PostgreSQL数据库管理-第二章体系结构
PostgreSQL数据库管理
第二章体系结构
概述
PostgreSQL是一个功能非常强大的、源代码开放的客户/服务器关系型数据库管理系统(RDBMS)。支持丰富的数据类型(如JSON和JSONB类型,数组类型)和自定义类型。PostgreSQL内存页面的默认大小是8kB。
PostgreSQL有以下主要特性:
1良好支持SQL语言,支持ACID、关联完整性、数据库事务、Unicode多国语言。
2高并发设计,读和写互不阻塞
3 支持大量类型的数据库模型:关系型,文档型(如JSON和JSONB类型,数组类型),Key/value类型。
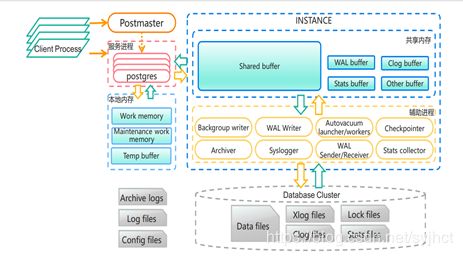
2.1 PostgreSQL进程结构

PostgreSQL是一用户一进程的客户端/服务器的应用程序。数据库启动时会启动若干个进程,其中有postmaster(守护进程)、postgres(服务进程)、syslogger、checkpointer、bgwriter、walwriter等辅助进程。
2.1.1 postmaster(守护进程)
postmaster(守护进程)主要职责有:
1. 数据库的启停
2. 监听客户端连接
3. 为每个客户端连接fork单独的postgres服务进程
4. 当postgres服务进程出错时进行修复
5. 管理数据文件
6. 管理与数据库运行相关的辅助进程
2.1.2 服务进程Postgres
服务进程Postgres接受并执行客户端(比如psql,或用户应用程序通过JDBC等接口)发送的命令(交互式SQL查询)。它在底层模块(如存储、事务管理、索引等)之上调用各个主要的功能模块(如编译器、优化器、执行器等),完成客户端的各种数据库操作,并返回执行结果。
2.1.3 Syslogger(系统日志进程)
在配置文件Postgresql.conf中有很多与日志相关的参数,其中只有在参数logging_collect设置为on时,主进程才会启动syslogger辅助进程。
– 采集PostgreSQL的运行状态,并将运行日志写入日志文件
– logging_collector参数为on时启动,不建议关闭
– log_directory设定日志目录
– log_destination设定日志输出方式,甚至格式
– log_filename设定日志文件名
– log_truncate_on_rotation设定是否重复循环使用且删除日志
– log_rotation_age设定循环时间
– log_rotation_size设定循环的日志尺寸上线
2.1.6 辅助进程Checkpoint:
– 用于保证数据库的一致性
– 它会触发bgwriter和wal writer动作
– 拥有多个参数控制其启动的间隔
2.1.7 辅助进程Backgroup writer(后台写进程):
在 PostgreSQL 中, Bgwriter 辅助进程是把共享内存中的脏页写到磁盘上的进程。当往数据库中插人或更新数据时,并不会马上把数据持久化到数据文件中。这主要是为了提高插人、更新、删除数据的性能二 Bgwriter 辅助进程可周期性地把内存中的脏数据刷新到磁盘中,刷脏数据既不能太快,也不能太慢如果一个数据块被改变了多次,而此时刷新又太快,那么这些改变就每次都会被保存到磁盘中,这会导致 1 / 0 次数增多。在刷新太慢的情况下,若有新的查询或更新需要使用内存来保存从磁盘中读取的数据块,由于没有空闲空间来存储这些数据块,就需要把内存腾出来,即先把一些内存中的脏页写到磁盘中,这样就会导致查询或更新需要等更长的时间,自然也就降低了性能 L 面提到的这些机制由以” ' bgwriter _ ”开头的配置参数来控制
– 工作任务是将shared buffer中的脏数据页写到磁盘文件中
– 使用LRU算法进行清理脏页
– 平时多在休眠,被激活时工作
2.1.8 辅助进程WAL writer(预写式日志):
WAL是WriteAheadLog的缩写,中文称之为预写式日志。WALlog也被简称为xlog。
WalWriter进程就是写WAL日志的进程。预写式日志的概念就是在修改数据之前,必须要把这些修改操作记录到磁盘中,这样后面更新实际数据时,就不需要实时地把数据持久化到文件中了。即使机器突然宕机或数据库异常退出,导致一部分内存中的脏数据没有及时地刷新到文件中,在数据库重启后,通过读取WAL日志,并把最后一.部分的WAL日志重新执行一遍,就可以恢复到宕机时的状态。
WAL日志保存在pg_ xlog 下。每个xlog文件默认是16MB,为了满足恢复要求,在xlog 目录下会产生多个WAL日志,这样就可保证在宕机后,未持久化的数据都可以通过WAL日志来恢复,那些不需要的WAL日志将会被自动覆盖。
– 将预写日志写入磁盘文件
– 触发时机:
• WAL BUFFER满了
• 事务commit时;
• WAL writer进程到达间歇时间时;
• checkpoint发生时;
2.1.9 辅助进程Archiver(归档):
– 用于将写满的WAL日志文件转移到归档目录,该进程只有在归档模式才会启用
WAL日志会被循环使用,也就是说,较早时间的WAL日志会被覆盖。PgArch归档进程会在覆盖前把WAL日志备份出来。PostgreSQL从8.X版本开始提供了PITR(Point-In-Time-Recoery)技术, 通俗的说,就是在对数据库进行过一次全量备份后,该技术将备份时间点之后的WAL日志通过归档进行备份,使用数据库的全量备份再加上后面产生的WAL日志,即可把数据库向前推到全量备份后的任意-一个时间点了。
2.1.10 辅助进程Statistics Collector(统计收集进程):
– 统计信息的收集进程。 收集表和索引的空间信息和元组信息等,甚至是表的访问信息。收集到的信息除了能被优化器使用以外,还有autovaccum也能利用,甚至给数据库管理员作为数据库管理的参考信息
2.1.11 辅助进程 Autovacuum launcher/workers(系统自动清理进程):
– 自动清理垃圾回收进程
– 当参数autovacuum设为on的时候启用自动清理功能
– Launcher为清理的守护进程,每次启动的时候会调用一个或多个worker
– Worker是负责真正清理工作的进程,由autovacuum_max_workers参数设定其数量
在PostgreSQL数据库中,对表进行DELETE操作后,旧的数据并不会立即被删除。并且,在更新数据时,也并不会在旧的数据上做更新,而是新生成-行数据。这在前面“锁”相关章节中已有所介绍,称之为多版本。此时,旧的数据只是被标识为删除状态,只有在没有并发的其他事务读到这些旧数据时,它们才会被清除掉。这个清除工作就是由AutoVacuum进程来完成的。
2.2 PostgreSQL内存结构
PostgreSQL启动后,会生成-块共享内存,共享内存主要用做数据块的缓冲区,以便提高读写性能。WAL日志缓冲区和CLOG(Commit log)缓冲区也存在于共享内存中。除此以外,一些全局信息也保存在共享内存中,如进程信息、锁的信息、全局统计信息,等等。
2.2.1 共享内存
相当于oracle的SGA是一组共享内存结构, 被所有的服务和后台进程所共享。当数据库实例启动时,系统全局区内存被自动分配。当数据库实例关闭时,SGA内存被回收。 SGA是占用内存最大的一个区域,同时也是影响数据库性能的重要因素。
Shared Buffer:
-用于缓存表和索引|的数据块
一数据的读写都是直接对BUFFER操作的, 若所需的块不再缓存中,则需要从磁盘中读取
-在buffer中被修改过的, 但又没有写到磁盘文件中的块被称之为脏块
-由shared buffers参数控制尺寸
WAL(Write Ahead Log) Buffer:
-预写日志缓存用于缓存增删改等写操作产生的事务日志
-由wal buffers参数控制尺寸
Clog Buffer:
-Commit Log Buffer是记录事务状态的日志缓存
2.2.2 本地内存
相当于Oracle的PGA
一个PGA是一块独占内存区域,Oracle进程以专有的方式用它来存放数据和控制信息。当Oracle进程启动时,PGA也就由Oracle数据库创建了。当用户进程连接到数据库并创建一个对应的会话时,Oracle服务进程会为这个用户专门设置一个PGA区,用来存储这个用户会话的相关内容。当这个用户会话终止时,系统会自动释放这个PGA区所占用的内存。
本地内存是服务器进程独占的内存结构,每个postgre子进程都会分配一-小块相应内存空间,随着连接会话的增加而增加,它不属于实例的一部分
work_ mem:用于排序的内存
maintenance work mem:用于内部运维工作的内存,如VACUUM垃圾回收、创建和重建索引等等
temp_ buffers: 用于存储临时表的数据
2.3 PostgreSQL内存目录结构
PostgreSQL的层级结构
1.逻辑层次关系
Database Cluster(instance)--》Database--》Schema--》Objects(Table)-->Tuples
2.物理层次关系
Database Cluster --》Tablespaces --》Files --》 Blocks

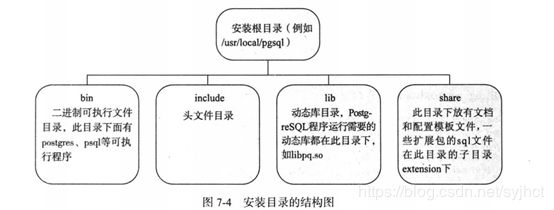
2.3.1 安装目录结构
PGHOME=/opt/pgsql11.4 是PostgreSQL安装软件的目录。
2.3.1 数据目录结构
一般使用环境变量PGDATA指向数据目录的根目录。这个目录是在安装时指定的,所以在安装时需要指定一个合适的目录作为数据目录的根目录,而且,每一个数据库实例都需要有这么一个目录。目录的初始化是使用initdb来完成的。完成后,这数据根目录下就会生成
三个配置文件。
postgresql. conf:数据库实例的主配置文件,基本上所有的配置参数都在此文件中。
pg_ hba.conf: 认证配置文件,配置了允许哪些IP的主机访问数据库,认证的方法是什么等信息。
pg_ ident.conf: “ident”认证方式的用户映射文件。
1 总体目录结构
base,global,logfile,pg_clog,pg_multixact,pg_notify
,pg_serial,pg_snapshots,pg_stat_tmp,pg_subtrans
,pg_tblspc,pg_twophase,PG_VERSION,pg_xlog
,postgresql.conf,pg_hba.conf,pg_ident.conf
2 base 目录实体文件目录
- base 目录用于存放数据库的所有实体文件。
- 下属子目录均以数据库OID命名。
- 数据库子目录下是以对象OID命名的文件。
- PG VERSION是当前数据库数据格式对应的版本号。
名字以 fsm结尾的文件是数据文件对应的FSM(free
space map)文件,用位图方式来标识哪些block是空
闲的。
- 以vm结尾的文件是数据文件对应的VM(visibility
map),在做多版本并发控制时是通过在元组头上标识
“已无效”来实现删除或更新的,最后通过VACUUM
功能来清理无效数据回收空闲空间。
3 全局共享目录global
■pg_ control
用于存储全局控制信息
■pg_ filenode.map
用于将当前目录下系统表的OID与具体文件名
进行硬编码映射(每个用户创建的数据库目录
下也有同名文件)。
■pg_ internal.init
用于缓存系统表,加快系统表读取速度(每个
用户创建的数据库目录下也有同名文件)。
■全局系统表文件
数字命名的文件,用于存储系统表的内容。它;
们在pg_ class里的relfilenode都为0, 是靠
pg_ filenode.map将OID与文件硬编码映射。
4 其他常用目录
- pg_ wal,WAL日志目录,非常重要
- pg_ xact,Commit log目录,非常重要。V9版本以前为pg_ clog目录
- pg_ hba.conf客户端认证配置文件, 可以配置客户的连接协议、加密方式、ACL等等
- postgresql.conf 该database cluster的配置文件,文本格式
- postgresql.auto.conf,也是参数配置文件,所有通过alter命令修改的命令,都会保存在这个文件中,该文件中的参数将会覆盖,postgresql.conf文件相同参数的值,该文件为二进制
- postmaster.pid,Postmaster主进程的操作系统PID,数据库实例正常启动以后就会生成该文件。
2.3.4 表空间目录

在创建完一个表空间后,会在表空间的根目录下生成带有“Catalog version"的子目
录,如:
CREATE TABLESPACE tbs01 LOCATION ' /home/osdba/tbs01";
同时也会生成-一个子目录名“PG, 9.3_ 201306121":
osdbatosdba-laptop:~s 1s -1 /home/osdba/tbs01
total 4
drw------ 3 osdba osdba 4096 10月19 14:29 PG_ 9.3_ 201306121
子目录名“PG 93 201306121” 中的“*201306121” 就是“ Catalog version,“ Catalog version"
可以由pg_ controldata 命令查询出来:
osdbadosdba-laptop: -/pgsql/bin5 Pg_ controldata
P9_ control version number: 937
Catalog version number: 201306121
Database system identifier: 5925271200006401779
Database cluster state: in production
在“PG 9.3 _201306121” 子目录下,又会有一-些子目录,这些子目录的名称就是数据库
的oid,如下:
osdba@osdba-laptop:-$ 1s -1 /home/osdba/tbs01/PG_ 9.3_ 201306121/
total 4
drw------ 2 osdba osdba 4096 10月19 14:29 16384
比如,上面的“16384” 子目录,就是“osdba"数据库的oid,如下:
osdbaf select oid, datname from P9_ database;
oid datname
1 template1
12065 template0
12070 postgres
16384 oadba