是类别损失,
![]()
,表征真实类别概率的负对数损失;第二项是定位损失,其中[u>=1]函数值在u>=1时取1,否则为0,背景类的u索引为0,第0类,这样做可以在输入RoI为背景时不计算定位损失(本来就没有物体),对于回归的定位损失函数:
![]()
![]()
![]()
输入是真实坐标v和预测的坐标tu,可以看出只计算正确类的定位损失,这样一来将分类和定位的误差严格区分开了。送过来的RoI不止一个,所以用i表示,计算方式是平滑的鲁棒L1损失:-
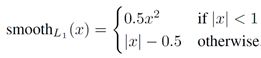
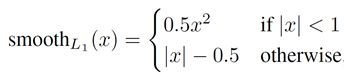
该损失对异常值相比L2损失(均方差)更加不敏感,当回归目标无界限限制时,L2训练需要精细地调整学习率防止梯度爆炸,而此处采用的方法则不那么敏感。(对比:YOLO采用的就是L2,因为他的回归是有界的,不会超出一个grid cell范围)
还有一个参数lambda,用于调整分类和回归损失的比重。
针对这个分离分类和回归的损失函数,作者还补充了一个CVPR的论文,其使用的是相关损失训练,而且还是双网络进行分类和回归,这个思想和这里的不一样,Fast R-CNN只是loss分离了分类和回归,但是指导的是同一个网络。
Mini-batch sampling
采用的batch为128,在R-CNN中有1:3的正负样本构成,这里类似,128来自两张图,每张提取64个RoI。其中正样本占25%,从iou大于0.5的RoI中采样,这些RoI中包含物体,标记为u>1,会参与计算定位误差;剩下75%RoI从iou在[0.1,0.5)之间的负样本采样,仍是1:3(正样本比例保持较小,适应实际情况,降低假阳性误检),它们标记u=0不参与定位损失计算。iou小于0.1的可以考虑进行难分样本挖掘。除了0.5的概率进行水平翻转外,未采取其他的数据增强。
Back-propogation through RoI pooling layers
关于RoI Max pooling的反向求导没看太明白,这里有讲,用得到的时候看一下:https://blog.csdn.net/yzf0011/article/details/76758337
SGD hyper-parameters
2.4 Scale invariance
提供了两种尺度不变性学习方法:
强制学习。训练和检测阶段,将图片变换到固定尺寸,ground truth在同一标准(size)下有了多尺度的特点,直接从图像中学习物体的尺度变化特性。
图像金字塔。通过下采样或差值的方法,改变原图的尺寸,为网络提供变化尺度的输入。这在数据量不大的小样本情况下也是一种数据增强方式。
3、4 Fast R-CNN detection & Main result
3.1 Truncated SVD for faster detection(截断SVD)
这里描述的是,在检测任务中由于大量的RoI提出,导致FC层的计算非常大(大于卷积层的运算)几乎占到forward的一半,因此作者借鉴了其他论文采用截断SVD进行模型的压缩和加速,取代了连接权W,减少了参数。(数学性比较强,暂时不分析)
后面就作者展示的效果来看还是很喜人的,mAP掉了0.3%,但提速了30%左右,大大加速了fc层。(在有FC层的网络中可以借鉴截断SVD)
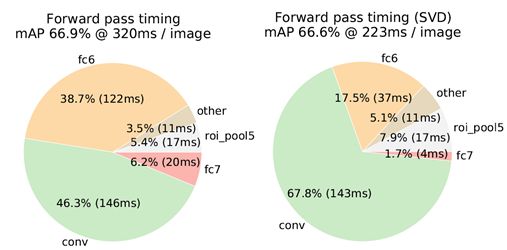
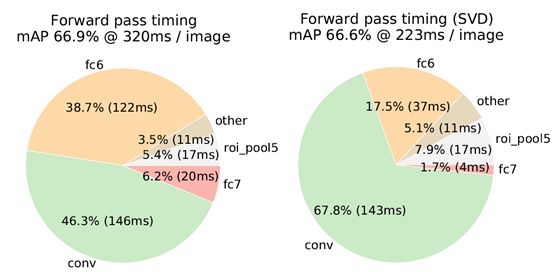
fine-tune的位置:fine-tine当然有效果,但是并非所有层都应该进行学习。作者经过实验发现,conv1学习与否对网络的精度提升并无影响,因此需要选择合适的fie-tune层。
5、Design evaluation
5.1 Does multi-task training help?
实验和数据说话:


SML是三个不同深度的基础模型,第1,2列,3,4列分别作对比。第一列的loss只有分类损失,第二列是多任务损失,但是不输出bbox,进行分类实验对比,发现加了回归定位损失指导的模型对分类任务完成更好;第三列是拆分loss分阶段训练,第四列是多任务损失联合训练,进行回归对比实验,发现联合loss的效果比分阶段的效果好。
结论:分类和回归的损失同时用于训练,共同指导参数优化时,可以起到相互补充、改善模型精度的效果;多任务共同训练的效果,要比单任务分阶段训练的效果好。
5.2 Scale invariance : to brute force or finesse?
关于选择单尺度还是多尺度训练,先给出结论:多尺度训练的效果当然比单尺度好,但是越是对于深层网络而言,单尺度训练反而可以获得更好的时间和速度的折衷。
实验数据如下:
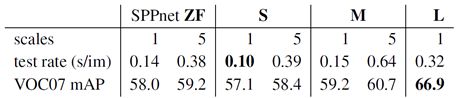

左边的SPPnet是一个类似于S模型的小模型。纵向对比可以看出,多尺度训练的效果总是强于单尺度的;横向对比计算耗时依次为:2.7倍、3.9倍、4.6倍,而精度提升为:1.2倍、1.3倍、1.5倍,相比于时间的增长,作者认为深度网络的单尺度训练折中比较好(这里的数据看不出来吧....),解释是:深度网络更加擅长学习尺度的不变性,喂给单尺度输入就能学习较好了,多尺度的锦上添花相比其速度变慢来说退居次位。
5.3 Do we need more training data?
5.4 Do SVMs outperform softmax?
数据就不用贴了,肯定是比svm好。作者认为原因是,softmax由其表达式知输出和为1,因此每个标量(RoI打分)之间引入竞争机制, winner-take-all,进一步拉大了准确回归和较差回归的差距,使得结果更好。
5.5 Are more proposal always better?
更多的region未必有效,mAP反而下降。