文献助手
强生医药文献助手
文献入库/解析/搜索
OCR
标题/作者/时间/科目/专业/关键词/摘要/原文
解析
关键词提取
中文分词/
摘要。自动生成摘要。
归类。 科目/专业
搜索
排序。置顶。标注。
---
Architecture
英[ˈɑ:kɪtektʃə(r)] 奥剋忒客车。 美[ˈɑ:rkɪtektʃə(r)]
| n. | 体系结构; 建筑学; 建筑风格; (总体、层次) 结构 |
--
用户。通过 电脑。或者手机 查询
--
强生大脑
数据 算法 算力
数据 知网。指南针 。 office 365。medline。pubmed。
算力 azure
其他平台。微软。research AI 。百度 AI。腾讯AI。阿里云,科大讯飞,
RA就是证书注册审批系统,该系统具有证书的申请、审批、下载、OCSP、LDAP等一系列功能,为整个机构体系提供电子认证服务。 RA作为CA认证体系中的一部分
数字证书注册中心,又叫RA(Registration Authority ),是数字证书认证中心的证书发放、管理的延伸。主要负责证书申请者的信息录入、审核以及证书发放等工作,同时,对发放的证书完成相应的管理功能。发放的数字证书可以存放于IC卡、硬盘或软盘等介质中。RA系统是整个CA中心得以正常运营不可缺少的一部分。
电子商务认证授权机构(CA, Certificate Authority),也称为电子商务认证中心,是负责发放和管理数字证书的权威机构,并作为电子商务交易中受信任的第三方,承担公钥体系中公钥的合法性检验的责任。
CA是证书的签发机构,它是PKI的核心。CA是负责签发证书、认证证书、管理已颁发证书的机关。它要制定政策和具体步骤来验证、识别用户身份,并对用户证书进行签名,以确保证书持有者的身份和公钥的拥有权。
PKI是Public Key Infrastructure的首字母缩写,翻译过来就是公钥基础设施;
X.509标准中,为了区别于权限管理基础设施(Privilege Management Infrastructure,简称PMI),将PKI定义为支持公开密钥管理并能支持认证、加密、完整性和可追究性服务的基础设施]。这个概念与第一个概念相比,不仅仅叙述PKI能提供的安全服务,更强调PKI必须支持公开密钥的管理。
X.509标准是ITU-T设计的PKI标准,它是为了解决X.500目录中的身份鉴别和访问控制问题而设计的。
在X.509标准的早期版本中,除了最基本的组件——CA、证书持有者和依赖方外,只涉及了资料库。由于X.509标准是为X.500目录服务的,所以,资料库的形式就是X.500目录。在后来的X.509标准版本中,又增加了CRL Issuer组件。
在X.509标准中,使用大量的篇幅来定义证书和CRL的数据格式。目前,使用最广泛、最成功的证书和CRL格式,都是X.509标准定义的格式。
ITU-T的中文名称是国际电信联盟电信标准分局(ITU-T for ITU Telecommunication Standardization Sector), 它是国际电信联盟管理下的专门制定电信标准的分支机构。
该机构创建于1993年,前身是国际电报电话咨询委员会(CCITT 是法语Comité Consultatif International Téléphonique et Télégraphique的缩写,英文是International Telegraph and Telephone Consultative Committee),总部设在瑞士日内瓦。
历史上,从1960年到1993年改名为ITU-T,CCITT的建议在每4年一次的全会("plenary assemblies")中正式通过,建议的全集在每次全会后出版,并以每次建议集的封面颜色来命名。例如1980年全会后的全集叫做黄皮书,而1984年的叫做红皮书。全集大概每几百页分为一册并可分册购买。这种每4年才通过一次的机制使得CCITT成为了一个缓慢而僵硬的组织。
由ITU-T制定的国际标准通常被称为建议(Recommendations)。由于ITU-T是ITU的一部分,而ITU是联合国下属的组织,所以由该组织提出的国际标准比起其它的组织提出的类似的技术规范更正式一些。
ITU-T的各种建议的分类由一个首字母来代表,称为系列(见下文),每个系列的建议除了分类字母以外还有一个编号,比如说"V.90"。
有些时候,不如新建一个标准替代原有的。这样的新标准通常通过在原来的标准后面加上"bis"或者"ter"的后缀来表明,如 "V.26bis" 和 "V.26ter"。
和IETF和3GPP等不同,ITU-T发布的协议不是开放的,除了草案和研究阶段的文本外,一般不提供免费下载。ITU-T发布的建议通常有类似X.500的名字,其中X是系列而500是系列号。
China Food and Drug Administration
一般指国家食品药品监督管理总局,是国务院直属机构。其是国家政府设置的药品监督管理部门,是我国药品行政监督管理组织体系一部分,属于国家药事管理组织体系范畴。
前 身
SFDA
RTL
RTL8111_Registers_DataSheet
realtek
医疗器械产品注册技术审评报告-基因测序仪
产品类别。三类
瑞昱
瑞昱(yù)半导体成立于1987年,位于台湾「硅谷」的新竹科学园区,凭借当年几位年轻工程师的热情与毅力,走过艰辛的草创时期到今日具世界领导地位的专业IC设计公司,
我们以螃蟹为企业的标章,是期许自己能效法螃蟹在自然界中以坚韧的生命力,无惧无畏,勇于挑战的象征意义。
凭借着7位创始工程师的热情与毅力,走过风雨飘摇的草创时期,从20个人的规模拓展为今日约2000人的国际知名IC专业设计公司。
以集成电路产品之研发与设计为企业定位,从产品研发、设计、测试到销售,秉持求新求变的原则, 以达成「新技术、新产品、新应用、新价值与新市场」的目标。
瑞昱已成功开发出多种领域的应用集成电路,产品线横跨通讯网路、电脑周边、多媒体、超宽频等技术,与世界先进产业主流并驾齐驱。
员工是瑞昱最重要的资产,是瑞昱成功的基石。自我管理、充份授权、重视团队、共同成长,是我们对同仁的要求和期许
RA注册证。 数字证书注册中心。
数据来源:
1. CFDA (Linkage)。国家食品药物监督管理总局
2. RA Certification Repository (File Server) 证书仓库
3. RA Certification Datasheet (Excel) 数据表
使用场景:
- 销售 根据产品规格查询 产品注册证号(生产日期)。
-
销售 根据产品规格查询 产品注册证信息的状态(有效/失
效/有效期)
-
销售 根据产品规格查询 产品注册证信息。(RTL or CFDA)
-
销售 根据产品规格查询 产品注册证批件及产品检测报告的
前两页。(RTL)
业务痛点:
1. 销售无法及时有效的查询到注册证号,批件信息。
2. 存在多张注册证,销售不知道。
3. 需要检测报告和注册证批件。
--
文献助手
业务痛点
- 销售及市场部人员 在自我学习或撰写项目文档过程中,需要大量文献的支持。由于Global/Local文献库相对 分散,提供的检索功能各不相同,销售及市场部人员自主完成文献检索和全文下载存在困难,会将需求通过医学文献申请表提交至MA完成。
- 申请表需要申请人注明用途,设计的产品,已知文献信息,关键词信息和欲解决的问题
- MA收到大量来自销售及市场部人员提交的文献需求。申请表中提供的检索信息在描述上存在不全面不准确 的问题,往往需要MA与申请人经过多轮线下沟通确认,才能确认实际需求。沟通成本高,反馈周期长,销售及市场部人员无法快速得到所需文献信息,而反复的沟通也增加了MA团队的工作负荷。
--
医学部高级专员(MA)
招聘网站
医学部高级专员(MA)
- 职位月薪:13000-20000元/月

- 工作地点:北京
- 发布日期:招聘中
- 工作性质:全职
- 工作经验:3-5年
- 最低学历:硕士
- 招聘人数:3人
- 职位类别:内科医生
--
23k才是土豪。税后15k才是。
--
应用场景
1. 销售和市场部人员在自我学习或拜访前准备的过程中,需要检索文献,以提升自身学术能力(2018年 1月至6月,MA收到医学文献申请163个,初筛后下载摘要约2100+篇,下载全文约2300+篇)
• 明确知道文献信息,如作者、题目、期刊及发表时间(或链接/PMID/DOI),需要下载文献全文 • 自主进行简单检索,直接输入关键词或组合进行检索
• 涉及多关键词组合、排列相关的复杂检索,咨询MA给出关键词建议,或填写医学文献申请表提
交至MA帮助完成检索
--
需求分析 – 短期
-
统一的文献检索入口,综合检索国内外文献库中的所有内容(包括文献摘要和全文),并遵循文献
的版权要求(文献全文仅限强生内部员工使用) -
基于上述文献库中的文献摘要和全文内容,支持关键词或其组合检索
-
关键词或其组合模糊/精确检索,如产品、疾病、术式、干预等关键词
-
文献信息模糊/精确搜索,如作者、题目、期刊及发表时间(或链接/PMID/DOI)等
-
按文献发布时间段、文献类型和关键词进行检索(新文献、新产品、热点关键词检索)
-
可选择检索文献的语言,如中文、英文
-
-
对于按关键词或其组合检索出的文献,每篇文献自动生成简短摘要(描述目的、材料、方法、结果、 结论等)并翻译,帮助用户快速完成检索结果的初筛
-
对于初筛后的检索结果,支持文献的批量选择/下载,选中的文献自动生成中文/英文汇总摘要(描 述目的、材料、方法、结果、结论等),帮助用户精准获取所需内容
-
检索结果支持全文下载,下载的附件需要添加水印或启用其他版权保护机制
-
支持电脑端使用
--
政策流程解答需求
| 政策大类 |
明细流程 |
| 注册证信息获取 |
注册证信息查询规范 |
注册证批件及检验合格证封面下载规范
|
|
| 注册证附件申请流程 |
|
| 文献查询 |
文献查询使用规范 |
医生临床研究文献查询申请流程
|
--
Nqsky Blazar
耀变体blazar。
assistant
助手,助理;
Spider
Web abstract
--
国家药监局(CFDA)官方网站
强生自有Excel格式RA注册证数据
强生自有关于RA注册证文件服务
--
SPIDER数据采集系统
| 1.Configuration manager |
基于UI界面的爬虫配置管理,以可视化的方式,让用户可以方便地创建抓取任务 |
| 2.Scheduler |
整个爬虫系统的核心模块,负责抓取任务调度 |
| 3.Url manage |
链接管理模块 |
| 4.Fingerprint manager |
语义指纹模块,负责根据链接地址和页面内容制作语义指纹,用于后续模块对网页进行去重,防止重复抓取 |
| 5.Data fetcher |
网页抓取模块,负责从抓取任务队列中取出待抓取的任务 |
| 6.Js executor |
js执行服务,主要针对需要动态加载数据的页面内容下载,通过自动执行页面的js实现页面渲染,获取完整的页面内容数据 |
| 7.Proxy server |
代理服务模块,负责统一管理整个爬虫系统的代理池、cookie池 |
| 8.Data parser |
网页解析模块,对下载的网页内容做解析和抽取,获取网页核心信息 |
| 9.Task queue |
抓取任务队列,存放待抓取的任务信息 |
| 10.Data queue |
网页数据队列,存放待解析的网页数据 |
--
中国知网 CNKI
万方文献库
PubMED 国外资料库
可选文件库(MEDLINE、SCOPUS、OVID)
--
关键字组合检索
中英文文献材料互译
优化查询结果形成个性化推荐
按要求自动形成摘要和总结
支持筛选后批量全文下载
增加水印及版权保护机制
多端同步支持PC端及移动端使用
--
文献助手主要面向销售、市场人员的文献和资料需求,在已经建立了医疗综合信息库的前提下,通过智能搜索引擎、结合自然语言处理、机器翻译、机器学习训练、文献摘要自动提取、智能交互问答等技术,同时通过引入MA人工校正、外部专家人工修正等形式,面向用户提供逐渐精确的文献申请、搜索、审核、自动总结、下载等能力,并支持PC和移动端使用
--
KDD
--
文件助手-自然语言处理-技术架构
--
文本语义分析平台
中文分词技术
机器学习序列标注技术
离线新词发现技术
文本分类技术
文档内容理解技术
深度学习技术
--
关键技术—中文分词技术
基于词典的分词
基于词典的机械切分本质上就是字符串匹配的方法,将一串文本中的文字片段和已有的词典进行匹配,如果匹配到,则此文字片段就作为一个分词结果。
基于序列标注的分词
针对基于词典的机械切分所面对的问题,尤其是未登录词识别,使用基于统计模型的分词方式能够取得更好的效果。基于统计模型的分词方法,就是一个序列标注问题。
--
关键技术--机器学习序列标注技术
序列标注技术是关键信息提取的核心技术。通过对文档信息标注,训练序列标注模型,然后对新样本进行预测。
--
关键技术—中文分词技术
专用词库和并行Bi-LSTM
--
关键技术—离线新词发现技术
现有的大部分分词工具的准确率都比较高,但对于一些未登陆词的识别,效果并不是特别理想,这时就需要用户的词典进行补充。离线新词发现主要是指通过用户收集的文档自动挖掘出其中的未登陆词对词典进行补充的方法。
--
关键技术—文本分类技术
文本分类处理的对象是自然语言文字序列,通过对文本的学习,将文本进行分类。是自然语言处理的基本任务,也是情感分析等上层技术的基石。
--
关键技术—文档内容理解技术
对文档内容深度挖掘和理解并进行关键要素抽取是实现精准化和精细化搜索的前提,也是本搜索区别于普通文档全文搜索的重要特性。
--
经典的机器学习算法需要做各种各样的特征工程,90%的时间都会花在特征工程上。而Deep learning颠覆了这个过程,不需要做特征工程。
--
同义近义词分析:基于通用和专用语料库和语言模型以及搜索日志可以挖掘出常用词的同义近义词。 同义近义词分析是实现语义搜索的基础。
拼写纠错分析:一种是Non-word Error,指单词本身就是拼错的,比如将“happy”拼成“hbppy”,。另一种是指单词虽拼写正确但是结合上下文语境确是错误的,比如“two eyes”写成“too eyes” 。
相关搜索词:通过分析搜索引擎日志,可以挖掘出query的相关搜索词。比如可以挖掘出真格基金的相关搜索词为徐小平、红杉资本等,也可以挖掘出华为手机的相关搜索词为华为mete8
--
关键技术—机器学习排序技术
L1层初级Ranking
L2层基于机器学习的精排
L3层点击反馈排序调权
在搜索排序中使用了一种position-aware ListMLE(p-ListMLE)的算法,考虑了排序位置信息,对不同位置的重要程度进行区分。实践显示同样的条件下p-ListMLE的搜索效果指标nDCG要优于ListMLE(机器学习-文档列表排序方法)。
--
关键技术—基于深度语义相似度模型(DSSM)的匹配技术
针对通用DSSM无法获取句子以及篇章级更长上下文语义的问题,我们引入了结合LSTM的DSSM模型,也称LSTM-DSSM. LSTM-DSSM 其实用的是 LSTM 的一个变种——加入了peep hole的 LSTM。
--
关于文献助手需求--版权控制和管理
文献助手可以对搜索出来的外部文献进行版权甄别、通过外部资源自身的版权控制信息对文献来源、文献下载、转载引用等进行识别,并向用户进行告知、付费、引用说明、禁止转载、禁止下载等的明确提示,避免未来出现版权纠纷
对强生内部资源而言,文献助手通过内置的水印技术,对所有下载的文献自动添加水印,水印内容支持模板定制,密级、权限等信息则根据内控要求自动生成、时间、归属等信息则由系统自行生成,水印仅对下载的文献生效,不影响原始文件
…………
强生项目汇报演示
网页抓取演示,
语义分析 垂直搜索 Runit 文件文本搜索
爬虫和搜索后台配置
配置
https://data.datagrand.com/dashboard/#/search/searchaccessfield
账号:datagrand
密码:datagrand123
文件搜
文件搜索
http://siterec.datagrand.net/run_it/
账号 zhenkunhang
密码 LfSvAxPbIdHeFnZi
Client ID 123
将一个PDF的文字 提取出来了
垂直搜索
搜索
http://gyrx-search-web.datagrand.net/#/main/pic-search
文档上传 和 搜索 文字 图表 范围 搜索
自然语
自然语言处理demo
mo
http://39.96.133.187:10000/
--
医学文献助手是一款可以是在 PubMed 搜索结果页面,添加 PDF 链接、影响因子、F1000评论、作者发表记录等chrome插件。
IF在学术界称之为影响因子,是评价学术期刊和文献质量高低的一个重要指标,当然这个指标并不定完全合理。但是,在当今信息爆炸的年代,我们也只能认为 IF 高的期刊和文献其研究质量也就高。PubMed上查询到的文献并不一定是SCI文献。因为PubMed是一个公共免费的查询平台, 并不会显示影响因子IF。怎么让 PubMed 查询文献时同时显示文献的 IF?这个可以利用医学文献助手可以做到这一点。
它虽然名字是医学文献助手,但是其适用范围并不局限于医学。在最初医学文献助手还有一个更广为熟知的名字:the paper link for PubMed。下面就跟随chrome插件网一起去看看医学文献助手的使用方法吧。
--
文献求助 - 丁香园文献全文求助平台
--
pubmedplus手机客户端是一款医学文献嗖嗖app,支持在线进行关键字的查询,中英文皆可搜索出来,英文文献资料还有详细的翻译
1.检索功能:完善的高级检索、文献筛选、检索历史功能。
2.引文索引:轻松实现引文追溯,解决查找文献广度、深度问题。
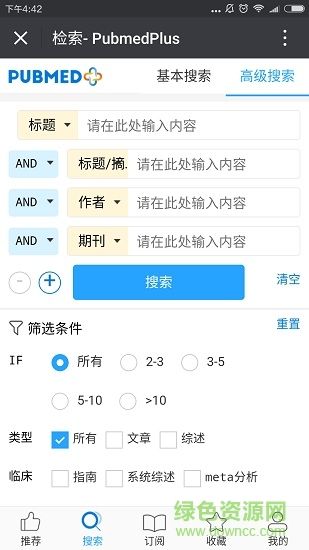
3.收藏导出:支持手机与PC同步,轻松实现文献管理。
4.智能推荐:个性化推荐相关领域文献资料,跟踪进展并拓展视野。
5.Plus工具条:显示期刊影响因子、引用次数、轻松评估文献质量。
6.免费全文:一键链接Scihub,免费下载90%以上收费文献。
7.翻译功能:支持中文检索输入,英文摘要翻译。
8.订阅功能:轻松跟踪某一领域、期刊、作者等最新文献。
--
注册网址:http://www.storkapp.me/?ref=14500
作为一只科研狗,业界大牛的文章是我的好伙伴,不仅要掌握领域内的研究方向,还要及时追踪研究课题的新发现。但每天在Pubmed等网站逐一浏览相关文献,往往事半功倍。
后来,师兄向我推荐了神器Stork:Stork 文献鸟是由斯坦福大学成员开发的文献追踪的小工具,只需注册并设置好关键词,就会收到相应的文章。不仅如此,还可以对期刊,影响因子等进行筛选,有的放矢得找到感兴趣的文章
Stork最新推出了翻译功能,文章标题下方注有翻译,这对英文不好的我来讲太方便了。以前使用Stork时,尽管每个关键字只推送了10多篇,但一篇篇读下去也需要时间,有时还要谷歌翻译一下。现在好啦,几秒钟的时间就可以看完了,这可真是质的飞跃,Stork简直太贴心了!
不仅如此,Stork的翻译功能还覆盖了摘要部分,点开文章链接查看摘要,中英文对照一览无余,更加省时省力!
还在科研长路里上下求索的同学们,快来加入Stork大家庭吧!
--
参考文献到底有多重要?
从一定意义上说,论文的学术性和权威性,在某种程度上也可以从参考文献中表现出来。科学史上的任何研究成果,都是在前人或旁人的劳动成果基础上创造出来的,通过学者间的相互引用得以代代相传。
给大家分享学术史上的一个有趣的老故事,《acta crystallographica section A》在2010汤森路透公布的影响因子在学术圈激起了一场不小的波澜:前一年的影响因子还只有2.051,居然跃升到49.926,位列全榜第二!而同年nature、science的影响因子分别是34.480和29.747。这背后并没有任何舞弊和学术不端行为,而是因为该刊在2008年发表的一篇文章,被引频次高达5624次,贡献了该刊2008年72篇文章总被引次数的94.3%。
由此可见,参考文献对作者的文章是否能被接收很重要,对期刊的影响力也是同样重要。
你在用什么方法引用参考文献?
你该不会是在用最古老的方式:手工添加参考文献吧?这种方法有多不方便就不多说了,除非你的参考文献只有两三条。怎么可能呢,哪个期刊会接受一篇只有两三篇参考文献的文章呢。核心期刊的最新标准是最低15条参考文献。手工添加再加上后续的返修工作量丝毫不小,为何在这上面浪费有限的时间呢
当然我相信已经有非常多的资深科研者已经找到了一些好用文献管理工具,如endnote、readcube、医学文献王等。这些工具有个什么共同点呢?
难!难!难!(用了多年的童鞋请无视)
难在哪里?这类工具重在文献管理,界面复杂,操作相对也比较复杂,很多小伙伴用了一次之后似乎没有找到门道,无奈放弃,被迫手动添加。
现在这个时代,最不缺的就是资源、工具。在众多工具中如何找到最适合自己使用的呢?
今天小编纯福利分享一个用不了两分钟就学会的文献引用工具:引文小助手,简单说一下为什么值得推荐:
1.效率至上
节约30%的论文写作时间。
2.能解决本质需求即可,不要冗余,要轻便
解决快速引用参考文献、快速调整参考文献格式,解决本质需要,支持两大主流写作软件:word、wps
3.参考文献格式全而准
该软件内部收录了2000多种国内外期刊的参考文献格式,随意切换格式。再也不用去下载稿约再逐条调整参考文献了,好省心有没有?
4.免费
不要笑,对于现在文献管理软件动辄两三百的价格,这很重要,要是小编的话,会把它排在第一位好吗
5.还有一点小编认为是非常重要的,那就是中华医学会旗下的所有编辑部的编辑老师们都在用这个软件校对文献了,你还在等什么呢? PS:编辑老师用的是完整版《医学文献王》,如对完整版《医学文献王》感兴趣可前往医脉通网站(medlive.cn)免费下载。
说了这么多,到底有多容易呢?来看小编的操作:
无需启动软件,安装之后,启动word、wps的同时会自动启动。
假如你需要在word或wps的A处引用某条参考文献
第一步:搜索你要引用的参考文献,可按照标题、网址、pmid、关键词等搜索文献

第二步:搜索到需要引用的参考文献之后,一键完成引用

(点击文献右侧的按钮即可完成自动引用)
第三步:调整你需要的参考文献格式
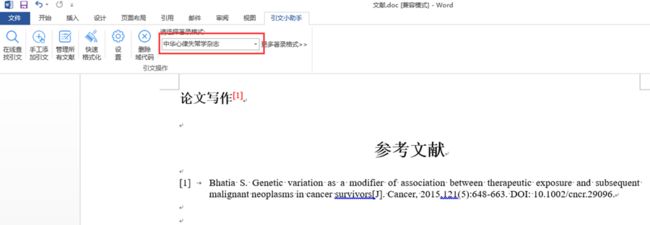
Bingo,参考文献就这样妥妥地搞定了。足够简单吧?
》》》奉上下载链接:引文小助手
--
如果只是引用,不涉及编辑后的自动调整,用百度学术也是同样很快捷的。输入题名后检索,一般都能命中全文,点击引用,即可显示出引文格式。点击复制即可。百度学术提供很多全文链接,中英文都有,使用起来很方便。作为工具而言,可以大胆使用,不用顾虑既往对百度的讨伐
--
各位大咖们做科研时少不了看很对文献,看文献少不了 PubMed,在之前微信平台也推过关于PubMed的功能及检索途径与方法,在目前PubMed是国际上最重要、最权威的生物医学文献数据库之一。PubMed一经问世,就以其文献报道速度快、访问免费、使用方便、检索功能强大、外部链接丰富、个性化服务等众多优点而获得广大用户的青睐,已成为网络环境下科研人员及医务工作获取生物医学文献信息资源的首选。然而,面对庞大的数据库检索出来的结果,精细限定搜索范围显得尤为重要。
在大环境下, Pubmedplus 应运而生,它是在 Pubmed 基础上开发的用于辅助科研的分析型文献聚类系统。通过聚类分析,帮助科研人员了解该课题在国际上发展趋势与成熟程度,分析国内外同行研究进展,寻找合作者。通过主题共词分析帮助科研人员发现潜在的研究热点,引导其发散思维,寻找新的研究方向。通过期刊的聚类分析可以了解期刊的国际化程度、收录方向及国内作者发文命中的百分比等,为读者提供全方位的期刊投稿服务。
下面介绍 Pubmedplus 的功能,带你领略它的魅力,公众号:SCI医学科研论文助手(微信:678677)为您揭开它的神秘面纱。
--
关键词提取自动摘要相关开源项目
GitHub - hankcs/HanLP: 自然语言处理 中文分词 词性标注 命名实体识别 依存句法分析 关键词提取 自动摘要 短语提取 拼音 简繁转换
https://github.com/hankcs/HanLP
文章或博客的自动摘要(自动简介) - 开源中国社区
http://www.oschina.net/code/snippet_1180874_23950
Python实现提取文章摘要的方法_python_脚本之家
http://www.jb51.net/article/64543.htm
--
自动摘要 关键
--
一、关键词自动标注
1、关键词
关键词是指能够反映文本语料主题的词语或短语,是快速了解文档内容、把握主题的重要方式。
2、概述
关键词自动标注大概可以分为两大类,一为关键词分配,另一个为关键词提取。
关键词分配是从一个预先构建好的受控词表中推荐若干个词或者短语分配给文档作为关键词。
关键词提取是从文档内容中寻找并推荐关键词,而没有指定的词库。
3、关键词提取
关键词提取一般分为两个步骤,一是生成关键词候选表,二是采用算法选择关键词。
(1)生成关键词候选表
1)去除停用词
2)只提取指定词性的词,如,名词、形容词、动词等
3)其他规则筛选等
(2)算法选用
现有的算法根据是否依赖外部知识库,大致可以分为两大类:一是依赖外部知识库,如:TF-IDF等;二是不依赖外部知识库,如:Textrank等。
此外还有监督方法,将关键词抽取转为序列标注,或基于神经网络的方法等。
4、TF-IDF
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或者或一个语料库中的其中一份文件的重要程度。
字词的重要随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
(1)原理
词频,即TF,指的是某一个给定的词语在该文件中出现的次数,通常进行归一化。
逆向文档频率,即IDF,是一个词语普遍重要性的度量,通常由总文件数目除以包含该词语的文件数目得到的商取对数得到。
实际上可以将IDF看成一个重要性的调整参数,在词频的基础上,对每一个词分配一个重要性度量,最常见的词给与小权重,而最不常见的词给与大的权重,最后将词频与权重相乘得到某个词对文章的重要性度量。
5、TextRank
TextRank算法是基于GOOGLE的提出的pageRank算法改进而来,详细可以参考我的另一篇博文:pageRank
(1)原理
TextRank与pageRank不同之处,在于权重系数的增加:
(2)权重系数
在经过处理构造出候选关键词后,得到候选关键词表T = [C1, C2, C3…CN]
对于关键词表构建长度为K的窗口,当两个词A和B在该窗口中同时出现时,认为当前两个节点有关联,在pageRank中就是两个网页间有超链接跳转,对所有的词进行统计之后归一化,就得到权重系数,这也称为共现关系。
之后进行迭代计算,就得到关键词选项了。
二、自动摘要
自动摘要与关键词自动标注类似,是从文章中自动抽取出关键句。
1、概述
自动摘要主要分为两大类,一种是抽取式,即直接从文章存在的句子中抽取出最重要的几句作为关键句;另一种是生成式,这种方法在实现难度上远高于前者,在理解文章语义的基础上重新概括生成文本。
一般采用的都是抽取式方法进行自动摘要。
2、应用
自动文摘与关键词自动标注一样可以采用TextRank进行抽取,唯一不同的是权值的计算方式,这里可以用句子之间的相似性进行替代。
在自动摘要中,对文档进行断句,分词等预处理后,得到每个句子的词列表。之后可以使用文档相似度算法,如BM25等进行计算,得出的相似度作为权值进行迭代计算,最后得到评分最高的句子。
关于TF-IDF和TextRank算法,在python的jieba包中都有算法实现。
---------------------
关键词提取方法学习总结(TF-IDF、Topic-model、RAKE)
…………
自然语言处理
百度
接口能力
| 接口名称 | 接口能力简要描述 |
|---|---|
| 词法分析 | 分词、词性标注、专名识别 |
| 依存句法分析 | 自动分析文本中的依存句法结构信息 |
| 词向量表示 | 查询词汇的词向量,实现文本的可计算 |
| DNN语言模型 | 判断一句话是否符合语言表达习惯,输出分词结果并给出每个词在句子中的概率值 |
| 词义相似度 | 计算两个给定词语的语义相似度 |
| 短文本相似度 | 判断两个文本的相似度得分 |
| 评论观点抽取 | 提取一个句子观点评论的情感属性 |
| 情感倾向分析 | 对包含主观观点信息的文本进行情感极性类别(积极、消极、中性)的判断,并给出相应的置信度 |
| 文章标签 | 对文章的标题和内容进行深度分析,输出能够反映文章关键信息的主题、话题、实体等多维度标签以及对应的置信度 |
| 文章分类 | 对文章按照内容类型进行自动分类 |
| 文本纠错 | 识别输入文本中有错误的片段,提示错误并给出正确的文本结果 |
| 对话情绪识别 | 针对用户日常沟通文本背后所蕴含情绪的一种直观检测,可自动识别出当前会话者所表现出的情绪类别及其置信度 |
| 中文分词 | 切分出连续文本中的基本词汇序列(已合并到词法分析接口) |
| 词性标注 | 为自然语言文本中的每个词汇赋予词性(已合并到词法分析接口) |
科大讯飞python自然语言处理-开放平台_注册可免费使用
自然语言处理(NLP) vs 自然语言理解(NLU)
自然语言处理-阿里云
排行榜 自然语言处理
--
我把 我曾经搜索的 记录 都记录下来。 这都是方法。
--
文献检索 下载 工具
--