以太坊的挖矿和难度调整过程
以太坊挖矿过程
在比特币的挖矿过程中,仅仅需要较为简单的哈希运算,而不需要额外的计算资源(内存等),于是比特币的挖矿过程逐渐成为了算力的竞争,于是就出现了ASIC矿机,这种矿机相比于个人计算机,进行普通的计算,其算力是个人计算机的数千倍,刚好适用于进行比特币中的挖矿,因此,普通人要想挖矿,就得有更专业的设备,挖矿这一行业都出现了中心化的现象,这与比特币当初设计之初的去中心化理念背道而驰了。
于是,设计以太坊挖矿的时候,采用了全新的挖矿过程以做到ASIC Resistance。ASIC只能进行运算,却没有额外存储空间,于是以太坊在挖矿过程中设计了两个数据结构,分别为Cache和dataset。其中Cache是16M大小,而dataset是1G大小,对于矿工来说,每次选取一个nonce之后的挖矿操作,都要从dataset中读取数据,这就要求矿机有存储能力,挖矿过程中引入了读取内存的操作,这就极大的降低了ASIC矿机的算力,使其挖矿的优势不那么明显,而普通的个人计算机也能进行挖矿。具体的挖矿过程如下:
- 根据当前区块信息生成一个Seed种子。
- 根据Seed种子生成16M大小的Cache,Cache是一个List结构,其数据前后相关。
- 根据Cache来生成1G大小的Dataset(又称为Dag)。
- 矿机每次选取一个Nonce之后,从Dataset中读取两个数进行挖矿测试,直到找到合适的Nonce。
区块链中每30000个区块的时候,Cache和Dataset的大小都会增加 1128 1 128 ,也就是说Cache会增加128K,而Dataset会增加8M。生成Cache的算法如下:
def mkcache(cache_size, seed):
cache = [hash(seed)]
for i in range(1,cache_size):
cache.append(hash[cache[-1]])
return cachedataset的生成来源于cache,具体来说,dataset[i]个元素的生成需要cache和cache[i]的参与。dataset中第i个元素的生成代码如下:
def cal_dataset_i(cahce, i):# 计算dataset[i]
cache_size = cache.size
mix = hash(cache[i%cache_size]^i)# cache远远小于dataset,让i也参与运算,从而使得mix不会重复
for j in range(256):
cache_index = get_int(mix);
mix = make_item(mix,cache[cache_index%cache_size])
return hash(mix)上述代码是伪代码,省略了大部分细节,重点在于展示原理。
- 先通过cache中的第i%cache_size个元素生成初始的mix,因为两个不同的dataset元素可能对应同一个cache中的元素,为了保证每个初始的mix都不同,注意到i也参与了哈希计算。
- 随后循环256次,每次通过get_int来根据当前的mix值求得下一个要访问的cache元素的下标,用这个cache元素和mix通过make_item求得新的mix值。注意到由于初始的mix值都不同,所以访问cache的序列也都是不同的。
最终返回mix的哈希值,得到第i个dataset中的元素。 - 多次调用这个函数,就可以得到完整的dataset。
通过cache生成dataset的元素时,下一个用到的cache中的元素的位置是通过当前用到的cache的元素的值计算得到的,这样具体的访问顺序事先不可预知,满足伪随机性。生称dataset的代码如下:
def calc_dataset(full_size, cache):
return [calc_dataset_item(cache,i) for i in range(full_size)]生成dataset之后矿工就可以开始挖矿,根据特定的过程计算出一个哈希值,其代码如下所示。其中的循环64次并没有额外的原因,就是想增加挖矿过程中的访问内存操作。矿工为了增加挖矿速度,就必须要将dataset存储在内存中。
# 根据nonce计算出一个哈希值
def get_hash_value(header, nonce, full_size, dataset):
hash_value = hash(header, nonce);
for i in range(64):
dataset_index = get_int(hash_value )%full_size
hash_value = make_item(hash_value , dataset[dataset_index)
hash_value = make_item(hash_value , dataset[dataset_index+1])
return hash(hash_value )如果一个nonce不合适,就需要更换一个nonce,直到找到合适的nonce,整个挖矿过程伪代码如下:
def mine(full_size, dataset, header, target):
max_nonce = 2**64
nonce = random.randint(0, max_nonce )
while get_hash_value(header, nonce, full_size, dataset) > target:
nonce = (nonce+1)%max_nonce
return nonce为什么要挖矿中设计cache呢,貌似矿工挖矿的时候根本没有用到cache,为什么要多此一举?这是为了方便轻节点对区块进行验证。对于轻节点来说,不可能存储很大的dataset,但是轻节点可以通过存储cache,验证某个区块块头时,根据cache生成dataset中某个元素,随后验证区块的合法性。轻节点验证区块合法性的伪代码如下:
def varify(header, nonce, full_size, cache):
hash_value = hash(header, nonce)
for i in range(64):
index = get_int(hash_value)%full_size
hash_value = hash(hash_value, cal_dataset_i(cache,index))# 计算生成dataset中的数据
hash_value = hash(hash_value,cal_dataset_i(cache,index+1))
return hash(hash_value)矿工需要验证大量的nonce,若每次都要从16M的cache中重新生成,那么挖矿的效率就大打折扣,而且会有大量的重复计算:随机选取的dataset的元素中有很多是重复的,可能是之前尝试别的nonce时用过的。所以,矿工采取以空间换时间的策略,把整个dataset保存下来。而轻节点由于只验证一个nonce,验证的时候就直接生成要用到的dataset中的元素就行了。
以太坊挖矿难度调整
以太坊中的区块的难度调整公式如下图所示。

参数说明
区块链难度调整中,创始块的难度被设置为 D0=131072 D 0 = 131072 ,此后每个区块的难度都与其父区块的难度相关。D(H)是本区块的难度,由 P(H)Hd+x×ζ2 P ( H ) H d + x × ζ 2 和难度炸弹 ϵ ϵ 构成。
P(H)Hd P ( H ) H d 为父区块的难度,每个区块的难度都是在父区块难度的基础上进行调整。
x×ζ2 x × ζ 2 用于自适应调节出块难度,维持稳定的出块速度。
- ϵ ϵ 表示难度炸弹。
- 难度有最低下限,即不能低于 D0=131072 D 0 = 131072
其中 x x 和 ϵ2 ϵ 2 的计算方式如下图所示。

- x x 是父区块难度的 12048 1 2048 的取整,是调整的单位。
- ϵ ϵ 是调整系数,其小只能是-99。
- y的取值依赖于父区块是否包含叔父区块,如果包含,则y=2,否则y=1。
- HS H S 是本区块的时间戳, P(H)Hs P ( H ) H s 是父区块的时间戳,单位为秒,并且 HS>P(H)Hs H S > P ( H ) H s 。
- 难度降低的上界设置为−99 ,主要是应对被黑客攻击或其他目前想不到的黑天鹅事件。
假设当父区块不带叔父区块的时候(y=1),调整过程如下:
- 出块时间在[1,8]之间,出块时间过短,难度调大一个单位。
- 出块时间在[9,17]之间,出块时间可以接受,难度保持不变。
- 出块时间在[18,26]之间,出块时间过长,难度调小一个单位。
- …
这里发现,出块时间变长,区块的整体难度就会调小,假若有的矿工,故意将区块的时间戳改的比较晚,那么是不是就可以抢先发布区块呢?比如说将时间戳延迟写15秒,会怎么样呢?这样就会导致该矿工计算出来的难度比别的矿工计算的难度低,其他矿工15秒发布一个区块,而该矿工可以在10秒内发布区块,可以拿到区块奖励。但是问题在于假如刚好也有别的区块在10秒内发布了区块,此时根据POW的规则,另外一个矿工发布的区块难度更大,因此其他矿工会以最大工作量标准,选择15秒内挖出的区块所在的链作为主链,而该矿工发布的区块便成了叔父区块。
难度炸弹计算公式如下图所示。

ϵ ϵ 是2的指数函数,每十万个块扩大一倍,后期增长非常快,这就是难度“炸弹”的由来。
H′i H i ′ 称为fake block number,由真正的block number Hi H i 减少三百万得到。之所以减少三百万,是因为目前proof of stake的工作量证明方式还存在一些问题,pos协议涉及不够完善,但是难度炸弹已经导致挖矿时间变成了30秒左右,为了减小难度,就会减去三百万。
设置难度炸弹的原因是要降低迁移到PoS协议时发生fork的风险,假若矿工联合起来抵制POS的工作量证明模式,那就会导致以太坊产生硬分叉;有了难度炸弹,挖矿难度越来越大,矿工就有意愿迁移到PoS协议上了。难度炸弹的威力,可以通过下图看出。
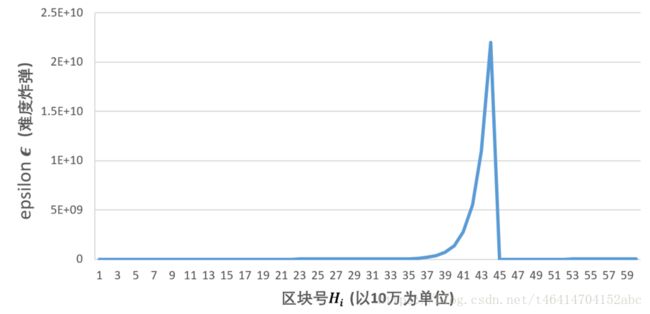
区块数量到370万之后,挖矿难度突然递增,到430万时,难度已经非常之大了,这时候挖矿时间已经变为为30秒,但是POS协议还没有完善,于是以太坊将挖矿难度公式进行调整,使得每次计算时,当前区块号减去三百万,这样就降低了挖矿难度,并且在这个时期,对以太坊出块奖励进行了调整,从原来的5个ETH变为3个ETH。
以太坊中难度计算公式如下图所示,由于目前处于以太坊发展的Metropolis中的Byzantium阶段,所以难度计算公式的函数名称为calcDifficultyByzantium
// calcDifficultyByzantium is the difficulty adjustment algorithm. It returns
// the difficulty that a new block should have when created at time given the
// parent block's time and difficulty. The calculation uses the Byzantium rules.
func calcDifficultyByzantium(time uint64, parent *types.Header) *big.Int {
// https://github.com/ethereum/EIPs/issues/100.
// algorithm:这里给出了难度计算公式的整体注释
// diff = (parent_diff +
// (parent_diff / 2048 * max((2 if len(parent.uncles) else 1)
// - ((timestamp - parent.timestamp) // 9), -99))) + 2^(periodCount - 2)
// 获取当前时间和父区块的时间戳
bigTime := new(big.Int).SetUint64(time)
bigParentTime := new(big.Int).Set(parent.Time)
// holds intermediate values to make the algo easier to read & audit
x := new(big.Int)
y := new(big.Int)
//这里求出当前区块时间戳和父区块的时间戳,然后求差之后除以9
// (2 if len(parent_uncles) else 1)-(block_timestamp - parent_timestamp) // 9
x.Sub(bigTime, bigParentTime)
x.Div(x, big9)
if parent.UncleHash == types.EmptyUncleHash {
x.Sub(big1, x)
} else {
x.Sub(big2, x)
}
// max((2 if len(parent_uncles) else 1)-(block_timestamp - parent_timestamp) // 9, -99)
if x.Cmp(bigMinus99) < 0 {
x.Set(bigMinus99)
}
// parent_diff + (parent_diff / 2048 * max((2 if len(parent.uncles) else 1) -
//((timestamp - parent.timestamp) // 9), -99))
y.Div(parent.Difficulty, params.DifficultyBoundDivisor)
x.Mul(y, x)
x.Add(parent.Difficulty, x)
// minimum difficulty can ever be (before exponential factor)
// MinumumDifficulty = big.NewInt(131072)
if x.Cmp(params.MinimumDifficulty) < 0 {
x.Set(params.MinimumDifficulty)
}
// calculate a fake block number for the ice-age delay:
// https://github.com/ethereum/EIPs/pull/669
// fake_block_number = max(0, block.number - 3_000_000)
fakeBlockNumber := new(big.Int)
if parent.Number.Cmp(big2999999) >= 0 {
// Note, parent is 1 less than the actual block number
fakeBlockNumber = fakeBlockNumber.Sub(parent.Number, big2999999)
}
// for the exponential factor
periodCount := fakeBlockNumber
periodCount.Div(periodCount, expDiffPeriod)
// the exponential factor, commonly referred to as "the bomb"
// diff = diff + 2^(periodCount - 2)
if periodCount.Cmp(big1) > 0 {
y.Sub(periodCount, big2)
y.Exp(big2, y, nil)
x.Add(x, y)
}
return x
}至此,以太坊的挖矿过程和难度调整过程告一段落。