初探MNN
初探MNN
伴随着大量人工智能项目的落地,业界对端上推理的需求也越来越旺盛。在之前的文章中介绍过OpenCV的DNN模块,目前开源的端上推理引擎除了OpenCV的DNN之外,还有tensorFlow-lite、paddle-lite、NCNN、MNN等多个推理框架。目前端上推理引擎主要支持CPU及端上GPU,主流的的设备是CPU(arm)+GPU(mali qualcomm powerVR),主要的编程语言包括c、neon、汇编、OpenCL、OpenGL、vulkan,其中前三种主要是针对CPU的优化,后三种是GPU编程语言。本系列文章将对MNN架构进行逐步剖析,通过对源代码的分析,更加深入的理解推理引擎及优化的技术细节。
与之前文章不同的是,在之后的文章中,我会尽量少贴源代码,更多的以图的形式来展示代码原理,关于代码的注释,我会在github上新开一个分支来存放带有注释的代码,感兴趣的朋友可以自己clone阅读。这篇文章主要通过跑通MNN的benchmark对MNN进行简单介绍。
MNN benchmark
MNN的benchmark做的非常棒,用起来很方便。
- 配置NDK(在benchmark目录下的bench_android.sh文件中指定NDK的路径
export ANDROID_NDK=youpath) - 把目标手机链接到电脑上,使用adb连接
- 拷贝benchmark/model目录下的model到手机的/data/local/tmp/bench_models目录下
- 直接运行bench_android.sh
运行结束便可以在benchmark目录下看到运行结果;结果保存在benchmark.txt文件中。如下是笔者运行的结果,笔者使用的机器是SDM710,测试的网络是resnet-v2-50:
Hardware : Qualcomm Technologies, Inc SDM710
Build Flags: ABI=armeabi-v7a OpenMP=ON Vulkan=ON OpenCL=ON
MNN benchmark
Forward type: **CPU** thread=4** precision=2
--------> Benchmarking... loop = 1
[ - ] resnet-v2-50.mnn max = 338.381ms min = 338.381ms avg = 338.381ms
MNN benchmark
Forward type: **Vulkan** thread=4** precision=2
--------> Benchmarking... loop = 1
Vulkan don't support 68, Reduction: resnet_v2_50/pool5
[ - ] resnet-v2-50.mnn max = 164.605ms min = 164.605ms avg = 164.605ms
这是cpu和vulkan的对比,可以看到vulkan目前有一个layer不支持。感兴趣的读者可以测试其他模型以及OpenCL和OpenGL的性能表现。MNN支持的模型是.mnn格式的,除了官方提供的模型之外,其他模型需要用户使用其convert工具生成,该工具对网络进行了层间融合等优化,生成的是一个序列化的文件。之后我们会详细介绍该工具。
完成了benchmark的运行之后,我们便从benchmark.cpp入手,简单极少其运行机制。
MNN运行机制简介
benchmark.cpp的文件很简单,也很清晰。很容易发现程序的核心部分是
std::vector doBench(Model& model, int loop, int forward = MNN_FORWARD_CPU, bool only_inference = true,
int numberThread = 4, int precision = 2)
该函数中的运行过程如下:
read model-->create Net(Interpreter) --> 配置backend --> create session --> config input and output --> run session --> finished
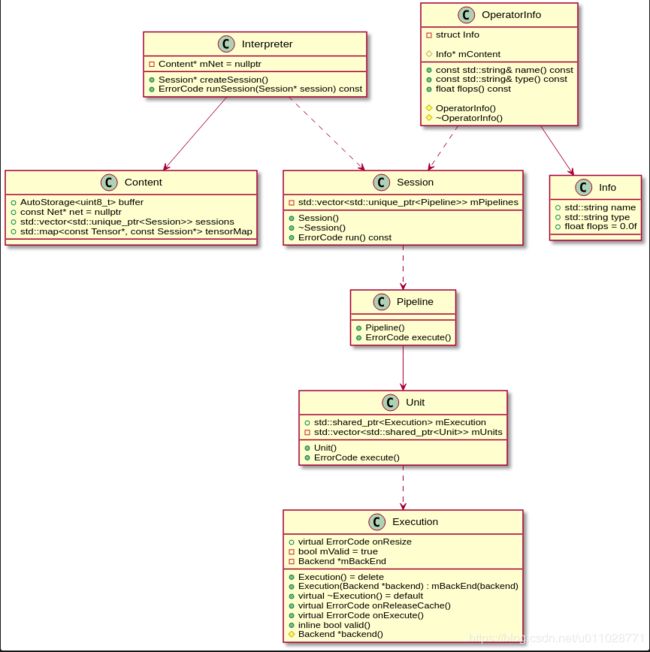
看起来很清爽,接下来我们来一一介绍这个过程中所涉及的类及其运行机制。整个过程中涉及到的类的关系如下:
Interpreter ..> Session
Interpreter --> Content
Session ..> Pipeline
Pipeline --> Unit
OperatorInfo ..> Session
OperatorInfo --> Info
Unit ..>Execution
接下来我们按照函数的调用顺序来解析(代码是摘出来的片段,不完整):
read model–>create Net(Interpreter) --> create session --> run session
auto net = std::shared_ptr(MNN::Interpreter::createFromBuffer(modelBuffer, bufferSize));
MNN::Session* session = net->createSession(config);
net->runSession(session);
这是整个运行过程的一个简化版本。接下来从runSession函数开始一层层深入,看它是如调用底层OP的。
Interpreter::createSession()
Session* Interpreter::createSession(const ScheduleConfig& config) {
return createMultiPathSession({config});
}
Session* Interpreter::createMultiPathSession(const std::vector& configs) {
//判断model buffer是否为空;buffer中是序列化的model文件数据
if (nullptr == mNet->buffer.get()) {
MNN_ERROR("The model buffer has been released. Can't create session\n");
return nullptr;
}
//按照config调度net中的op到pipeline上,关于调度细节会在后续文章中详解
auto info = Schedule::schedule(mNet->net, configs);
//使用info初始化Session
auto newSession = std::unique_ptr(new Session(info));
if (!newSession->valid()) {
MNN_PRINT("Invalide Session!!\n");
return nullptr;
}
auto result = newSession.get();
if (info.validForResize) {
result->resize();
}
//更新Content的sessions变量
mNet->sessions.emplace_back(std::move(newSession));
return result;
}
从以上流程注释可以知道,在create session的时候,就会使用schedule对序列化文件中的op进行调度,调度后的OP信息被用来初始化session,createSession函数返回的便是包含schedule后信息的Session;
runSession()
ErrorCode Interpreter::runSession(Session* session) const {
return session->run();
}
runSession函数使用输入的session调用自己的run()方法。
Session::run()
ErrorCode Session::run() const {
if (mNeedResize) {
MNN_ERROR("Can't run session because not resized");
return COMPUTE_SIZE_ERROR;
}
// Interpreter::createMultiPathSession函数的注释中介绍到,
// Schedule::schedule函数会把OP调度到对应的pipeline上;
// 所以在session初始化的时候便会更新自己的pipeline变量,就是mPipeline;
// session的初始化是在Interpreter::createMultiPathSession函数中发生的
for (auto& iter : mPipelines) {
//每个pipeline运行自己的execute()方法
auto error = iter->execute();
if (NO_ERROR != error) {
return error;
}
}
return NO_ERROR;
}
注释中介绍到,session的初始化是在Interpreter::createMultiPathSession函数中进行的,接下来,我们看一下session的构造函数。
Session::Session(const Schedule::ScheduleInfo& info) {
if (info.pipelineInfo.empty()) {
mValid = false;
return;
}
mTensors = info.allTensors;
//遍历info的pipleinfo变量;将Op的pipeline更新到session的mPipeline变量上。
for (auto& iter : info.pipelineInfo) {
if (mBackends.find(iter.first.type) == mBackends.end()) {
auto newBn = BackendFactory::create(iter.first);
if (nullptr == newBn) {
mValid = false;
return;
}
mBackends[iter.first.type].reset(newBn);
}
auto backend = mBackends.find(iter.first.type)->second.get();
auto cpuBackend = _getDefaultBackend();
//更新pipeline到session的mPipeline变量
std::unique_ptr newPipeline(new Pipeline(iter.second, backend, cpuBackend));
mPipelines.emplace_back(std::move(newPipeline));
}
mInputs = info.inputTensors;
mOutputs = info.outputTensor;
for (auto& iter : mInputs) {
TensorUtils::getDescribe(iter.second)->isInput = true;
}
}
Pipeline::execute()
ErrorCode Pipeline::execute() {
mBackend->onExecuteBegin();
//遍历mUnits变量执行units的execute()方法
for (auto& u : mUnits) {
auto code = u->execute();
if (code != NO_ERROR) {
mBackend->onExecuteEnd();
return code;
}
}
mBackend->onExecuteEnd();
return NO_ERROR;
}
可以看到这里执行的是unit的execute()方法;而数据是通过mUnit进行传递的;该变量同样是在pipeline初始化的时候更新的。所以接着看pipeline的构造函数。
Pipeline::Pipeline(const std::vector& infos, Backend* backend, Backend* cpuBackend) {
SizeComputerSuite::init();
MNN_ASSERT(nullptr != backend);
MNN_ASSERT(nullptr != cpuBackend);
mBackupBackend = cpuBackend;
mBackend = backend;
//更新mUnit变量
for (auto& info : infos) {
std::shared_ptr unit(new Unit(info.op, info.inputs, info.outputs));
mUnits.emplace_back(unit);
}
}
构造中使用op,input及output数据更新了mUnit变量。我们再看一下unit的构造函数。
Pipeline::Unit::Unit(const Op* op, const std::vector& inputs, const std::vector& outputs) {
MNN_ASSERT(nullptr != op);
mOriginOp = op;
mOriginOp = op;
mType = op->type();
mInputs = inputs;
mOutputs = outputs;
//更新op name
if (nullptr != op->name()) {
//添加log
MNN_READLOG("=== %s\t%d === op name: %s ====\n", __FUNCTION__, __LINE__, op->name()->c_str());
mContent->name = op->name()->str();
}
//更新op的type
auto typeStr = EnumNameOpType(mType);
if (nullptr != typeStr) {
mContent->type = typeStr;
}
//暂时不介绍
mComputer = SizeComputerSuite::get()->search(mType);
}
Unit::execute()
ErrorCode Pipeline::Unit::execute() {
if (nullptr == mExecution) {
return NO_EXECUTION;
}
if (mConst) {
return NO_ERROR;
}
//调用具体的backend的op函数执行计算
auto code = mExecution->onExecute(mInputs, mOutputs);
if (NO_ERROR != code) {
MNN_ERROR("Execute Error for %s, code=%d\n", mContent->name.c_str(), code);
}
return code;
}
从UML图中可以看到execute类包含多个虚函数;而这些虚函数的实现都是由具体的OP类完成。以后的文章中会详细介绍各个OP。
op信息查看
在Pipeline::Unit::Unit中我添加了MNN_READLOG这个log,这是我在include目录下的MNNDefine文件中添加的,以后在源代码中增加的log都会使用这个宏,这次的使用主要是在该函数中打印OP的名称,查看MNN执行resnet使用到的OP有那些。运行结果如下:
=== Unit 86 === op name: resnet_v2_50/block1/unit_1/bottleneck_v2/conv1/convolution ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_1/bottleneck_v2/shortcut/convolution ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_1/bottleneck_v2/conv2/convolution ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_1/bottleneck_v2/conv3/convolution ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_1/bottleneck_v2/add ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_2/bottleneck_v2/preact/batchnorm/add_1 ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_2/bottleneck_v2/preact/Relu ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_2/bottleneck_v2/conv1/convolution ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_2/bottleneck_v2/conv2/convolution ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_2/bottleneck_v2/conv3/convolution ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_2/bottleneck_v2/add ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_3/bottleneck_v2/shortcut/MaxPool ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_3/bottleneck_v2/preact/batchnorm/add_1 ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_3/bottleneck_v2/preact/Relu ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_3/bottleneck_v2/conv1/convolution ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_3/bottleneck_v2/conv2/convolution ====
=== Unit 86 === op name: resnet_v2_50/block1/unit_3/bottleneck_v2/conv3/convolution ====
由于涉及到的OP比较多,这里节选了一部分;可以看到,convolution后面的relu都被融合了,只执行了convolution的op。
到此为止,我们知道了MNN大体的调度流程。首先在模型转换工具中将模型信息序列化,包括进行层间融合的上层优化,将整个模型的layer抽象为OP。在推理阶段,整个推理是以Session完成的,每个Session内部会通过Schedule::schedule将序列化的OP信息调度到具体的pipeline上,然后通过调用具体OP execute函数完成最终的OP操作。
以上是一个大体的执行流程,虽然这过程中还会涉及内存管理,算法选择以及其他细节。我们会在之后的文章中逐步解析整个过程。从上述流程看,针对网络的优化在模型转换阶段已经开始,所以下一篇文章我们会查看MNN的模型转换代码,了解针对网络优化的部分例如层间融合的细节。
欢迎关注公众号:
