MySQL(十):InnoDB 索引与算法(上篇)
文章目录
- 1、简述
- 2、InnoDB 存储引擎支持的索引
- 2.1、聚集索引(Clustered Indexes)和 二级索引(Secondary Index)
- 2.2、聚集索引是如何实现快速查询的
- 2.3、二级索引与聚簇索引的关系
- 2.4、全文索引(Fulltext Indexes)
- 2.5、InnoDB索引的物理结构
- 2.6、排序索引构建
- 2.6.1、为将来的索引增长保留B-tree页面空间
- 2.6.2、排序索引构建和全文本索引支持
- 2.6.3、排序索引构建和压缩表
- 2.6.4、排序索引构建和重做日志记录
- 2.6.5、排序索引构建和优化器统计
- 3、参考文献
1、简述
索引是存储引擎用于快速检索记录的的一种数据结构。索引并不是万能的,在合适的场景使用合适的索引才能真正发挥索引的作用,反之会带来很糟糕的影响。当数据量较小且负载较低时,添加索引反而多性能造成影响。如果索引太多,反而降低记录检索的性能。所以,只有合理的使用索引才能达到我们期望的结果。
很多开发人员往往对数据库都只是简单的应用,认为数据库的优化交给DBA即可,甚至有些人并不知道索引的存在。那么怎么才能合理的使用索引呢?首先清晰正确的认识索引是很有必要的,接下来跟随笔者由浅入深的认识索引、理解索引,从而正确的使用索引。
2、InnoDB 存储引擎支持的索引
InnoDB 存储引擎支持的索引分为以下几种,聚集索引(Clustered Indexes)、二级索引(Secondary Index)又称普通索引、非聚集索引、全文索引(Fulltext Indexes)。

2.1、聚集索引(Clustered Indexes)和 二级索引(Secondary Index)
每个InnoDB表都有一个特殊的索引,称为聚簇索引,用于存储行数据。通常,聚簇索引与主键同义。为了从查询,插入和其他数据库操作中获得最佳性能,很有必要了解InnoDB如何使用聚簇索引为每个表优化最常见的查找和DML操作。
1、当您在表上定义PRIMARY KEY时,InnoDB会将其用作聚簇索引。如果没有逻辑唯一且非空的列时,可以添加一个新的自动递增列作为主键。
2、每个表都有一个主键;如果CREATE TABLE没有指定一个,则使用第一个非NULL唯一键,否则,一个6字节隐藏的“行ID”字段会自动添加到表结构中并用作主键。
3、“行数据”(非主键字段)存储在主键索引结构中,也称为“聚集键”。该索引结构被存储到PRIMARY KEY字段中,并且行数据是附加到该键的值。
2.2、聚集索引是如何实现快速查询的
通过聚集索引访问行是很快的,因为聚集索引直接指向包含所有行的数据页 ( data page )。如果表很大,与那种索引页与数据页分离的 MyISAM 存储引擎相比, 聚簇索引体系结构通常可以节省磁盘 I/O 操作。
2.3、二级索引与聚簇索引的关系
除聚集索引以外的所有索引都称为辅助索引(二级索引)。在InnoDB中,二级索引中的每个记录都包含该行的主键列以及为二级索引指定的列。 InnoDB使用此主键值在聚集索引中搜索行。
如果主键较长,则辅助索引将使用更多空间,因此减小主键的长度是有利的。
2.4、全文索引(Fulltext Indexes)
FULLTEXT索引是在基于文本的列(CHAR,VARCHAR或TEXT列)上创建的,以帮助加快对这些列中包含的数据的查询和DML操作。
FULLTEXT索引定义为CREATE TABLE语句的一部分,或使用ALTER TABLE或CREATE INDEX添加到现有表中。
可以使用 MATCH() … AGAINST 语法进行全文检索。
在此不对全文索引深度分析,笔者会另起文章深入分析。
2.5、InnoDB索引的物理结构
除了空间索引(地理位置索引),InnoDB索引都是 B-tree 数据结构。空间索引使用 R-tree, R-tree 是用于索引多维数据的专用数据结构。索引记录存储在其B-tree 或 R-tree 数据结构的叶页中。索引页的默认大小为16KB。
当新记录插入到InnoDB聚集索引中时,InnoDB尝试使页面的1/16空闲,以备将来插入和更新索引记录。如果按顺序插入索引记录(升序或降序),则所得的索引页约为15/16。如果以随机顺序插入记录,则页面的容量为1/2到15/16。
InnoDB在创建或重建B树索引时执行批量加载。这种索引创建方法称为排序索引构建。innodb_fill_factor 配置选项定义了在排序索引构建期间填充的每个B树页面上的空间百分比,剩余的空间供将来索引增长使用。空间索引不支持排序索引构建。
如果InnoDB索引页的填充因子低于MERGE_THRESHOLD,则InnoDB尝试收缩索引树以释放页面,如果未指定,默认值为50%。MERGE_THRESHOLD设置适用于B树索引和R树索引。
可以通过在初始化MySQL实例之前设置innodb_page_size配置选项来定义MySQL实例中所有InnoDB表空间的页面大小。一旦定义实例的页面大小后,如果不重新初始化实例就无法更改它。支持的大小为64KB,32KB,16KB(默认),8KB和4KB。
有一点需要注意,使用特定InnoDB页面大小的MySQL实例不能使用来自使用不同页面大小的实例的数据文件或日志文件。
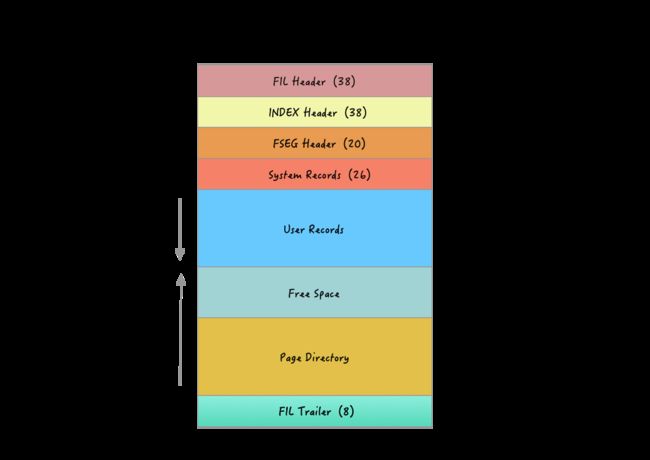
页面结构的主要部分是:
-
FIL头和尾:这是所有页面类型的典型和共同之处。对于INDEX页面而言,在某些方面有些独特,那就是FIL标头中的“上一页”和“下一页”指针指向同一索引级别的前一页和后一页,并根据索引的键升序排列。这形成了所有页面的双向链接列表。
-
INDEX Header:包含许多与INDEX页和记录管理相关的字段。下文详细介绍。
-
FSEG Header:如InnoDB空间文件中的页面管理中所述,索引根页面的FSEG标头包含指向该索引使用的文件段的指针。其他所有索引页的FSEG标头均未使用且填充为零。
-
System Records:InnoDB在每个页面中都有两个系统记录,分别称为infimum和supremum。这些记录存储在页面中的固定位置,因此始终可以根据页面中的字节偏移量直接找到它们。
-
User Records:实际数据。每个记录都有一个可变宽度的标题和实际的列数据本身。标头包含“下一条记录”指针,该指针以升序存储到页面中下一条记录的偏移量,从而形成一个单链接列表。用户记录结构的详细信息将在以后的文章中进行描述。
-
Page Directory:页面目录从页面的“顶部”开始向下扩展,从FIL尾部开始,并且包含指向页面中某些记录的指针(每4至8条记录)。
2.6、排序索引构建
在创建或重建索引时,InnoDB执行批量加载,而不是一次插入一个索引记录。这种索引创建方法也称为排序索引构建。空间索引不支持排序索引构建。
索引构建有三个阶段:
-
第一阶段,将扫描聚簇索引,并生成索引条目并将其添加到排序缓冲区。当排序缓冲区已满时,将对条目进行排序并将其写到临时中间文件中。此过程也称为“run”。
-
第二阶段,将一个或多个“run”写入临时中间文件,对文件中的所有条目执行合并排序。
-
第三个阶段,将已排序的条目插入到 B 树中
在引入排序索引构建之前,使用插入API将索引条目一次插入到B树中的一条记录中。该方法涉及打开B树光标以找到插入位置,然后使用乐观插入将条目插入B树页面。如果由于页面已满而导致插入失败,则将执行悲观插入,这涉及打开B树游标并根据需要拆分和合并B树节点以找到条目空间。这种建立索引的“自上而下”方法的缺点是搜索插入位置的成本以及B树节点的不断拆分和合并的成本。
排序索引的构建使用“自下而上”的方法来构建索引。通过这种方法,在B树的所有级别都保留了对最右边的叶子页的引用。在必要的B树深度处分配最右边的叶子页,并根据其排序顺序插入条目。叶子页已满后,节点指针将附加到父页,并且为下一个插入分配同级叶子页。此过程将一直持续到插入所有条目为止,这可能会导致插入到根级别。分配同级页面后,将释放对先前固定的叶子页面的引用,并且新分配的叶子页面将成为最右边的叶子页面和新的默认插入位置。
2.6.1、为将来的索引增长保留B-tree页面空间
要为将来的索引增长留出空间,可以使用 innodb_fill_factor 配置选项保留一定比例的B树页面空间。例如,将innodb_fill_factor设置为80可以在排序索引构建期间在B树页面中保留20%的空间。此设置适用于B树叶子页面和非叶子页面。它不适用于用于TEXT或BLOB条目的外部页面。保留的空间量可能与配置不完全一样,因为innodb_fill_factor值被解释为提示而不是硬限制。
2.6.2、排序索引构建和全文本索引支持
全文索引支持排序索引构建。以前,SQL是用于将条目插入全文索引的。
2.6.3、排序索引构建和压缩表
对于压缩表,以前的索引创建方法将条目附加到压缩和未压缩页面上。当修改日志(表示压缩页面上的可用空间)已满时,将重新压缩压缩页面。如果由于空间不足而导致压缩失败,则将拆分页面。使用排序索引构建时,条目仅追加到未压缩的页面。当未压缩的页面已满时,它将被压缩。自适应填充用于确保大多数情况下压缩成功,但是如果压缩失败,则会拆分页面并再次尝试压缩。该过程一直持续到压缩成功为止。
2.6.4、排序索引构建和重做日志记录
在排序索引构建期间,重做日志记录被禁用。而是有一个检查点来确保索引构建可以承受崩溃或失败。该检查点强制将所有脏页写入磁盘。在排序索引的构建过程中,页面清洁器线程会定期发出信号以刷新脏页面,以确保可以快速处理检查点操作。通常,当清洁页数低于设置的阈值时,页面清洁程序线程将刷新脏页。对于排序的索引生成,脏页将立即刷新,以减少检查点开销并并行化I / O和CPU活动。
2.6.5、排序索引构建和优化器统计
排序的索引构建可能会导致优化器统计信息与以前的索引创建方法所生成的统计信息不同。统计信息的差异(预计不会影响工作负载性能)是由于用于填充索引的算法不同。
3、参考文献
- 《高性能MySQL(第3版)》
- 《MySQL技术内幕:InnoDB存储引擎(第2版)》
- 《MySQL源码库》
- 《MySQL参考手册》
- 《MySQL实战45讲》
- 《数据库内核月报》