Spark-内核解析
文章目录
- 小笔记
- spark通信架构
- spark脚本
- spark Standalone启动流程
- spark应用提交流程
- spark shuffle过程
- Spark内存管理与分配
- 第1章Spark整体概述
- 如何查看spark源码
- 1.1整体概念
- 1.2RDD抽象
- 1.3计算抽象(重点看下,也算是任务运行吧)
- 1.4集群模式
- 1.5RPC网络通信抽象
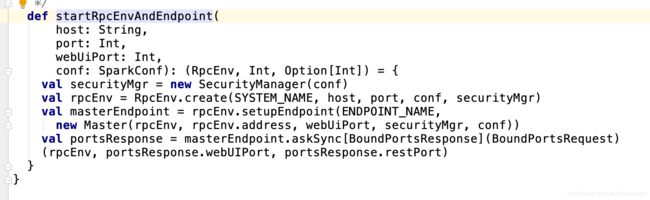
- 1.6启动Standalone集群
- 1.7核心组件
- 1.8核心组件交互流程(重点看,面试必问呦,6.2 、 第七章、8.2有更加详细的根据源码的解释,看一遍)
- 1.9Block管理
- 1.10整体应用
- 第2章脚本解析
- 2.1start-daemon.sh
- 2.2spark-class
- 2.3start-master.sh
- 2.4start-slaves.sh
- 2.5start-all.sh
- 2.6spark-submit
- 第3章Spark通信架构(重点看下)
- 3.1通信组件概览
- spark的通信架构--类图
- 3.2Endpoint启动过程
- 3.3Endpoint Send&Ask流程
- 3.4Endpoint receive流程
- 3.5Endpoint Inbox处理流程
- 3.6Endpoint画像
- 第4章Master节点启动
- 4.1脚本概览
- 4.2启动流程
- 4.3OnStart监听事件
- 4.4RpcMessage处理(receiveAndReply)
- 4.5Master对RpcMessage/OneWayMessage处理逻辑
- 第5章Work节点启动
- 5.1脚本概览
- 5.2启动流程
- 5.3OnStart监听事件
- 5.4RpcMessage处理(receiveAndReply)
- 5.5OneWayMessage处理(receive)
- 第6章Client启动流程
- 6.1脚本概览
- 6.2SparkSubmit启动流程
- 6.3Client启动流程
- 6.4Client的OnStart监听事件
- 6.5RpcMessage处理(receiveAndReply)
- 6.6OneWayMessage处理(receive)
- 第7章Driver和DriverRunner
- 7.1Master对Driver资源分配
- 7.2Worker运行DriverRunner
- 7.3DriverRunner创建并运行DriverWrapper
- 第8章SparkContext解析
- 8.1SparkContext解析
- 8.2SparkContext创建过程
- 8.3SparkContext简易结构与交互关系
- 8.4Master对Application资源分配
- 8.5Worker创建Executor
- 第9章Job提交和Task的拆分
- 9.1整体预览
- 9.2Code转化为初始RDDs
- 9.3RDD分解为待执行任务集合(TaskSet)
- 9.4TaskSet封装为TaskSetManager并提交至Driver
- 9.5Driver将TaskSetManager分解为TaskDescriptions并发布任务到Executor
- 第10章Task执行和回执
- 10.1Task的执行流程
- 10.2Task的回馈流程
- 10.3Task的迭代流程
- 第11章Spark的数据存储
- 11.1存储子系统概览
- 11.2启动过程分析
- 11.3通信层
- 11.4存储层
- 11.4.1Disk Store
- 11.4.2Memory Store
- 11.5数据写入过程分析
- 11.5.1序列化与否
- 11.6数据读取过程分析
- 11.6.1本地读取
- 11.7Partition如何转化为Block
- 11.8partition和block的对应关系
- 第12章Spark Shuffle过程(重点看)
- 12.1MapReduce的Shuffle过程介绍
- 12.1.1Spill过程
- 12.1.1.1 Collect
- 12.1.1.2 Sort
- 12.1.1.3 Spill
- 12.1.2Merge
- 12.1.3Copy
- 12.1.4Merge Sort
- 12.2 Spark的Shuffle过程介绍 - HashShuffle
- 12.3Spark的Shuffle过程介绍 - SortShuffle
- 12.4TungstenShuffle过程介绍
- 12.5MapReduce与Spark过程对比
- 第13章Spark内存管理 重点看
- 13.1堆内和堆外内存规划
- 13.1.1堆内内存
- 13.1.2堆外内存
- 13.1.3内存管理接口
- 13.2内存空间分配
- 13.2.1静态内存管理
- 13.2.2统一内存管理
- 13.3存储内存管理
- 13.3.1RDD 的持久化机制
- 13.3.2RDD 缓存的过程
- 13.3.3淘汰和落盘
- 13.4执行内存管理
- 13.4.1多任务间内存分配
- 13.4.2Shuffle 的内存占用
- 第14章部署模式解析
- 14.1部署模式概述
- 14.2standalone框架
- 14.2.1Standalone模式下任务运行过程
- 14.2.2总结
- 14.3.1集群下任务运行过程
- 14.4mesos集群模式
- 14.5spark 三种部署模式的区别
- 14.6异常场景分析
- 14.6.1异常分析1: worker异常退出
- 14.6.1.1 后果分析
- 14.6.1.2 测试步骤
- 14.6.1.3 异常退出的代码处理
- 14.6.1.4 小结
- 14.6.2异常分析2: executor异常退出
- 14.6.2.1 测试步骤
- 14.6.2.2 fetchAndRunExecutor
- 14.6.3异常分析3: master 异常退出
- 15.2原理
- 分配逻辑(重点看下,后面的视频中进行的补充)
小笔记
spark通信架构

1、Spark 采用Netty作为新的消息通讯库,采用了Actor模型进行底层通信架构的设计与实现,在Spark2. 0中,彻底取代了以AKKA作为底层通信框架的实现
2、RpcEnv, 是Spark通信架构的一一个入口点,类似于SparkContext, 是用于创建整个Spark通信端点与通信服务的上下文环境。实现上使用NettyRpcEnv来作为默认实现。
3、RpcEndPoint, 是类似于Actor的具体的消息顶点,通过继承RpcEndpoint来实现消息顶点的实例化,需要复写onStart、receive以及receiveAndRelpy方法。
3、Inbox, 一个RpcEndpoint带有- -个Inbox,用于存储外部发过来的数据。
4、Dispatcher,消息的转发器,- -个RpcEnv带有- -个Dispatcher的实例,主要功能是通过接受Tr anspor tServer传过来的消息,将消息存入Inbox里面,通过接受当前端点传过来的消息,将消息放到对应的0utbox中。
5、Outbox, - -个远程端点的代理具有一个0utbox, 用于存放当前节点发送给远程端点的数据。
6、TransportServer, 主要是用于接受远程Endpoint发送过来的消息,并把消息传送给Dispatcher
7、Tr anspor tClient,主要负责将相对应对的0utBox中额数据发送给远程的Tr anspor tServer。
spark脚本

1、start-slave. sh用于启动slave节点,最终启动的类是org. apache. spark. dep1oy. worker. Worker类
2、start -master. sh用于启动master节点,最终启动的类是org. apache. spark. deploy. master. Master类
3、Spark-submi t和Spark -she11最终都会调用spark-c1ass脚本,通过spark-c1ass脚本启动相对应的入口类。
spark Standalone启动流程

1、Master和Workero都继承 了RpcEndPoint类,成为了具体的消息发送与接收端点,整个应用架构是利用Actor模型实现的异步消息通信架构。
2、Master节点在启动的时候主要任务就是创建了通信架构中的RpcEnv,并注册了Master成为端点。
3、Worker节点在启动的时候主要任务也是创建了通信架构中的RpcEnv,并注册了Worker成为端点,并且获取了Master的端点代理,通过端点代理像
Master发送消息。
4、Worker在启动的时候执行0nstar t方法,向Master进行了注册。
spark应用提交流程
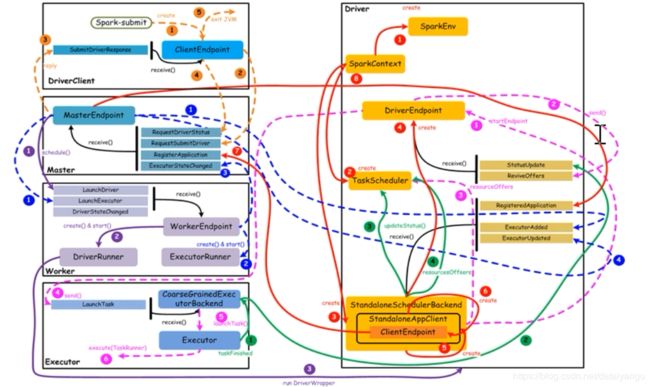
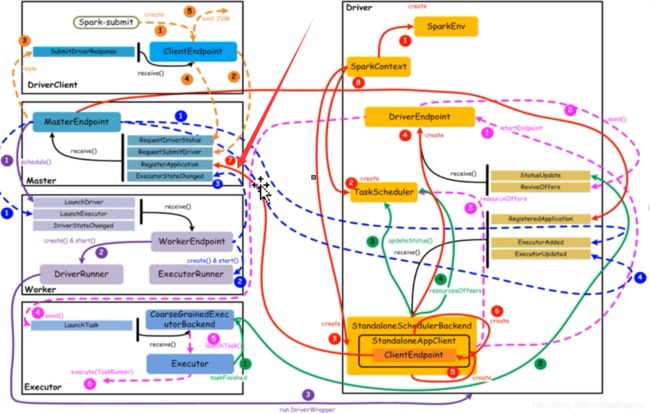
[橙色:应用提交] -》[紫色: 启动Driver进程] --》[红色:注册Application] --》[蓝 色:启动Executor进程] -》[粉色:启动
Task执行] -》[绿 色:Tash运行完成]
1、Driver提交流程:用户通过Spark- -submi t将J ar包和相对应的参数提交给Spark框架,内部实现是通过Cli entEndpoint向Master发送了
RequestSubmi tDriver消息。Master获取消息之后通过worker进行LaunchDriver操作。
2、Driver的进程启动:主要通过Worker节点的DriverRunner来启动整个的Driver进程。
3、注册Application: Driver进程在启动之后,通过SparkContext的初始化操作,创建了对应的SchedulerBackend,实现了像Mas ter进行当前应用的注
册。
4、启动Executor进程:当Driver向Master进行注册之后,Mastex通过Scheduler方法来对当前的App进行Executor的分配,实现上是通过Worker的
ExecutorRunner来进行Executor的创建和运行。
5、启动Task运行:当Driver收到所有的Exector资源后,通过RDD的action操作,触发SparkContext. runJob方法,进而调用DagScheduler进行当前DAG
的运行。通过向Executor发送LaunchTask消息来启动Executor.上的任务运行。
6、Task运行完成:当Executor运行任务完成之后,会通知Driver当前任务的运行状态。然后迭代执行任务或者退出整个应用。
spark shuffle过程
MapReduce:
1、spil1阶段,数据直接写入到kvbuffer数据缓冲器,会写两种类型的属性,-种是kmeta,用于存放分区信息、索引信息,另- -种是(k,v)数据,
是真实的数据。会以一个起点反向来写,当遇到spill1进程启动的时候,写入点会重新进行选择。
Hash Shuffle:
1、未优化版本中,每一一个task任务都会根据reduce任务的个数创建对应数量的bucket, bucket其实就是写入缓冲区, 每一-个bucke都会存入一个文
件,这个文件叫blockfile.最大的劣势是产生的文件过多。
2、在优化版本中,主要通过consolidation这个参数进行优化, 实现了ShuffleFileGroup的概念,不同批次的task任务可以服用最终写入的文件,来整
体减少文件的数量。
Sort Shuffle:
1、Sort Shuffle整个过程的实现和MapReduce的shuffle过程很类似。
2、ByPass机制, Hashshuffle在reduce数量比较少的时候性能要比Sor tshuffle要高,所以如果你的reduce数量少于bypass定义的数值的时候,sort .
shuffle在task任务写出的时候会采用hash的方式,而不会采用&pply0n1yMap以及排序。
Spark内存管理与分配


1、内存分配模式上,主要分为静态分配以及统- -分配两种方式。 静态就是固定大小,统- -分配是存储区和Shuff1e区可以动态占用。
2、有几种内存配置模式:
1、other区, - -般占用20%的内存区域,主要是用于代码的运行以及相关数据结构的运行。
2、Execution区, 这个区域- -般占用20%的内存区域,主要通过spark. shuffle. memoryFraction参数指定。主要用于Shuff le过程的内存消耗。
3、Storage区, 这个区域主要用于RDD的缓存,主要通过spark. stor age. memoryFraction参数指定,-般会占用60%的区域。
3、Spark目前支持堆内内存以及堆外内存,堆外内存主要存储序列化后的二进制数据。|
第1章Spark整体概述
如何查看spark源码
直接进入spark官网http://spark.apache.org/downloads.html,用github试过了,老是网络超时。
这里应该是选其他的也可以,我选的是http的。
下载下来之后解压。
然后通过idea import,选择maven
之后进入idea中看到代码会有很多红线,引入jdk,然后plugin install scala,重启idea。之后就可以了。

如果还是有报错,注意修改jdk的编译版本,java compile里面设置,最后重新编译一下。
1.1整体概念
Apache Spark是一个开源的通用集群计算系统,它提供了High-level编程API,支持Scala、Java和Python三种编程语言。Spark内核使用Scala语言编写,通过基于Scala的函数式编程特性,在不同的计算层面进行抽象,代码设计非常优秀。
1.2RDD抽象
RDD(Resilient Distributed Datasets),弹性分布式数据集,它是对分布式数据集的一种内存抽象,通过受限的共享内存方式来提供容错性,同时这种内存模型使得计算比传统的数据流模型要高效。RDD具有5个重要的特性,如下图所示:

上图展示了2个RDD进行JOIN操作,体现了RDD所具备的5个主要特性,如下所示:
1)一组分区
2)计算每一个数据分片的函数
3)RDD上的一组依赖
4)可选,对于键值对RDD,有一个Partitioner(通常是HashPartitioner)
5)可选,一组Preferred location信息(例如,HDFS文件的Block所在location信息)
有了上述特性,能够非常好地通过RDD来表达分布式数据集,并作为构建DAG图的基础:首先抽象一次分布式计算任务的逻辑表示,最终将任务在实际的物理计算环境中进行处理执行。
1.3计算抽象(重点看下,也算是任务运行吧)

在描述Spark中的计算抽象,我们首先需要了解如下几个概念:
1)Application
用户编写的Spark程序,完成一个计算任务的处理。它是由一个Driver程序和一组运行于Spark集群上的Executor组成。
2)Job
用户程序中,每次调用Action时,逻辑上会生成一个Job,一个Job包含了多个Stage。即一个application对应于多个job
3)Stage
Stage包括两类:ShuffleMapStage和ResultStage,如果用户程序中调用了需要进行Shuffle计算的Operator,如groupByKey等,就会以Shuffle为边界分成ShuffleMapStage和ResultStage。stage的划分是根据宽依赖和窄依赖划分的 ,ShuffleMapStage是为底层shuffle操作提供数据源的stage,resultStage更像mapreduce里面的reduce操作,他是去手机shuffleMapStage里面所有数据,然后继续进行resultstage这个过程
4)TaskSet
基于Stage可以直接映射为TaskSet,一个TaskSet封装了一次需要运算的、具有相同处理逻辑的Task,这些Task可以并行计算,粗粒度的调度是以TaskSet为单位的。在stage里面可以生成taskset
5)Task
Task是在物理节点上运行的基本单位,Task包含两类:ShuffleMapTask和ResultTask,分别对应于Stage中ShuffleMapStage和ResultStage中的一个执行基本单元。
下面,我们看一下,上面这些基本概念之间的关系,如下图所示:
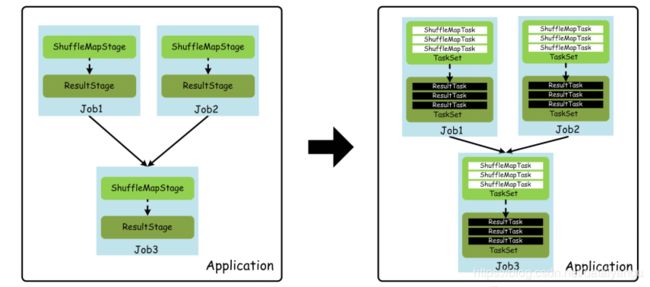
上图,为了简单,每个Job假设都很简单,并且只需要进行一次Shuffle处理,所以都对应2个Stage。实际应用中,一个Job可能包含若干个Stage,或者是一个相对复杂的Stage DAG。
上图的意思是job1 job2 的输出信息是job3的输入信息,根据stage的不同分成了不同的taskset
在Standalone模式下,默认使用的是FIFO这种简单的调度策略,在进行调度的过程中,大概流程如下图所示:

可以看到是一个先进先出的调度,因为对于taskset来说,其实是有先后顺序的
从用户提交Spark程序,最终生成TaskSet,而在调度时,通过TaskSetManager来管理一个TaskSet(包含一组可在物理节点上执行的Task),这里面TaskSet必须要按照顺序执行才能保证计算结果的正确性,因为TaskSet之间是有序依赖的(上溯到ShuffleMapStage和ResultStage),只有一个TaskSet中的所有Task都运行完成后,才能调度下一个TaskSet中的Task去执行。

1.4集群模式
Spark集群在设计的时候,并没有在资源管理的设计上对外封闭,而是充分考虑了未来对接一些更强大的资源管理系统,如YARN、Mesos等,所以Spark架构设计将资源管理单独抽象出一层,通过这种抽象能够构建一种适合企业当前技术栈的插件式资源管理模块,从而为不同的计算场景提供不同的资源分配与调度策略。Spark集群模式架构,如下图所示:
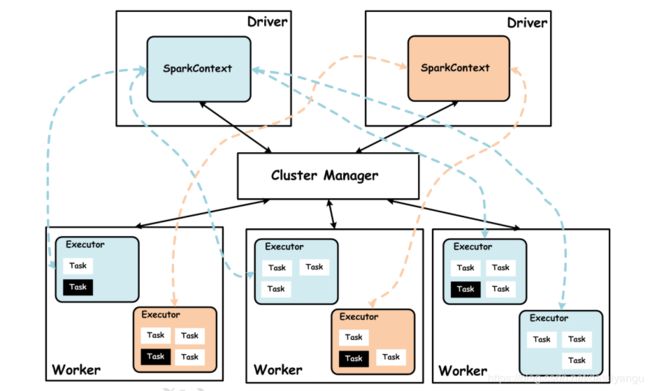
上图中,Spark集群Cluster Manager目前支持如下三种模式:
1)Standalone模式
Standalone模式是Spark内部默认实现的一种集群管理模式,这种模式是通过集群中的Master来统一管理资源,而与Master进行资源请求协商的是Driver内部的StandaloneSchedulerBackend(实际上是其内部的StandaloneAppClient真正与Master通信),后面会详细说明。
2)YARN模式
YARN模式下,可以将资源的管理统一交给YARN集群的ResourceManager去管理,选择这种模式,可以更大限度的适应企业内部已有的技术栈,如果企业内部已经在使用Hadoop技术构建大数据处理平台。
3)Mesos模式
随着Apache Mesos的不断成熟,一些企业已经在尝试使用Mesos构建数据中心的操作系统(DCOS),Spark构建在Mesos之上,能够支持细粒度、粗粒度的资源调度策略(Mesos的优势),也可以更好地适应企业内部已有技术栈。
那么,Spark中是怎么考虑满足这一重要的设计决策的呢?也就是说,如何能够保证Spark非常容易的让第三方资源管理系统轻松地接入进来。我们深入到类设计的层面看一下,如下图类图所示:

可以看出,Task调度直接依赖SchedulerBackend,SchedulerBackend与实际资源管理模块交互实现资源请求。这里面,CoarseGrainedSchedulerBackend是Spark中与资源调度相关的最重要的抽象,它需要抽象出与TaskScheduler通信的逻辑,同时还要能够与各种不同的第三方资源管理系统无缝地交互。实际上,CoarseGrainedSchedulerBackend内部采用了一种ResourceOffer的方式来处理资源请求。
1.5RPC网络通信抽象
Spark RPC层是基于优秀的网络通信框架Netty设计开发的,但是Spark提供了一种很好地抽象方式,将底层的通信细节屏蔽起来,而且也能够基于此来设计满足扩展性,比如,如果有其他不基于Netty的网络通信框架的新的RPC接入需求,可以很好地扩展而不影响上层的设计。RPC层设计,如下图类图所示:

任何两个Endpoint只能通过消息进行通信,可以实现一个RpcEndpoint和一个RpcEndpointRef:想要与RpcEndpoint通信,需要获取到该RpcEndpoint对应的RpcEndpointRef即可,而且管理RpcEndpoint和RpcEndpointRef创建及其通信的逻辑,统一在RpcEnv对象中管理。
1.6启动Standalone集群
Standalone模式下,Spark集群采用了简单的Master-Slave架构模式,Master统一管理所有的Worker,这种模式很常见,我们简单地看下Spark Standalone集群启动的基本流程,如下图所示:

可以看到,Spark集群采用的消息的模式进行通信,也就是EDA架构模式,借助于RPC层的优雅设计,任何两个Endpoint想要通信,发送消息并携带数据即可。上图的流程描述如下所示:
1)Master启动时首先创一个RpcEnv对象,负责管理所有通信逻辑
2)Master通过RpcEnv对象创建一个Endpoint,Master就是一个Endpoint,Worker可以与其进行通信
3)Worker启动时也是创一个RpcEnv对象
4)Worker通过RpcEnv对象创建一个Endpoint
5)Worker通过RpcEnv对,建立到Master的连接,获取到一个RpcEndpointRef对象,通过该对象可以与Master通信
6)Worker向Master注册,注册内容包括主机名、端口、CPU Core数量、内存数量
7)Master接收到Worker的注册,将注册信息维护在内存中的Table中,其中还包含了一个到Worker的RpcEndpointRef对象引用
8)Master回复Worker已经接收到注册,告知Worker已经注册成功
9)此时如果有用户提交Spark程序,Master需要协调启动Driver;而Worker端收到成功注册响应后,开始周期性向Master发送心跳
1.7核心组件
集群处理计算任务的运行时(用户提交了Spark程序),最核心的顶层组件就是Driver和Executor,它们内部管理很多重要的组件来协同完成计算任务,核心组件栈如下图所示:

Driver和Executor都是运行时创建的组件,一旦用户程序运行结束,他们都会释放资源,等待下一个用户程序提交到集群而进行后续调度。上图,我们列出了大多数组件,其中SparkEnv是一个重量级组件,他们内部包含计算过程中需要的主要组件,而且,Driver和Executor共同需要的组件在SparkEnv中也包含了很多。这里,我们不做过多详述,后面交互流程等处会说明大部分组件负责的功能。
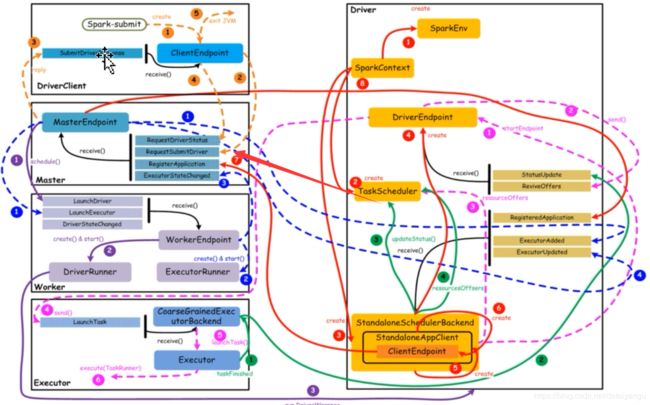
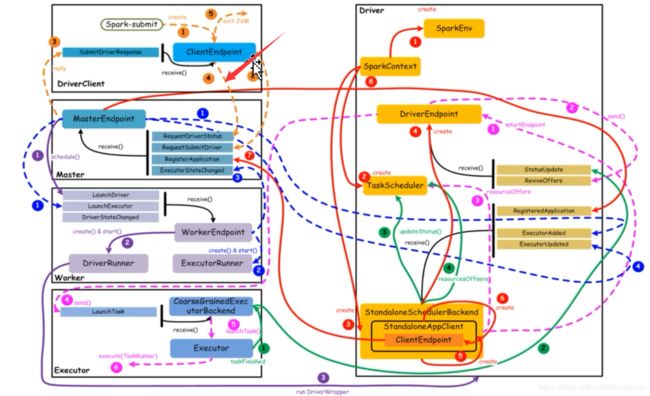
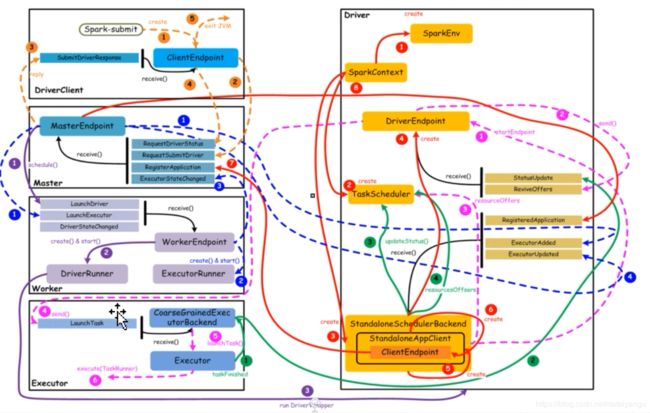
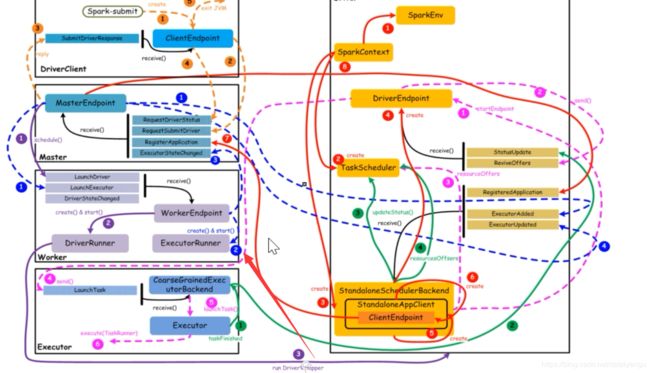
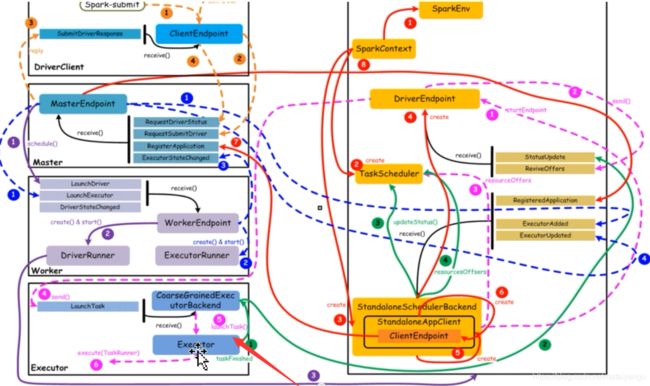
1.8核心组件交互流程(重点看,面试必问呦,6.2 、 第七章、8.2有更加详细的根据源码的解释,看一遍)
在Standalone模式下,Spark中各个组件之间交互还是比较复杂的,但是对于一个通用的分布式计算系统来说,这些都是非常重要而且比较基础的交互。首先,为了理解组件之间的主要交互流程,我们给出一些基本要点:
一个Application会启动一个Driver
一个Driver负责跟踪管理该Application运行过程中所有的资源状态和任务状态
一个Driver会管理一组Executor
一个Executor只执行属于一个Driver的Task
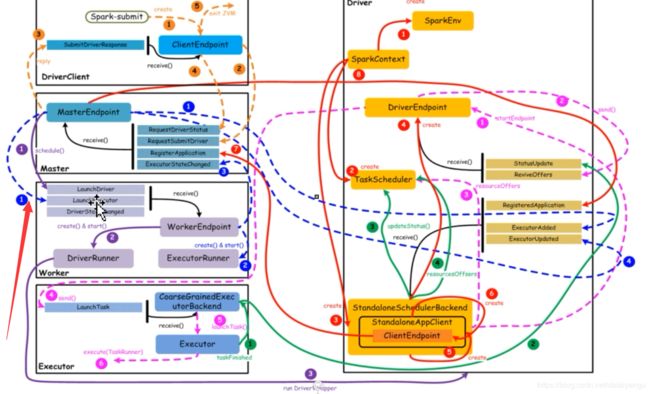
核心组件之间的主要交互流程,如下图所示:

【橙色:应用提交】–>【 紫色:启动Driver的进程】 -->【红色:注册application】–>【蓝色:启动Executor进程】 -->【粉色:启动Task执行】–>【绿色:Task进行完成】(这里说的颜色是图中的线条的颜色)
上图中,通过不同颜色或类型的线条,给出了如下6个核心的交互流程,我们会详细说明:
橙色:提交用户Spark程序
用户提交一个Spark程序,主要的流程如下所示:
1)用户spark-submit脚本提交一个Spark程序(左上角),会在一个新的jvm中有一个Driverclient,会创建一个ClientEndpoint对象,该对象负责与Master通信交互
2)ClientEndpoint向Master发送一个RequestSubmitDriver消息,表示提交用户程序,也就是spark submit后面提交的jar包
3)Master收到RequestSubmitDriver消息,向ClientEndpoint回复SubmitDriverResponse,表示用户程序已经完成注册
4)ClientEndpoint向Master发送RequestDriverStatus消息,请求Driver状态
5)如果当前用户程序对应的Driver已经启动,则ClientEndpoint直接退出,完成提交用户程序
紫色:启动Driver进程
当用户提交用户Spark程序后,需要启动Driver来处理用户程序的计算逻辑,完成计算任务,这时Master协调需要启动一个Driver,具体流程如下所示:
1)Maser内存中维护着用户提交计算的任务Application,每次内存结构变更都会触发调度,向Worker发送LaunchDriver请求
2)Worker收到LaunchDriver消息,会启动一个DriverRunner线程去执行LaunchDriver的任务
3)DriverRunner线程在Worker上启动一个新的JVM实例(run DriverWrapper,最后右边的Driver),该JVM实例内运行一个Driver进程,该Driver会创建SparkContext对象
注意:这个Driver是在某一个worker上,因为目前演示的流程是cluster模式,如果用的client模式,driver就是在submit这台机器上启动的
创建一个driver在driver里面运行我的程序
红色:注册Application
Dirver启动以后,它会创建SparkContext对象,初始化计算过程中必需的基本组件,并向Master注册Application,流程描述如下:
1)创建SparkEnv对象,创建并管理一些数基本组件
2)创建TaskScheduler,负责Task调度
3)创建StandaloneSchedulerBackend(运行程序或者协调资源,都是通过他来做),负责与ClusterManager进行资源协商
4)创建DriverEndpoint,其它组件可以与Driver进行通信(和masterEndpoint和ClientEndpoint的作用是一样的)
5)在StandaloneSchedulerBackend内部创建一个StandaloneAppClient,负责处理与Master的通信交互
6)StandaloneAppClient创建一个ClientEndpoint,实际负责与Master通信
7)ClientEndpoint向Master发送RegisterApplication消息,注册Application(主要是driver和master进行通信的),在driver中可以看到有两个rpc端点,
8)Master收到RegisterApplication请求后,回复ClientEndpoint一个RegisteredApplication消息,表示已经注册成功
蓝色:启动Executor进程
1)Master向Worker发送LaunchExecutor消息,请求启动Executor;同时Master会向Driver发送ExecutorAdded消息,表示Master已经新增了一个Executor(此时还未启动)
2)Worker收到LaunchExecutor消息,会启动一个ExecutorRunner线程去执行LaunchExecutor的任务
3)Worker向Master发送ExecutorStageChanged消息,通知Executor状态已发生变化
4)Master向Driver发送ExecutorUpdated消息,此时Executor已经启动
粉色:启动Task执行
1)StandaloneSchedulerBackend启动一个DriverEndpoint
2)DriverEndpoint启动后,会周期性地检查Driver维护的Executor的状态,如果有空闲的Executor便会调度任务执行
3)DriverEndpoint向TaskScheduler发送Resource Offer请求(能够把RDD转换啊这些,能够创建task)
4)如果有可用资源启动Task,则DriverEndpoint向Executor发送LaunchTask请求(同样是启动一个jvm,和上面的driverclient这个jvm同等重要)
5)Executor进程内部的CoarseGrainedExecutorBackend调用内部的Executor线程的launchTask方法启动Task
6)Executor线程内部维护一个线程池,创建一个TaskRunner线程并提交到线程池执行
绿色:Task运行完成
1)Executor进程内部的Executor线程通知CoarseGrainedExecutorBackend,Task运行完成
2)CoarseGrainedExecutorBackend向DriverEndpoint发送StatusUpdated消息,通知Driver运行的Task状态发生变更
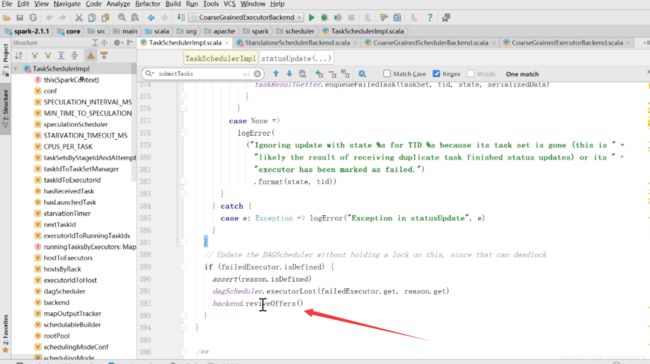
3)StandaloneSchedulerBackend调用TaskScheduler的updateStatus方法更新Task状态
4)StandaloneSchedulerBackend继续调用TaskScheduler的resourceOffers方法,调度其他任务运行
有下一个任务过来,还是走这条路,然后如此往复,最后所有的任务完成了,然后driver结束,driver结束之后,会告诉master,当前的application结束了,然后告诉相应的woker,干掉executer,这个时候完全结束
通过查看submit的脚本,知道最后调用的是org.apache.spark.deploy.SparkSubmit
一起来看看这个类的源码把(更加详情,可以看下面的6.2sparksubmit启动流程
首先看一下这个main方法

这个main方法中传入了一些参数,new 一个sparkSubmitArguments
1.9Block管理
Block管理,主要是为Spark提供的Broadcast机制提供服务支撑的。Spark中内置采用TorrentBroadcast实现,该Broadcast变量对应的数据(Task数据)或数据集(如RDD),默认会被切分成若干4M大小的Block,Task运行过程中读取到该Broadcast变量,会以4M为单位的Block为拉取数据的最小单位,最后将所有的Block合并成Broadcast变量对应的完整数据或数据集。将数据切分成4M大小的Block,Task从多个Executor拉取Block,可以非常好地均衡网络传输负载,提高整个计算集群的稳定性。
通常,用户程序在编写过程中,会对某个变量进行Broadcast,该变量称为Broadcast变量。在实际物理节点的Executor上执行Task时,需要读取Broadcast变量对应的数据集,那么此时会根据需要拉取DAG执行流上游已经生成的数据集。采用Broadcast机制,可以有效地降低数据在计算集群环境中传输的开销。具体地,如果一个用户对应的程序中的Broadcast变量,对应着一个数据集,它在计算过程中需要拉取对应的数据,如果在同一个物理节点上运行着多个Task,多个Task都需要该数据,有了Broadcast机制,只需要拉取一份存储在本地物理机磁盘即可,供多个Task计算共享。
另外,用户程序在进行调度过程中,会根据调度策略将Task计算逻辑数据(代码)移动到对应的Worker节点上,最优情况是对本地数据进行处理,那么代码(序列化格式)也需要在网络上传输,也是通过Broadcast机制进行传输,不过这种方式是首先将代码序列化到Driver所在Worker节点,后续如果Task在其他Worker中执行,需要读取对应代码的Broadcast变量,首先就是从Driver上拉取代码数据,接着其他晚一些被调度的Task可能直接从其他Worker上的Executor中拉取代码数据。
我们通过以Broadcast变量taskBinary为例,说明Block是如何管理的,如下图所示:

上图中,Driver负责管理所有的Broadcast变量对应的数据所在的Executor,即一个Executor维护一个Block列表。在Executor中运行一个Task时,执行到对应的Broadcast变量taskBinary,如果本地没有对应的数据,则会向Driver请求获取Broadcast变量对应的数据,包括一个或多个Block所在的Executor列表,然后该Executor根据Driver返回的Executor列表,直接通过底层的BlockTransferService组件向对应Executor请求拉取Block。Executor拉取到的Block会缓存到本地,同时向Driver报告该Executor上存在的Block信息,以供其他Executor执行Task时获取Broadcast变量对应的数据。
1.10整体应用
用户通过spark-submit提交或者运行spark-shell REPL,集群创建Driver,Driver加载Application,最后Application根据用户代码转化为RDD,RDD分解为Tasks,Executor执行Task等系列知识,整体交互蓝图如下:

1)Client运行时向Master发送启动驱动申请(发送RequestSubmitDriver指令)
2)Master调度可用Worker资源进行驱动安装(发送LaunchDriver指令)
3)Worker运行DriverRunner进行驱动加载,并向Master发送应用注册请求(发送RegisterApplication指令)
4)Master调度可用Worker资源进行应用的Executor安装(发送LaunchExecutor指令)
5)Executor安装完毕后向Driver注册驱动可用Executor资源(发送RegisterExecutor指令)
6)最后是运行用户代码时,通过DAGScheduler,TaskScheduler封装为可以执行的TaskSetManager对象
7)TaskSetManager对象与Driver中的Executor资源进行匹配,在队形的Executor中发布任务(发送LaunchTask指令)
8)TaskRunner执行完毕后,调用DriverRunner提交给DAGScheduler,循环7.直到任务完成
第2章脚本解析
在看源码之前,我们一般会看相关脚本了解其初始化信息以及Bootstrap类,Spark也不例外,而Spark中相关的脚本如下:
%SPARK_HOME%/sbin/start-master.sh
%SPARK_HOME%/sbin/start-slaves.sh
%SPARK_HOME%/sbin/start-all.sh
%SPARK_HOME%/bin/spark-submit
启动脚本中对于公共处理部分进行抽取为独立的脚本,如下:
| spark-config.sh | 初始化环境变量 SPARK_CONF_DIR, PYTHONPATH |
|---|---|
| bin/load-spark-env.sh | 初始化环境变量SPARK_SCALA_VERSION, |
| 调用%SPARK_HOME%/conf/spark-env.sh加载用户自定义环境变量 | 调用%SPARK_HOME%/conf/spark-env.sh加载用户自定义环境变量 |
| conf/spark-env.sh | 用户自定义配置 |
一般是在spark的bin 和 sbin 目录下
2.1start-daemon.sh
主要完成进程相关基本信息初始化,然后调用bin/spark-class进行守护进程启动,该脚本是创建端点的通用脚本,三端各自脚本都会调用spark-daemon.sh脚本启动各自进程

1)初始化 SPRK_HOME,SPARK_CONF_DIR,SPARK_IDENT_STRING,SPARK_LOG_DIR环境变量(如果不存在)
2)初始化日志并测试日志文件夹读写权限,初始化PID目录并校验PID信息
3)调用/bin/spark-class脚本,/bin/spark-class见下
2.2spark-class
Master调用举例:
bin/spark-class --class org.apache.spark.deploy.master.Master --host $SPARK_MASTER_HOST --port $SPARK_MASTER_PORT --webui-port $SPARK_MASTER_WEBUI_PORT O R I G I N A L A R G S 1 ) 初 始 化 R U N N E R ( j a v a ) , S P A R K J A R S D I R ( 2 ) 调 用 ( " O R I G I N A L A R G S 1 ) 初 始 化 R U N N E R ( j a v a ) , S P A R K J A R S D I R ( 2 ) 调 用 ( " O R I G I N A L A R G S 1 ) 初 始 化 R U N N E R ( j a v a ) , S P A R K J A R S D I R ( ORIGINALARGS1)初始化RUNNER(java),SPARKJARSDIR(2)调用("ORIGINALARGS1)初始化RUNNER(java),SPARKJARSDIR(2)调用(" ORIGINAL_ARGS1)初始化 RUNNER(java),SPARK_JARS_DIR(%SPARK_HOME%/jars),LAUNCH_CLASSPATH信息2)调用( " ORIGINALARGS1)初始化RUNNER(java),SPARKJARSDIR(2)调用("ORIGINALARGS1)初始化RUNNER(java),SPARKJARSDIR(2)调用("ORIGINALARGS1)初始化RUNNER(java),SPARKJARSDIR(MASTER"@")
2.5start-all.sh
属于快捷脚本,内部调用start-master.sh与start-slaves.sh脚本,并无额外工作
启动所有的spark程序
在哪个上面执行这个master,就会在哪个里面设为master
如果在slave里面设置了node,会逐步的启动这个worker
加载了配置文件
直接调用了start-master脚本
2.6spark-submit
任务提交的基本脚本,流程如下:
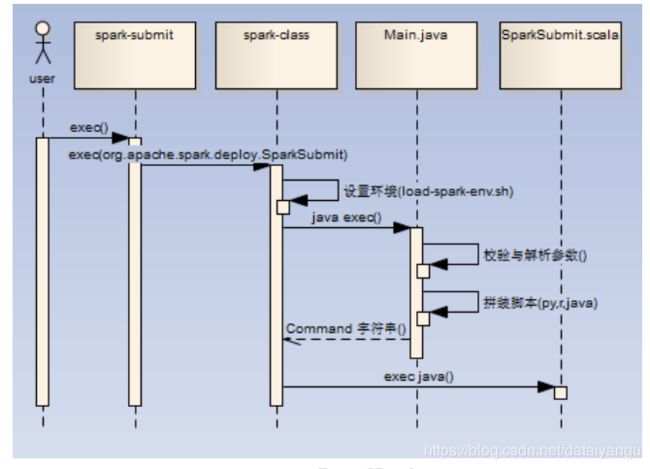
1)直接调用spark-class脚本进行进程创建(./spark-submit --class org.apache.spark.examples.SparkPi --master spark://master01:7077 …/examples/jars/spark-examples_2.11-2.1.0.jar 10)
2)如果是java/scala任务,那么最终调用SparkSubmit.scala进行任务处理(/opt/jdk1.7.0_79/bin/java -cp /opt/spark-2.1.0/conf/:/opt/spark-2.1.0/jars/*:/opt/hadoop-2.6.4/etc/hadoop/ -Xmx1g -XX:MaxPermSize=256m org.apache.spark.deploy.SparkSubmit --master spark://zqh:7077 --class org.apache.spark.examples.SparkPi …/examples/jars/spark-examples_2.11-2.1.0.jar 10)
-cp是把后面的jar包都给引用了,执行了org.apache.spark.deploy.SparkSubmit这个类
所以这个提交的脚本最终还是走的SparkSubmit
第3章Spark通信架构(重点看下)
Spark作为分布式计算框架,多个节点的设计与相互通信模式是其重要的组成部分。
Spark一开始使用 Akka 作为内部通信部件。在Spark 1.3年代,为了解决大块数据(如Shuffle)的传输问题,Spark引入了Netty通信框架。到了 Spark 1.6, Spark可以配置使用 Akka 或者 Netty 了,这意味着 Netty 可以完全替代 Akka了。再到 Spark 2, Spark 已经完全抛弃 Akka了,全部使用Netty了。
为什么呢?官方的解释是:
1)很多Spark用户也使用Akka,但是由于Akka不同版本之间无法互相通信,这就要求用户必须使用跟Spark完全一样的Akka版本,导致用户无法升级Akka。
2)Spark的Akka配置是针对Spark自身来调优的,可能跟用户自己代码中的Akka配置冲突。
3)Spark用的Akka特性很少,这部分特性很容易自己实现。同时,这部分代码量相比Akka来说少很多,debug比较容易。如果遇到什么bug,也可以自己马上fix,不需要等Akka上游发布新版本。而且,Spark升级Akka本身又因为第一点会强制要求用户升级他们使用的Akka,对于某些用户来说是不现实的。
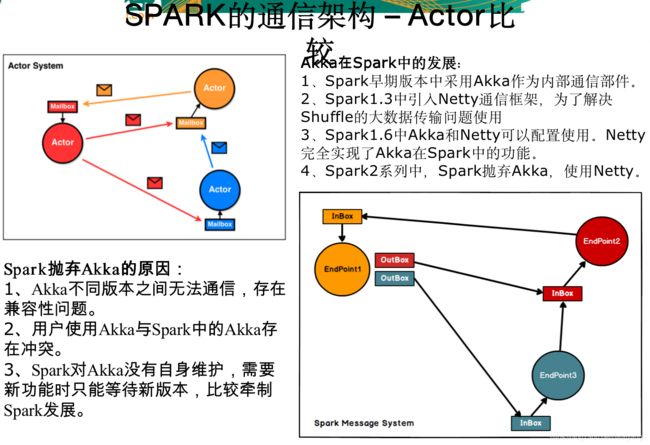
如上图,spark的通信框架和akka相比,多了一个outBox,不过总体是差不多的
3.1通信组件概览
对源码分析,对于设计思路理解如下:

注意点:
一个RpcEndpoint有一个inbox,但是假如当前的RpcEndpoint要发给三个RpcEndpoint,那会对已经有三个outbox。
RpcEndpoint和Dispatcher和TransportServer是成对出现的,也就是接收到消息之后,TransportServer给了Dispatcher,给完之后Dispatcher把消息放到inbox里面,放完之后RpcEndpoint会异步消费这个消息,读取这个消息。
如果RpcEndpoint要发数据,直接调用Dispatcher,Dispatcher把消息给了outBox
TransportClient和outBox也是一一对应的关系,也就是Dispatcher把消息给了outBox之后,TransportClient就直接把消息往外发送 。
然后就是另一个TransportServer接收消息,然后重复上面的步骤了
1)RpcEndpoint:RPC端点 ,Spark针对于每个节点(Client/Master/Worker)都称之一个Rpc端点 ,且都实现RpcEndpoint接口,内部根据不同端点的需求,设计不同的消息和不同的业务处理,如果需要发送(询问)则调用Dispatcher
2)RpcEnv:RPC上下文环境,每个Rpc端点运行时依赖的上下文环境称之为RpcEnv
3)Dispatcher:消息分发器,针对于RPC端点需要发送消息或者从远程RPC接收到的消息,分发至对应的指令收件箱/发件箱。如果指令接收方是自己存入收件箱,如果指令接收方为非自身端点,则放入发件箱
4)Inbox:指令消息收件箱,一个本地端点对应一个收件箱,Dispatcher在每次向Inbox存入消息时,都将对应EndpointData加入内部待Receiver Queue中,另外Dispatcher创建时会启动一个单独线程进行轮询Receiver Queue,进行收件箱消息消费
5)OutBox:指令消息发件箱,一个远程端点对应一个发件箱,当消息放入Outbox后,紧接着将消息通过TransportClient发送出去。消息放入发件箱以及发送过程是在同一个线程中进行,这样做的主要原因是远程消息分为RpcOutboxMessage, OneWayOutboxMessage两种消息,而针对于需要应答的消息直接发送且需要得到结果进行处理
6)TransportClient:Netty通信客户端,根据OutBox消息的receiver信息,请求对应远程TransportServer
7)TransportServer:Netty通信服务端,一个RPC端点一个TransportServer,接受远程消息后调用Dispatcher分发消息至对应收发件箱
注意:
TransportClient与TransportServer通信虚线表示两个RpcEnv之间的通信,图示没有单独表达式
一个Outbox一个TransportClient,图示没有单独表达式
一个RpcEnv中存在两个RpcEndpoint,一个代表本身启动的RPC端点,另外一个为 RpcEndpointVerifier

如果有两个master、三个worker,master1和master2只有一个inbox,因为master里面只有一个端点,master要和三个worker通信,所以有三个outbox
spark的通信架构–类图

首先看红色的RpcEnv上下文环境,然后绿色的PrcEndPoint,RpcEndpointRef之前akka框架说过,如果向另外一个actor通信,只要获取到actor的ref就可以了,然后直接向ref通信就行,而不用拿到RpcEndpoint的实例,然后看RpcEndpoint下面的ThreadSafeRpcEndpoint,对RpcEndpoint封装了一下,让他变成线程安全的,然后master和worker再去继承它,因为继承了他,所以master和worker其实也是RpcEndpoint。然后看RpcEnv的上面,有一个NettyRpcEnvFactory,这是最终创建RpcEnv的工厂类,而这个RpcEnv其实是一个抽象类,真正的实现是RpcEnv右边的NettyRpcEnv,在实现里面包装了TransportClient和TransportServer、Dispatcher。TransportContext下面的灰色区域,是通信的时候编码解码这些过程
去查看源码

RpcEnv是一个抽象类,里面有create方法,是用来创建Rpc应用的 ,包括还有setupEndPoint方法,这个方法就是为了注册端点
ctrl+h后
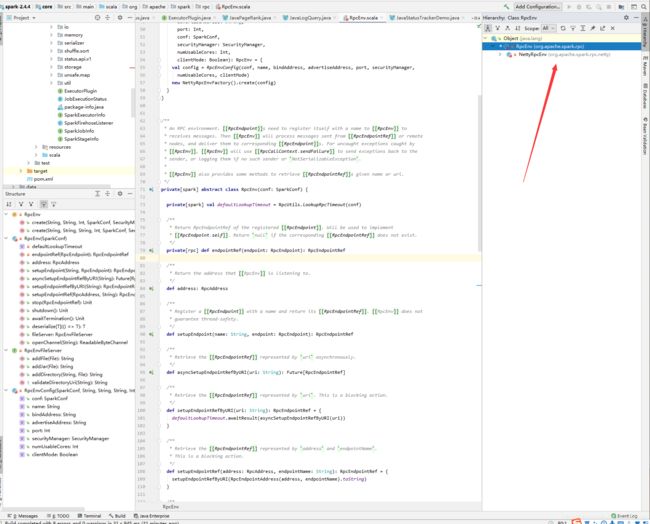
发现这个类的继承类nettyRpcEnv,在这里我们看到了消息分发器

上面左下方的框中能够看到很多信息,包括clientfactory,outbox,createServer,是将transportServer放了进来,这里注意下send方法其实是dispatcher的send,这就和上面的图吻合起来了。

在Dispatcher类中,endpoint被封装在了EndpointData中
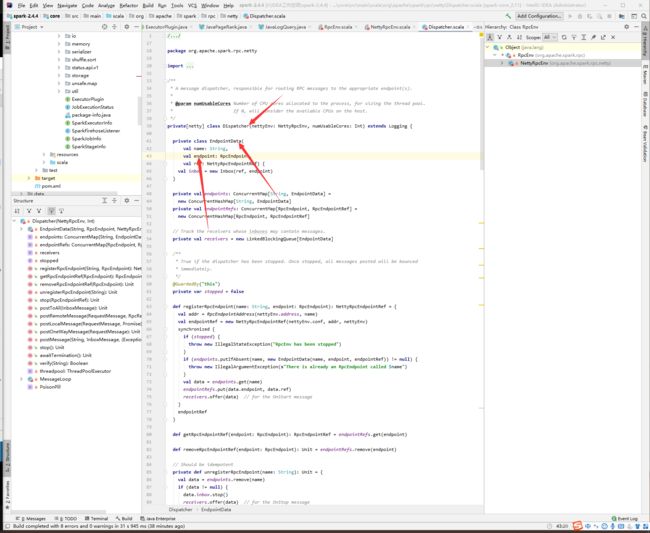
所有的post方法最后都是调用的postmessage
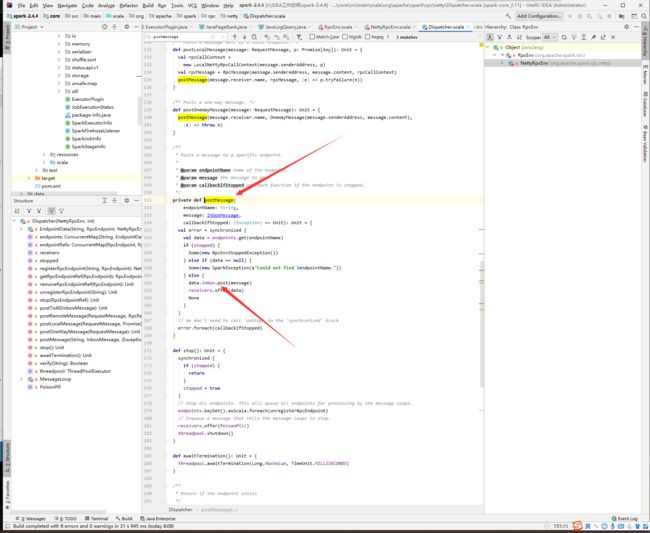
最后调用了inbox.post方法
在inbox里面处理数据是怎么处理的呢?

在RpcEndPoint里面有几个方法
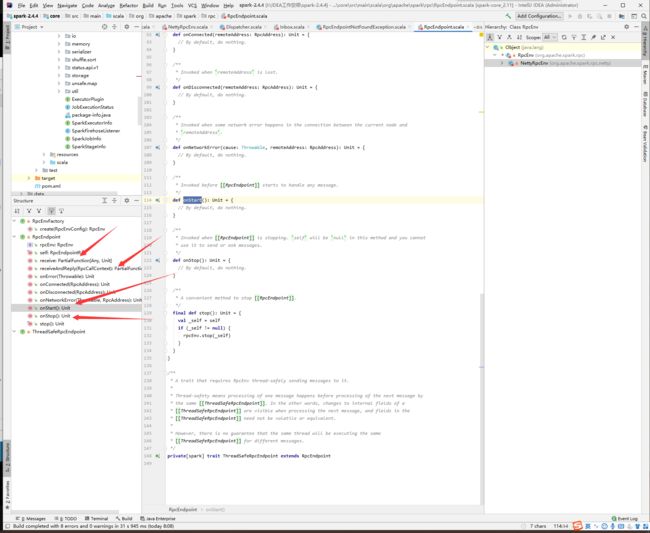
recieve是只接收消息
receiveAndReply是接收消息后进行处理
onStart是在端点启动的时候执行,就是在端点启动的时候,自动往inbox里面发送一个onstart消息,当inbox在处理消息的时候,就处理了onstart方法
主要需要注意的是,每一个rpcpoint都要实现哪些方法(recieve、receiveAndReply、onStart),rpcEnv,是谁构造了他呢?NettyRpcEnvFactory,发现最后创建的是NettyRpcEnv
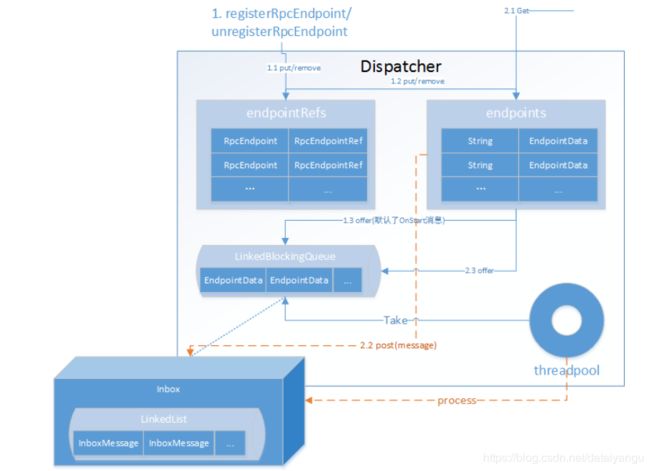
3.2Endpoint启动过程
启动的流程如下:
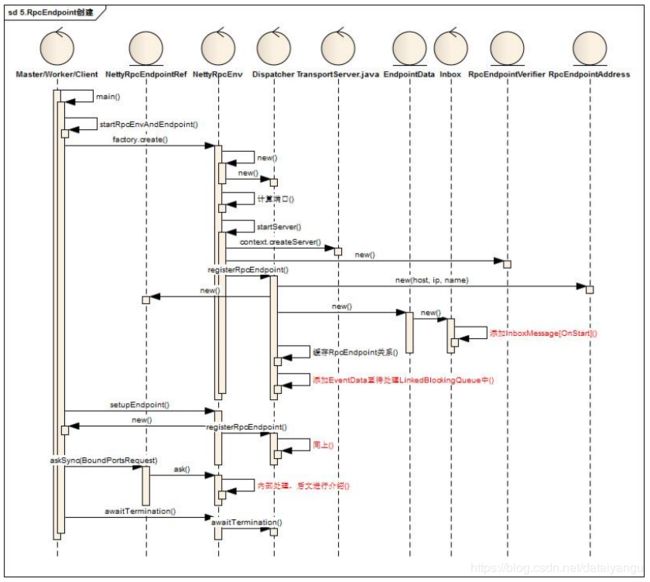
Endpoint启动后,默认会向Inbox中添加OnStart消息,不同的端点(Master/Worker/Client)消费OnStart指令时,进行相关端点的启动额外处理
Endpoint启动时,会默认启动TransportServer,且启动结束后会进行一次同步测试rpc可用性(askSync-BoundPortsRequest)
Dispatcher作为一个分发器,内部存放了Inbox,Outbox的等相关句柄和存放了相关处理状态数据,结构大致如下
3.3Endpoint Send&Ask流程
Endpoint的消息发送与请求流程,如下:

Endpoint根据业务需要存入两个维度的消息组合:send/ask某个消息,receiver是自身与非自身
1)OneWayMessage: send + 自身, 直接存入收件箱
2)OneWayOutboxMessage:send + 非自身,存入发件箱并直接发送
3)RpcMessage: ask + 自身, 直接存入收件箱,另外还需要存入LocalNettyRpcCallContext,需要回调后再返回
4)RpcOutboxMessage: ask + 非自身,存入发件箱并直接发送,,需要回调后再返回
3.4Endpoint receive流程
Endpoint的消息的接收,流程如下:

上图 ServerBootstrap为Netty启动服务,SocketChanel为Netty数据通道
上述包含TransportSever启动与消息接受两个流程
3.5Endpoint Inbox处理流程
Spark在Endpoint的设计上核心设计即为Inbox与Outbox,其中Inbox核心要点为:
1)内部的处理流程拆分为多个消息指令(InboxMessage)存放入Inbox
2)当Dispatcher启动最后,会启动一个名为【dispatcher-event-loop】的线程扫描Inbox待处理InboxMessage,并调用Endpoint根据InboxMessage类型做相应处理
3)当Dispatcher启动最后,默认会向Inbox存入OnStart类型的InboxMessage,Endpoint在根据OnStart指令做相关的额外启动工作,三端启动后所有的工作都是对OnStart指令处理衍生出来的,因此可以说OnStart指令是相互通信的源头
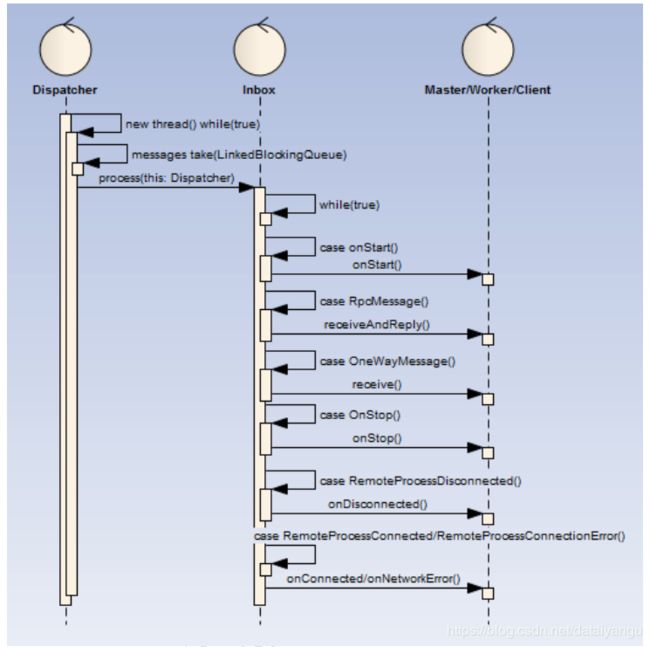
消息指令类型大致如下三类
1)OnStart/OnStop
2)RpcMessage/OneWayMessage
3)RemoteProcessDisconnected/RemoteProcessConnected/RemoteProcessConnectionError
3.6Endpoint画像

第4章Master节点启动
Master作为Endpoint的具体实例,下面我们介绍一下Master启动以及OnStart指令后的相关工作
4.1脚本概览
下面是一个举例:
/opt/jdk1.7.0_79/bin/java
-cp /opt/spark-2.1.0/conf/:/opt/spark-2.1.0/jars/*:/opt/hadoop-2.6.4/etc/hadoop/
-Xmx1g
-XX:MaxPermSize=256m
org.apache.spark.deploy.master.Master
--host zqh
--port 7077
- 1
- 2
- 3
- 4
- 5
- 6
- 7
所以最终走的是org.apache.spark.deploy.master.Master这个类,这个类的内部实现和下面的这个图是紧密相关的。


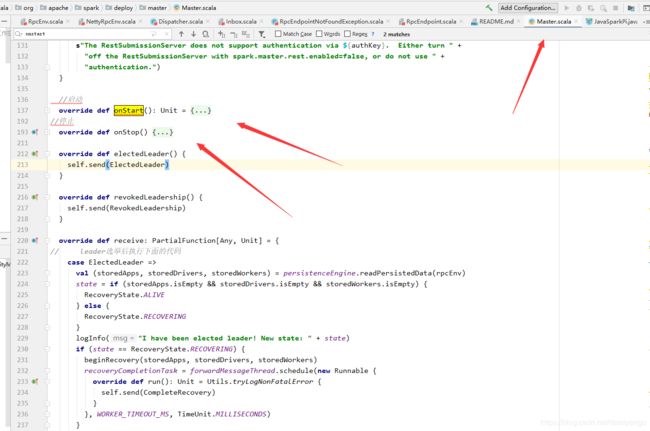
onstart和onstop方法通过字面就能够理解了,就是启动和停止

核心方法receive
receiveAndReply
看完了master,现在看worker

可以看到这里也有rpcEnv等,多了一个masterAddress,是对master的一个引用
同样有onstart receive receiveAndReply等方法
RegisterWorker是一个消息
注册worker成功之后会有心跳,具体详情看代码。
4.2启动流程
Master的启动流程如下:

1)SparkConf:加载key以spark.开头的系统属性(Utils.getSystemProperties)
2)MasterArguments:
a)解析Master启动的参数(–ip -i --host -h --port -p --webui-port --properties-file)
b)将–properties-file(没有配置默认为conf/spark-defaults.conf)中spark.开头的配置存入SparkConf
3)NettyRpcEnv中的内部处理遵循RpcEndpoint统一处理,这里不再赘述
4)BoundPortsResponse返回rpcEndpointPort,webUIPort,restPort真实端口
5)最终守护进程会一直存在等待结束信awaitTermination
4.3OnStart监听事件
Master的启动完成后异步执行工作如下:
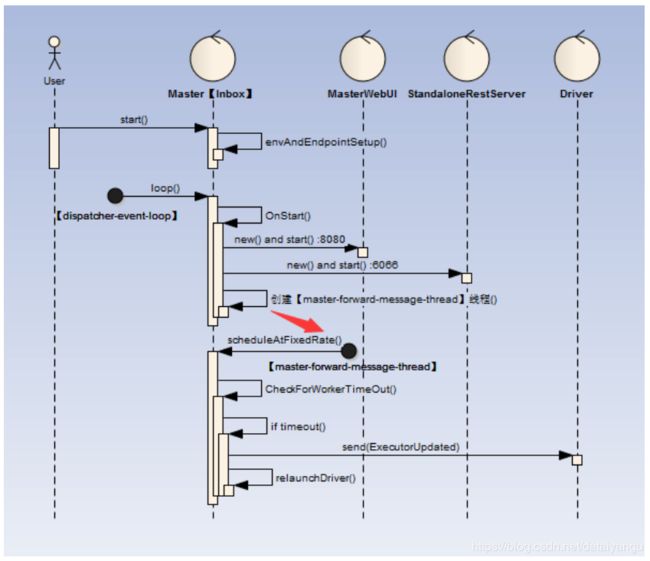
1)【dispatcher-event-loop】线程扫描到OnStart指令后会启动相关MasterWebUI(默认端口8080),根据配置选择安装ResetServer(默认端口6066)
2)另外新起【master-forward-message-thread】线程定期进行worker心跳是否超时
3)如果Worker心跳检测超时,那么对Worker下的发布的所有任务所属Driver进行ExecutorUpdated发送,同时自己在重新LaunchDriver
4.4RpcMessage处理(receiveAndReply)
| 消息实例 | 发起方 | 接收方 | 说明 |
|---|---|---|---|
| RequestSubmitDriver | Client | Master | 提交驱动程序 |
| RequestKillDriver | Client | Master | |
| RequestDriverStatus | Client | Master | |
| RequestMasterState | MasterWebUI | Master | |
| BoundPortsRequest | Master | Master | |
| RequestExecutors | StandaloneAppClient | Master | |
| KillExecutors | StandaloneAppClient | Master |
五、OneWayMessage处理(receive)
| 消息实例 | 发起方 | 接收方 | 说明 |
|---|---|---|---|
| ElectedLeader | Master | Master | |
| CompleteRecovery | Master | Master | |
| RevokedLeadership | Master | Master | |
| RegisterWorker | Worker | Master | |
| RegisterApplication | StandaloneAppClient | Master | |
| UnregisterApplication | StandaloneAppClient | Master | |
| ExecutorStateChanged | Worker/ExecutorRunner | Master | |
| DriverStateChanged | DriverRunner/Master | Master | |
| Heartbeat | Worker | Master | |
| MasterChangeAcknowledged | StandaloneAppClient | Master | |
| WorkerSchedulerStateResponse | Worker | Master | |
| WorkerLatestState | Worker | Master | |
| CheckForWorkerTimeOut | Master | Master |
4.5Master对RpcMessage/OneWayMessage处理逻辑
这部分对整体Master理解作用不是很大且理解比较抽象,可以先读后续内容,回头再考虑看这部分内容,或者不读

第5章Work节点启动
Worker作为Endpoint的具体实例,下面我们介绍一下Worker启动以及OnStart指令后的额外工作
5.1脚本概览
下面是一个举例:
/opt/jdk1.7.0_79/bin/java
-cp /opt/spark-2.1.0/conf/:/opt/spark-2.1.0/jars/*:/opt/hadoop-2.6.4/etc/hadoop/
-Xmx1g
-XX:MaxPermSize=256m
org.apache.spark.deploy.worker.Worker
--webui-port 8081
spark://master01:7077
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.2启动流程
Worker的启动流程如下:

1)SparkConf:加载key以spark.开头的系统属性(Utils.getSystemProperties)
2)WorkerArguments:
a)解析Master启动的参数(–ip -i --host -h --port -p --cores -c --memory -m --work-dir --webui-port --properties-file)
b)将–properties-file(没有配置默认为conf/spark-defaults.conf)中spark.开头的配置存入SparkConf
c)在没有配置情况下,cores默认为服务器CPU核数
d)在没有配置情况下,memory默认为服务器内存减1G,如果低于1G取1G
e)webUiPort默认为8081
3)NettyRpcEnv中的内部处理遵循RpcEndpoint统一处理,这里不再赘述
4)最终守护进程会一直存在等待结束信awaitTermination
5.3OnStart监听事件
Worker的启动完成后异步执行工作如下
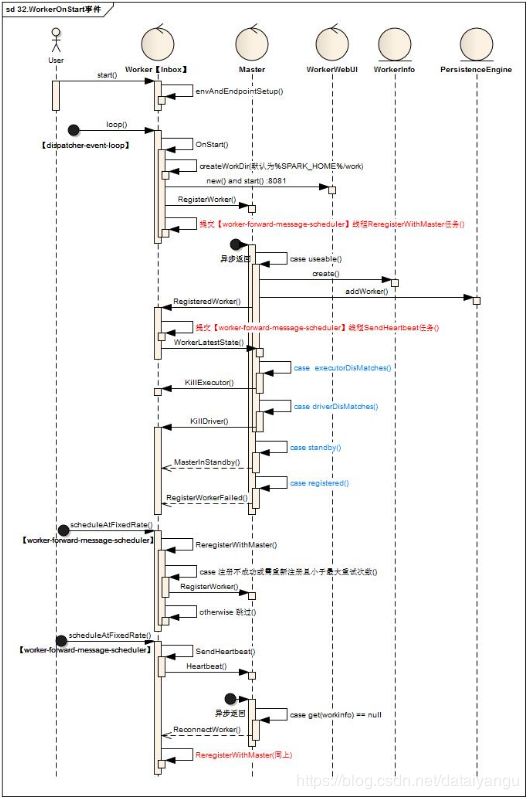
1)【dispatcher-event-loop】线程扫描到OnStart指令后会启动相关WorkerWebUI(默认端口8081)
2)Worker向Master发起一次RegisterWorker指令
3)另起【master-forward-message-thread】线程定期执行ReregisterWithMaster任务,如果注册成功(RegisteredWorker)则跳过,否则再次向Master发起RegisterWorker指令,直到超过最大次数报错(默认16次)
4)Master如果可以注册,则维护对应的WorkerInfo对象并持久化,完成后向Worker发起一条RegisteredWorker指令,如果Master为standby状态,则向Worker发起一条MasterInStandby指令
5)Worker接受RegisteredWorker后,提交【master-forward-message-thread】线程定期执行SendHeartbeat任务,,完成后向Worker发起一条WorkerLatestState指令
6)Worker发心跳检测,会触发更新Master对应WorkerInfo对象,如果Master检测到异常,则发起ReconnectWorker指令至Worker,Worker则再次执行ReregisterWithMaster工作
5.4RpcMessage处理(receiveAndReply)
| 消息实例 | 发起方 | 接收方 | 说明 |
|---|---|---|---|
| RequestWorkerState | WorkerWebUI | Worker | 返回WorkerStateResponse |
5.5OneWayMessage处理(receive)
| 消息实例 | 发起方 | 接收方 | 说明 |
|---|---|---|---|
| SendHeartbeat | Worker | Worker | |
| WorkDirCleanup | Worker | Worker | |
| ReregisterWithMaster | Worker | Worker | |
| MasterChanged | Master | Worker | |
| ReconnectWorker | Master | Worker | |
| LaunchExecutor | Master | Worker | |
| ApplicationFinished | Master | Worker | |
| KillExecutor | Master | Worker | |
| LaunchDriver | Master | Worker | |
| KillDriver | Master | Worker | |
| DriverStateChanged | DriverRunner | Worker | |
| ExecutorStateChanged | ExecutorRunner | ExecutorStateChanged | ExecutorRunner |
| /Worker | Worker/Master | /Worker |
第6章Client启动流程
Client作为Endpoint的具体实例,下面我们介绍一下Client启动以及OnStart指令后的额外工作
6.1脚本概览
下面是一个举例:
/opt/jdk1.7.0_79/bin/java
-cp /opt/spark-2.1.0/conf/:/opt/spark-2.1.0/jars/*:/opt/hadoop-2.6.4/etc/hadoop/
-Xmx1g
-XX:MaxPermSize=256m
org.apache.spark.deploy.SparkSubmit
--master spark://zqh:7077
--class org.apache.spark.examples.SparkPi
../examples/jars/spark-examples_2.11-2.1.0.jar 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
6.2SparkSubmit启动流程
SparkSubmit的启动流程如下:
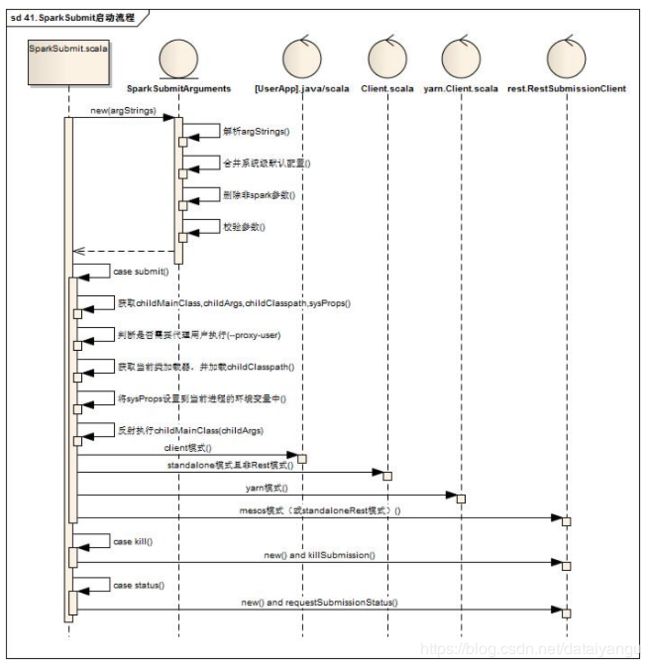
new了一个sparkSubmitArguments,传了参数,包括解析argstrings,合并系统级默认配置等等,然后执行完了之后,是spark sunmit(),这个submit中做了那些事情呢?获得childMainClass childArgs,加载了当前的类加载器,反射执行childMainClass
1)SparkSubmitArguments:
a)解析Client启动的参数
i.–name --master --class --deploy-mode
ii.–num-executors --executor-cores --total-executor-cores --executor-memory
iii.–driver-memory --driver-cores --driver-class-path --driver-java-options --driver-library-path
iv.–properties-file
v.–kill --status --supervise --queue
vi.–files --py-files
vii.–archives --jars --packages --exclude-packages --repositories
viii.–conf(解析存入Map : sparkProperties中)
ix.–proxy-user --principal --keytab --help --verbose --version --usage-error
b)合并–properties-file(没有配置默认为conf/spark-defaults.conf)文件配置项(不在–conf中的配置 )至sparkProperties
c)删除sparkProperties中不以spark.开头的配置项目
d)启动参数为空的配置项从sparkProperties中合并
e)根据action(SUBMIT,KILL,REQUEST_STATUS)校验各自必须参数是否有值
2)Case Submit:
a)获取childMainClass
i.[–deploy-mode] = clent(默认):用户任务启动类mainClass(–class)
ii.[–deploy-mode] = cluster & [–master] = spark:* & useRest:org.apache.spark.deploy.rest.RestSubmissionClient
iii.[–deploy-mode] = cluster & [–master] = spark:* & !useRest : org.apache.spark.deploy.Client
iv.[–deploy-mode] = cluster & [–master] = yarn: org.apache.spark.deploy.yarn.Client
v.[–deploy-mode] = cluster & [–master] = mesos:*: org.apache.spark.deploy.rest.RestSubmissionClient
b)获取childArgs(子运行时对应命令行组装参数)
i.[–deploy-mode] = cluster & [–master] = spark:* & useRest: 包含primaryResource与mainClass
ii.[–deploy-mode] = cluster & [–master] = spark:* & !useRest : 包含–supervise --memory --cores launch 【childArgs】, primaryResource, mainClass
iii.[–deploy-mode] = cluster & [–master] = yarn:–class --arg --jar/–primary-py-file/–primary-r-file
iv.[–deploy-mode] = cluster & [–master] = mesos:*: primaryResource
c)获取childClasspath
i.[–deploy-mode] = clent:读取–jars配置,与primaryResource信息(…/examples/jars/spark-examples_2.11-2.1.0.jar)
d)获取sysProps
i.将sparkPropertie中的所有配置封装成新的sysProps对象,另外还增加了一下额外的配置项目
e)将childClasspath通过当前的类加载器加载中
f)将sysProps设置到当前jvm环境中
g)最终反射执行childMainClass,传参为childArgs
sparkSubmitArguments

可以看到他的属性,很多都是spark在submit的时候能够指定的选项

master如果是yarn的,就初始化一些yarn的东西

重写了tostring,把这些都打印出来了
然后看SparkSubmit这个类
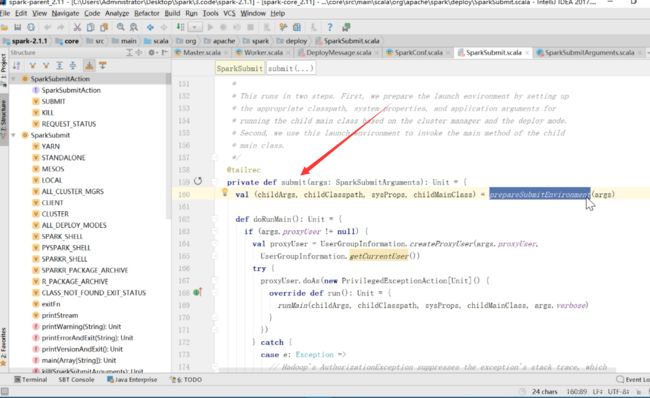
在这个方法中比较重要的prepareSubmitEnvironment,准备提交环境。

读一下英文的注释,一个是元组,一个是依赖,一个是系统属性,一个是main class

根据提交的不同,选择一些不同的模式

初始化一些参数,然后简单浏览一遍
在刚才的submit方法中传入的参数是什么,不知道,怎么办

看spark源码,除了下载源码直接看,也可以在项目中,打开源码,然后download sources,打断点,查看
这里定义了dorunmain 可以看到最后不论是if还是else都运行了dorunmain方法
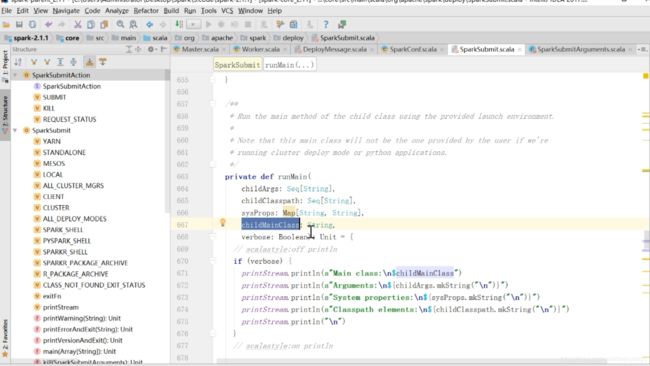
这里传入了一些参数

可以看到这里是java的反射方法,也就是执行了main方法
这个main方法在哪里?

clientpoint在哪里创建的呢?就在这个方法里面

在这个方法中还是new sparkConf这些东西,看到倒数第二行,new ClientEndpoint
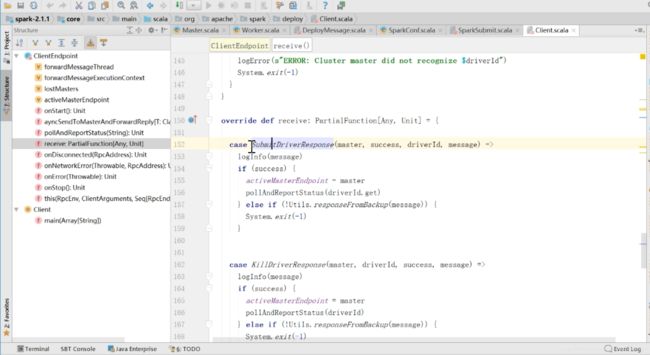
同样,在这个ClientEndpoint里面要关注的方法有 onStart receive
onstart方法中
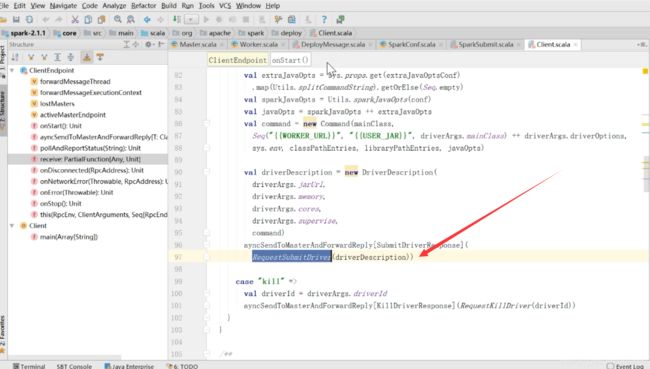
对应于上面的流程图中的箭头所指的地方
然后去master里面找

如上,如果state!=ALIVE,则reply false,懂大概意思吧
相反,则createDriver,创建driver,create完了之后就保存下来
最后有reply方法

对应于图中的箭头所指
再回到client方法中,如果submitDriverResponse是ok的

注意这里的pollAndReportStatus方法

在这个里面发送了一个RequestDriverStatus请求
对应于图中箭头所指
发送过来之后要等待你的回复

如果statusResponse没有任何的东西,就退出
RequestDriverStatus做了哪些东西呢?同样在mster里面找
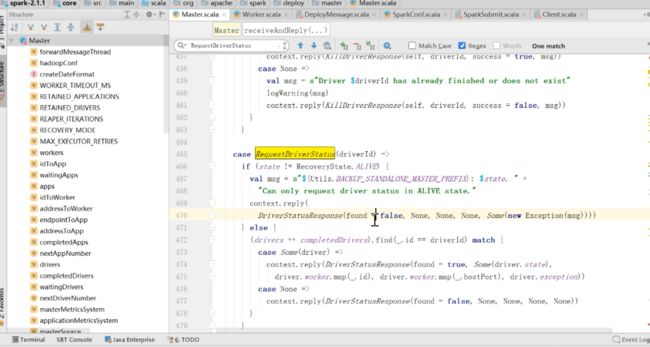
类似于上面,如果当前的状态不是ALIVE,就false
反之,就reply DriverStatusRsponse
6.3Client启动流程
Client的启动流程如下:

1)SparkConf:加载key以spark.开头的系统属性(Utils.getSystemProperties)
2)ClientArguments:
a)解析Client启动的参数
i.–cores -c --memory -m --supervise -s --verbose -v
ii.launch jarUrl master mainClass
iii.kill master driverId
b)将–properties-file(没有配置默认为conf/spark-defaults.conf)中spark.开头的配置存入SparkConf
c)在没有配置情况下,cores默认为1核
d)在没有配置情况下,memory默认为1G
e)NettyRpcEnv中的内部处理遵循RpcEndpoint统一处理,这里不再赘述
3)最终守护进程会一直存在等待结束信awaitTermination
6.4Client的OnStart监听事件
Client的启动完成后异步执行工作如下:

1)如果是发布任务(case launch),Client创建一个DriverDescription,并向Master发起RequestSubmitDriver请求

a)Command中的mainClass为: org.apache.spark.deploy.worker.DriverWrapper
b)Command中的arguments为: Seq("{{WORKER_URL}}", “{{USER_JAR}}”, driverArgs.mainClass)
2)Master接受RequestSubmitDriver请求后,将DriverDescription封装为一个DriverInfo,

a)startTime与submitDate都为当前时间
b)driverId格式为:driver-yyyyMMddHHmmss-nextId,nextId是全局唯一的
3)Master持久化DriverInfo,并加入待调度列表中(waitingDrivers),触发公共资源调度逻辑。
4)Master公共资源调度结束后,返回SubmitDriverResponse给Client
6.5RpcMessage处理(receiveAndReply)
| 消息实例 | 发起方 | 接收方 | 说明 |
|---|---|---|---|
6.6OneWayMessage处理(receive)
| 消息实例 | 发起方 | 接收方 | 说明 |
|---|---|---|---|
| SubmitDriverResponse | Master | Client | |
| KillDriverResponse | Client |
第7章Driver和DriverRunner
Client向Master发起RequestSubmitDriver请求,Master将DriverInfo添加待调度列表中(waitingDrivers),下面针对于Driver进一步梳理

除了上面的异常情况外,正常情况下,是createDriver
createDriver里面new了一个DriverInfo
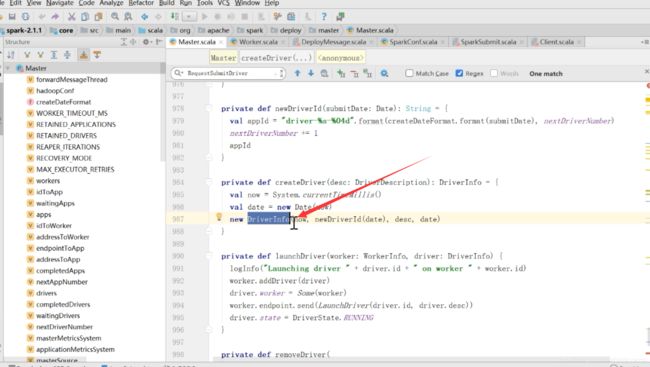
driver整个的信息封装在这个类里面
可以看到核心的方法是在schedule()

读一下上面的英文,意思是如果有需要部署的app的时候,这个方法是用于分配资源的,每次如果有新的app加入进来,或者当前的可用资源变更了,这个时候都要去调用一下schedule,他是一个公共方法,接下来看一下做了哪些事
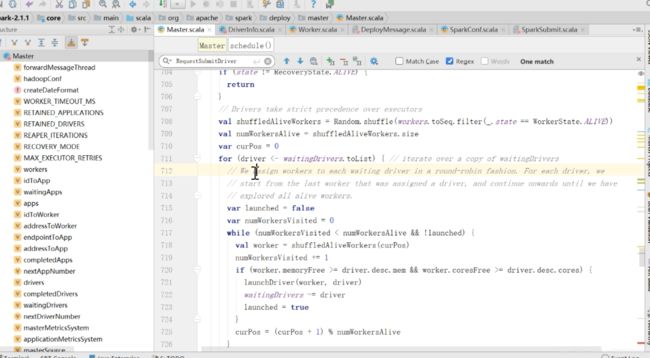
还是之前的,如果状态不对就return
woker如果满足driver的运行系统,就在woker里面去launch driver如果launch为true的时候,就直接跳出循环了,所以一旦检测到第一个driver就跳出来了。
在launchDriver里面有worker信息和driver信息
把driver添加到worker里面,然后看到worker的endpoint send了一个东西,launchDriver,对应于图中的箭头
当worker收到这个driver之后new了一个DriverRunner,然后Driverrunner 执行 start方法,然后这个worker更新了他的内存和cores
所以可以看到,方法集中到了driverRunner上
简单读一下英文的注释:包装了driver,失败之后自动重driver,如果是standlone用的是这个,如果是yarn就用其他的
在这个里面有一个start方法,里面new了一个线程,里面添加了addShutDowdHook的方法(退出jvm的钩子)
核心方法是prepareAndRunDriver
createWorkingDirectory创建了working目录
downLoadUserJar从远程把jar包从client里面download下来了
runDriver
通过processBuilderLike 和 initialize 进行runDriver
把命令封装到了command里面
通过command.start执行了一下,然后返回了这个进程
如果一直走到最后也没有抛出异常,worker会send一个东西 DriverStateChanged
之后如果worker接收到了driverStateChanged
如上,如果给的状态没有问题,会有一个sendToMaster方法,也就是把这个driverStateChanged返回给了master
如果没有错到这里就完了,如果有错,则执行相应的操作,这个时候driver启动就执行完了
7.1Master对Driver资源分配
大致流程如下:

waitingDrivers与aliveWorkers进行资源匹配,
1)在waitingDrivers循环内,轮询所有aliveWorker
2)如果aliveWorker满足当前waitingDriver资源要求,给Worker发送LaunchDriver指令并将 waitingDriver移除waitingDrivers,则进行下一次waitingDriver的轮询工作
3)如果轮询完所有aliveWorker都不满足waitingDriver资源要求,则进行下一次waitingDriver的轮询工作
4)所有发起的轮询开始点都上次轮询结束点的下一个点位开始
7.2Worker运行DriverRunner
Driver的启动,流程如下:
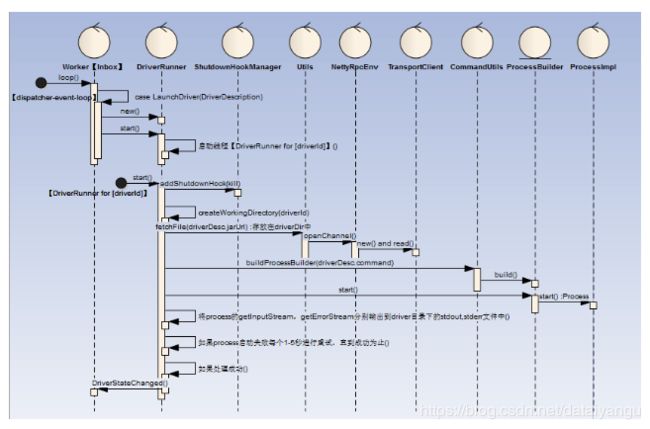
1)当Worker遇到LaunchDriver指令时,创建并启动一个DriverRunner
2)DriverRunner启动一个线程【DriverRunner for [driverId]】处理Driver启动工作
3)【DriverRunner for [driverId]】:
a)添加JVM钩子,针对于每个diriverId创建一个临时目录
b)将DriverDesc.jarUrl通过Netty从Driver机器远程拷贝过来
c)根据DriverDesc.command模板构建本地执行的command命令,并启动该command对应的Process进程
d)将Process的输出流输出到文件stdout/stderror,如果Process启动失败,进行1-5的秒的反复启动工作,直到启动成功,在释放Worker节点的DriverRunner的资源
7.3DriverRunner创建并运行DriverWrapper
DriverWrapper的运行,流程如下:
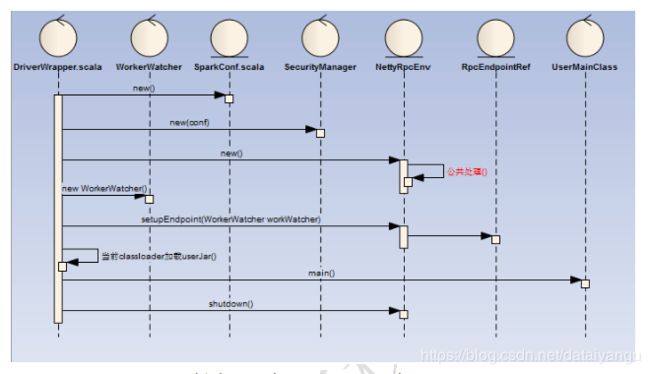
1)DriverWapper创建了一个RpcEndpoint与RpcEnv
2)RpcEndpoint为WorkerWatcher,主要目的为监控Worker节点是否正常,如果出现异常就直接退出
3)然后当前的ClassLoader加载userJar,同时执行userMainClass
4)执行用户的main方法后关闭workerWatcher
第8章SparkContext解析
8.1SparkContext解析
SparkContext是用户通往Spark集群的唯一入口,任何需要使用Spark的地方都需要先创建SparkContext,那么SparkContext做了什么?
首先SparkContext是在Driver程序里面启动的,可以看做Driver程序和Spark集群的一个连接,SparkContext在初始化的时候,创建了很多对象:

上图列出了SparkContext在初始化创建的时候的一些主要组件的构建。
上面sparkContext new了很多重要的东西,比如sparkenv就是spark的一些环境,sparkscheduler执行具体的任务,sparkBackerd具体去操作executor这些东西,DAGScheduler代码里面的RDD转化成task,然后转化的过程中呢,可能先转化成stage,然后转化成 task list,task list里面包含的是task。
然后入口是sparkContext


如果没有设置spark.master就报错,如果没有设置spark.app.name就报错

如果master是yarn并且deploymode是client的时候,就添加上面代码中的环境变量
JobProgressListener监听整个任务执行的progress
CreateSparkEnv 创建spark的env,这个之前看过主要是sparkEnv.createDriverEnv
中间是一些初始化
有一个比较重要的方法createTaskScheduler

从上面的图中能够看到右边的图中,第一个创建了sparkEnv,第二个创建了TaskScheduler
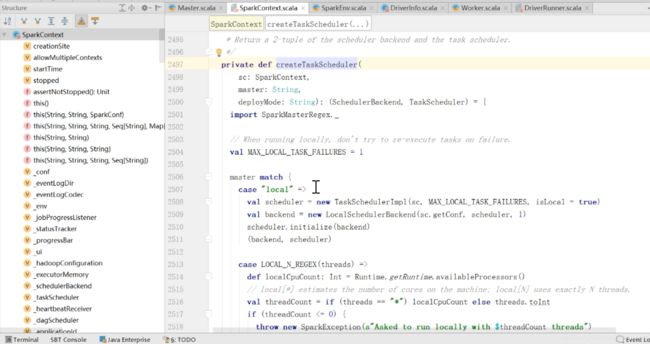
点进去这个createTaskScheduler
通过master match一下,如果是local模式的,就新建一个localschdulerBackend
如果是LOCAL_N_REGEX这种模式的,就是localSchedulerBacked
如果是SPARK_REGEX这种模式,还是TaskSchedulerImpl,第二个变成了StandaloneSchedulerBackend
下面还有很多模式 最后返回的是StandaloneSchedulerBackend

图中箭头所指,standaloneAppClient是这个中的主要东西,主要负责driver和master之间的通信
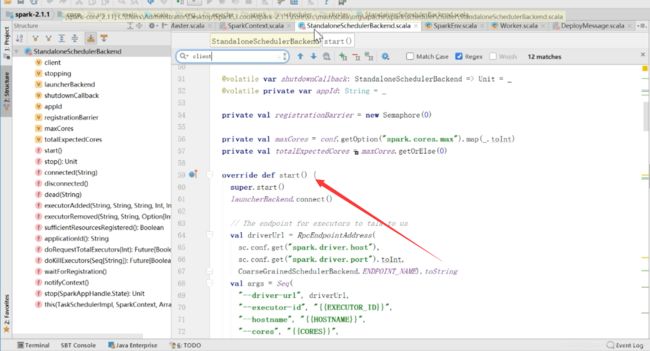
它的start方法

在这里new了一个standaloneAppClient
在这个里面有一个嵌套类叫ClientEndpoint
它继承了ThreadSafeRpcEndpoint

这里面也有一个onstart方法,然后里面有个registerWithMaster,然后也有receive、receiveAndReply
对应于上面图中的第七个注册应用这个东西
然后去master里面看
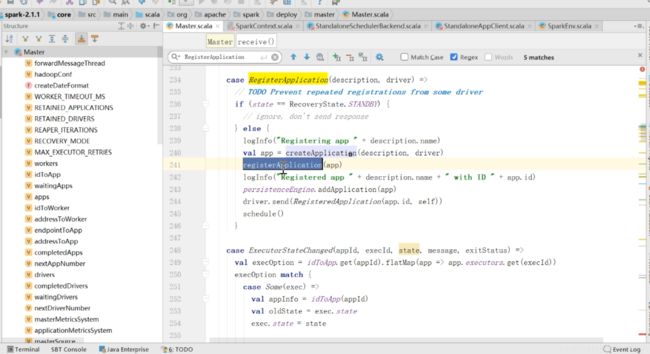
获取到registerApp之后,如果当前的master状态不对,则什么也不做,如果是active的,即多节点的master,之后createApplication、registerApplication,然后driver.send,然后schedule,对应于图中
这个schedule就是启动分配Executor

然后看一下createApplication

这个ApplicationInfo就是记录了一些状态
registerApplication

把application的信息进行了记录
然后这个方法进行完了,就完成了application的注册,然后driver.send(RegisteredApplication)

对应于上面的箭头所以
master send之后谁去接受它呢?
就是刚才的StandaloneAppClient ClientEndpoint
RegisteredApplication

具体没做什么事,在listener里面把appId包括了一下
先通过sparksubmit 提交应用,整个应用的时候master在某个worker上面创建driver的jvm,创建的过程中会从driver client里面下载jar包,下载完jar包之后从申请的jvm里面去运行,运行的过程中new 了sparkContext,sparkEnv,new了TaskScheduler,StandaloneSchedulerBackend,到这一步,整个应用已经运行完成了,但是还没有运行rdd的条件,因为我还没有得到我的executor,即整个运行的容器,这个时候通过ClientEndpoint向master注册,这个时候master注册之后,直接schedule(),然后调用executor
再看一下这张图
那么接着看schedule这个方法
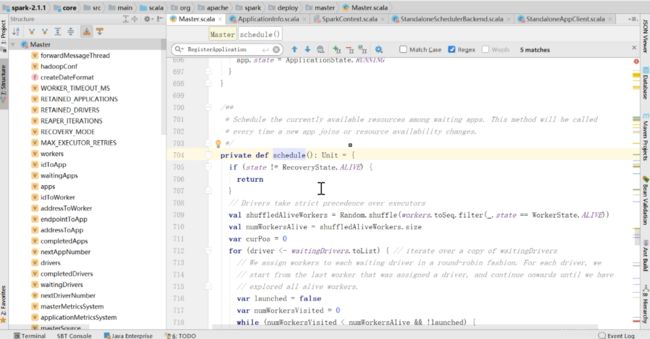

上面的driver已经launched了,所以不会走那个while循环,然后,直接走下面的startExecutorsOnWorkers
y因为上面的for循环里面其实是给driver分配资源,因为已经加载了,所以执行最后的startExecutorOnWorkers

这里面比较核心的方法是scheduleExecutorsOnWorkers
同样能够看到还有一些逻辑,这些逻辑就是为executor运行在哪些worker上,运行多少等等
然后看一下scheduleExecutorsOnWorkers这个方法

上面的流程中MasterEndpoint其实是给worker提交了一个消息,叫做executor,workerEndpoint收到这个launchExecutor之后呢就create()和start()ExecutorRunner,然后这个ExecutorRunner就负责创建了下面的Executor,创建了之后worker就返回了一个消息,叫做ExecutorStateChanged,意识就是Executor已经ok了,这个时候后master会告诉远程的driver“我给你分配额Executor已经ok了”,这是整个executor启动的进程
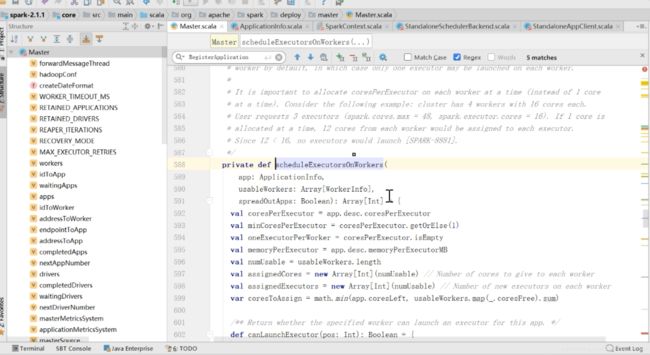

在这个方法里面定义了一些函数canLaunchExecutor,测试一下能不能启动成功,
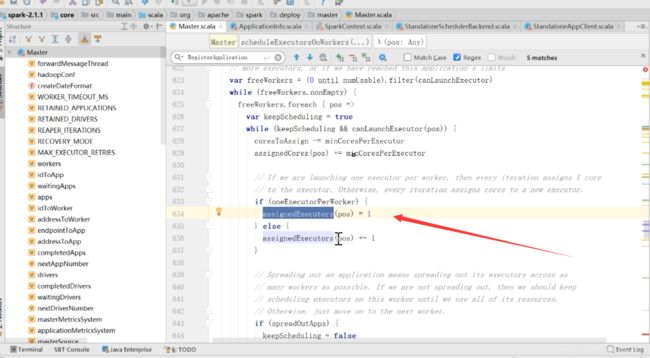
如果能运行成功,assignedExecutor,点进去,然后看
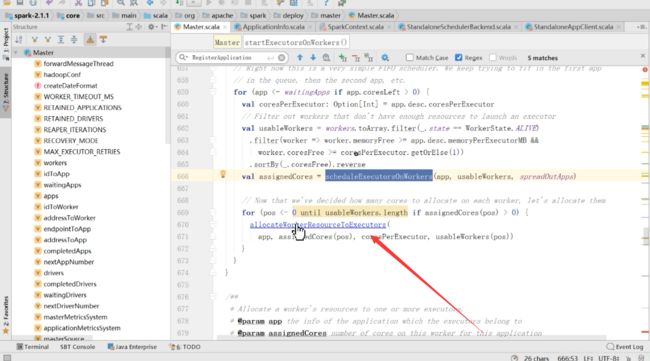

简单看一下注释,具体进行了资源分配,可以看到有一个方法叫做launchExecutor,真正的去加载Executor,是在for循环里面,说明在一个worker上可能有很多Executor
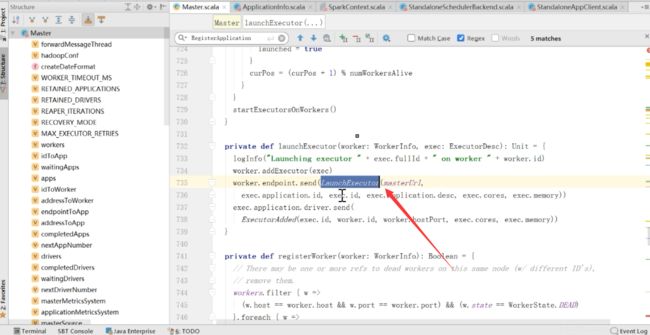
在Master里面send LaunchExecutor,worker的所有信息都在master上进行,在master上把所有的哪个worker需要启动哪个进行匹配,直接对worker进行launchexecutor,发送完了之后,
LaunchExecutor
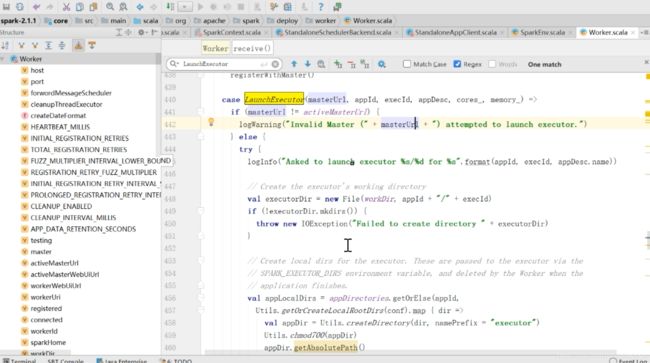
创建了一个Executor的运行路径,然后chmod700等等
再往下看
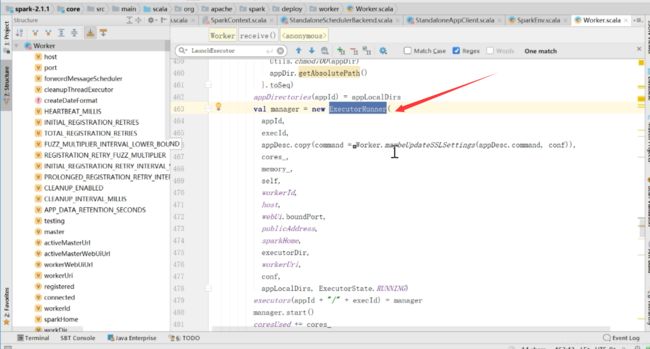
创建了ExecutorRunner
然后看到上面的代码,new ExecutorRunner返回一个manager,然后执行manager.start(),start完了之后
sendToMaster ExecutorStateChanged

即回去告诉了master,我的Executor已经运行好了,可以继续往下走了。
然后看一下start方法
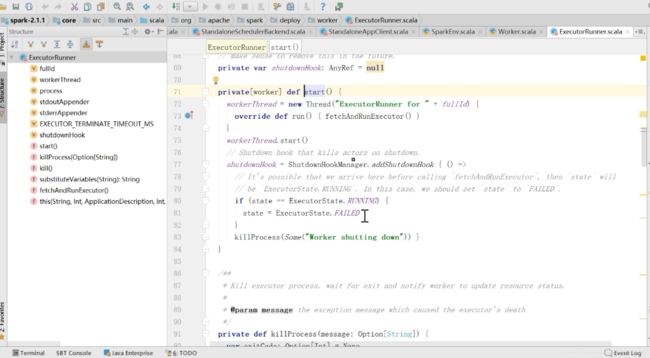
这里面是new 了一个Thread,执行的是ferchAndRunExecutor,点进去
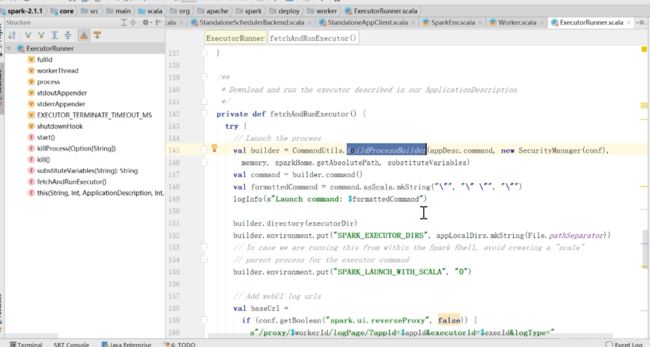
里面有buildProcessBuilder,这里面同样有buildProcessBuilder,把launchedExecutor封装了,
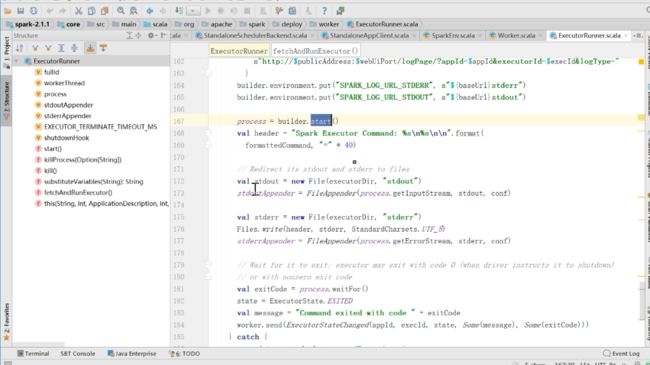
然后通过builder.start运行,运行完了之后给worker发送了一个ExecutorStateChange,在上面的流程图中没有把这步画出来
 图中少了一步,如下,就是运行完了之后,在把这个消息返回回来
图中少了一步,如下,就是运行完了之后,在把这个消息返回回来
代码中ExecutorStateChange 是什么呢?就是Executor
Executor怎么启动的?
这个参数里面的command到底是什么?不知道,怎么办有两种办法,一种是debug一下,看看实时的参数是什么
会看到这个command是如图所示,也就是说在提交程序之前把CoarseGrainedExecutorBackend封装到里面了,这个command就是图中的
那么这个CoarseGrainedExecutorBackend是什么东西呢?其实走的就是CoarseGrainedExecutorBackend的main方法
在main方法里面做了一些什么呢?首先检测了一下参数,最终进入了run方法,在run方法里面创建了一个RpcEnv
同样创建一个RpcEnv之后,CoarseGrainedExecutorBackend,如下
然后发现继承了ThreadSafeRpcEndpoint,所以executor通信的端点就是CoarseGrainedExecutorBackend
往下看,这个类有一个Field叫做executor,然后在往下看,new 了一个Executor赋值给了executor
也就是图中的箭头所指
CoarseGrainedExecutorBackend会监听外面发送给它的任务的请求,然后用Executor进行run。
Executor里面
有一个TaskRunner,里面具体的run方法在这里执行
在Worker里面ExecutorRunner就是调用了CoarseGrainedExecutorBackend的main方法,声明了endpoint和rpcEnv还有相对应的Executor,这几个组合起来就是Executor的实例
申请完了之后在worker里面有一个sendToMaster
这个时候ExecutorStateChanged,然后把这个消息直接发送给master
在master中接收到这个消息之后,就会把这个ExecutorUpdate发送给Driver,说明这个时候所有的Executor已经分配完了,如下图所示这两步
然后ClientPoint接受到这个消息
在这个方法里面,接收到了目前为止所有的都已经finash了。
这个时候就需要,启动 Task执行了
这个时候发现入口在RDD的action方法里面
比如随便找一个RDD里面的方法reduce,在reduce方法的最后,其实调用了 sc.runJob,
那么图中下面的那些方法都是通过runjob完成的
点击进入runjob,然后在进入下一个runjob
然后在这里就发现了dagSchedules.runJob,然后继续点进去
可以看到submitJob,然后生成一个waiter,下面一段代码是等待这个job是否运行成功,然后再看submitJob
在submitJob里面有一个eventProcessLoop,就会把当前的job提交到eventProcessLoop,因为对于当前的application,如果有很多的action操作,那么每一个action操作都会当做一个job来执行
在当前的这个EventProcessLoop里面有一个timer,这个timer就是用于去轮询当前这个队列
如果遇到了当前的jobSubmit
如果遇到了JobSubmit,那么就会handleJobSubmit,然后进入这个方法,进入这个方法之后,就会真正的进入stage
会先获取到最终的stage,然后submitStage
点进去,然后发现submit这个函数里面有一个递归调用
如果stage 的parent是不存在的,就直接调它。
同样能看到submitMissingTasks,点进去
发现进行了区分,如果是shuffleMapstage后者是ResultStage去干不同的事情。
分局task类型的不同封装成不同的task,然后task数量是大于零的,taskScheduler.submitTasks,然后就会把所有的task封装成一个Taskset,然后去运行
然后找到submitTasks方法,里面有CreateTaskManager方法,管理所有的task
找到
到他的父类里面,有一个onstart方法
在父类启动的时候给自己发送了一个ReviveOffers这个消息

然后直接是makeOffers
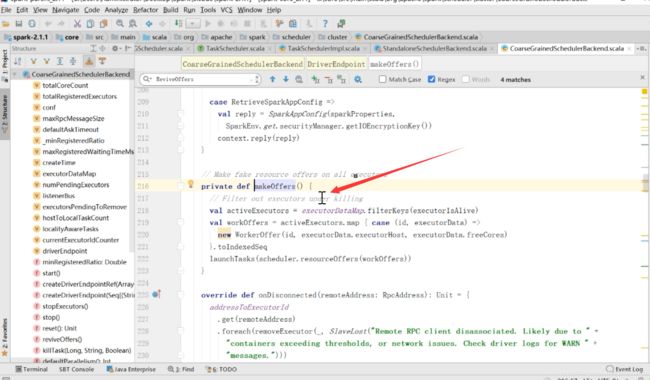
然后申请了当前任务的一些资源
申请了这些资源后,发现最后有一个方法叫做launchTask

在这个方法里面往下看

这个方法对应于图中所指的

在executor中找到这个消息
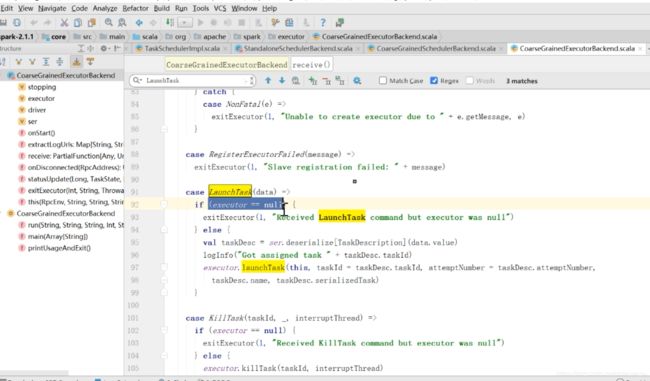
如果executor==null,则直接退出,否则用launchTask这个方法 ,对应于图中

在launchTask里面有一个threadPool.execute
到目前为止driver根据配置信息和消息信息,把他的code转化成了相应的rdd,然后rdd转换成了各个stage,然后每个stage转换成了taskset,然后taskset通过Driverendpoint处理消息给具体的executor发送了LaunchTask,然后在消息里面去写当前task需要处理的数据
处理完了之后会发送一个taskfinashed

在executor的run方法里面有一个execBackend.statusUpdate
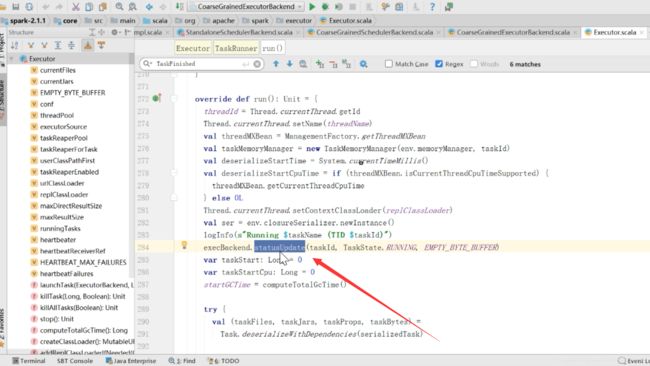

如果executor执行完了之后,直接调用了statusUpdate方法,而不是通过发消息的方式,然民下面调用了driverRed.send(msg),向driver发送了数据
也就是图中的绿色的线条1号,taskfinash不是通过消息发送的,而是通过直接调用的,调用statusupdate。
调用完了之后,通过消息转发,转发给了driver

在driverEndpoint里面获得消息之后,更新了整个scheduler的状态,如下代码
如果TaskState执行完了,

然后看一下statusupdate做了哪些事

然后上面的statusupdate往下,如果stage是没有执行完的,会继续执行reviveOffers,再去执行stage的应用
8.2SparkContext创建过程
创建过程如下:

SparkContext在新建时
1)内部创建一个SparkEnv,SparkEnv内部创建一个RpcEnv
a)RpcEnv内部创建并注册一个MapOutputTrackerMasterEndpoint(该Endpoint暂不介绍)
2)接着创建DAGScheduler,TaskSchedulerImpl,SchedulerBackend
a)TaskSchedulerImpl创建时创建SchedulableBuilder,SchedulableBuilder根据类型分为FIFOSchedulableBuilder,FairSchedulableBuilder两类
3)最后启动TaskSchedulerImpl,TaskSchedulerImpl启动SchedulerBackend
a)SchedulerBackend启动时创建ApplicationDescription,DriverEndpoint, StandloneAppClient
b)StandloneAppClient内部包括一个ClientEndpoint
8.3SparkContext简易结构与交互关系
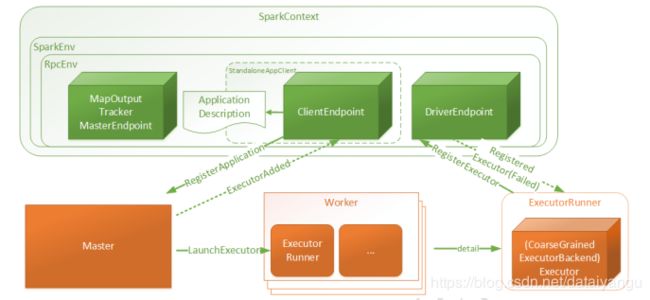
1)SparkContext:是用户Spark执行任务的上下文,用户程序内部使用Spark提供的Api直接或间接创建一个SparkContext
2)SparkEnv:用户执行的环境信息,包括通信相关的端点
3)RpcEnv:SparkContext中远程通信环境
4)ApplicationDescription:应用程序描述信息,主要包含appName, maxCores, memoryPerExecutorMB, coresPerExecutor, Command(
CoarseGrainedExecutorBackend), appUiUrl等
5)ClientEndpoint:客户端端点,启动后向Master发起注册RegisterApplication请求
6)Master:接受RegisterApplication请求后,进行Worker资源分配,并向分配的资源发起LaunchExecutor指令
7)Worker:接受LaunchExecutor指令后,运行ExecutorRunner
8)ExecutorRunner:运行applicationDescription的Command命令,最终Executor,同时向DriverEndpoint注册Executor信息
8.4Master对Application资源分配
当Master接受Driver的RegisterApplication请求后,放入waitingDrivers队列中,在同一调度中进行资源分配,分配过程如下:

waitingApps与aliveWorkers进行资源匹配
1)如果waitingApp配置了app.desc.coresPerExecutor:
a)轮询所有有效可分配的worker,每次分配一个executor,executor的核数为minCoresPerExecutor(app.desc.coresPerExecutor),直到不存在有效可分配资源或者app依赖的资源已全部被分配
2)如果waitingApp没有配置app.desc.coresPerExecutor:
a)轮询所有有效可分配的worker,每个worker分配一个executor,executor的核数为从minCoresPerExecutor(为固定值1)开始递增,直到不存在有效可分配资源或者app依赖的资源已全部被分配
3)其中有效可分配worker定义为满足一次资源分配的worker:
a)cores满足:usableWorkers(pos).coresFree - assignedCores(pos) >= minCoresPerExecutor,
b)memory满足(如果是新的Executor):usableWorkers(pos).memoryFree - assignedExecutors(pos) * memoryPerExecutor >= memoryPerExecutor
注意:Master针对于applicationInfo进行资源分配时,只有存在有效可用的资源就直接分配,而分配剩余的app.coresLeft则等下一次再进行分配
8.5Worker创建Executor

(图解:橙色组件是Endpoint组件)
Worker启动Executor
1)在Worker的tempDir下面创建application以及executor的目录,并chmod700操作权限
2)创建并启动ExecutorRunner进行Executor的创建
3)向master发送Executor的状态情况
ExecutorRnner
1)新线程【ExecutorRunner for [executorId]】读取ApplicationDescription将其中Command转化为本地的Command命令
2)调用Command并将日志输出至executor目录下的stdout,stderr日志文件中,Command对应的java类为CoarseGrainedExecutorBackend
CoarseGrainedExecutorBackend
1)创建一个SparkEnv,创建ExecutorEndpoint(CoarseGrainedExecutorBackend),以及WorkerWatcher
2)ExecutorEndpoint创建并启动后,向DriverEndpoint发送RegisterExecutor请求并等待返回
3)DriverEndpoint处理RegisterExecutor请求,返回ExecutorEndpointRegister的结果
4)如果注册成功,ExecutorEndpoint内部再创建Executor的处理对象
至此,Spark运行任务的容器框架就搭建完成。
第9章Job提交和Task的拆分
在前面的章节Client的加载中,Spark的DriverRunner已开始执行用户任务类(比如:org.apache.spark.examples.SparkPi),下面我们开始针对于用户任务类(或者任务代码)进行分析
9.1整体预览

1)Code:指的用户编写的代码
2)RDD:弹性分布式数据集,用户编码根据SparkContext与RDD的api能够很好的将Code转化为RDD数据结构(下文将做转化细节介绍)
3)DAGScheduler:有向无环图调度器,将RDD封装为JobSubmitted对象存入EventLoop(实现类DAGSchedulerEventProcessLoop)队列中
4)EventLoop: 定时扫描未处理JobSubmitted对象,将JobSubmitted对象提交给DAGScheduler
5)DAGScheduler:针对于JobSubmitted进行处理,最终将RDD转化为执行TaskSet,并将TaskSet提交至TaskScheduler
6)TaskScheduler: 根据TaskSet创建TaskSetManager对象存入SchedulableBuilder的数据池(Pool)中,并调用DriverEndpoint唤起消费(ReviveOffers)操作
7)DriverEndpoint:接受ReviveOffers指令后将TaskSet中的Tasks根据相关规则均匀分配给Executor
8)Executor:启动一个TaskRunner执行一个Task
9.2Code转化为初始RDDs
我们的用户代码通过调用Spark的Api(比如:SparkSession.builder.appName(“Spark Pi”).getOrCreate()),该Api会创建Spark的上下文(SparkContext),当我们调用transform类方法 (如:parallelize(),map())都会创建(或者装饰已有的) Spark数据结构(RDD), 如果是action类操作(如:reduce()),那么将最后封装的RDD作为一次Job提交,存入待调度队列中(DAGSchedulerEventProcessLoop )待后续异步处理。
如果多次调用action类操作,那么封装的多个RDD作为多个Job提交。
流程如下:

ExecuteEnv(执行环境 )
1)这里可以是通过spark-submit提交的MainClass,也可以是spark-shell脚本
2)MainClass : 代码中必定会创建或者获取一个SparkContext
3)spark-shell:默认会创建一个SparkContext
RDD(弹性分布式数据集)
1)create:可以直接创建(如:sc.parallelize(1 until n, slices) ),也可以在其他地方读取(如:sc.textFile(“README.md”))等
2)transformation:rdd提供了一组api可以进行对已有RDD进行反复封装成为新的RDD,这里采用的是装饰者设计模式,下面为部分装饰器类图

3)action:当调用RDD的action类操作方法时(collect、reduce、lookup、save ),这触发DAGScheduler的Job提交
4)DAGScheduler:创建一个名为JobSubmitted的消息至DAGSchedulerEventProcessLoop阻塞消息队列(LinkedBlockingDeque)中
5)DAGSchedulerEventProcessLoop:启动名为【dag-scheduler-event-loop】的线程实时消费消息队列
6)【dag-scheduler-event-loop】处理完成后回调JobWaiter
7)DAGScheduler:打印Job执行结果
8)JobSubmitted:相关代码如下(其中jobId为DAGScheduler全局递增Id):
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
- 1
- 2
- 3
最终示例:
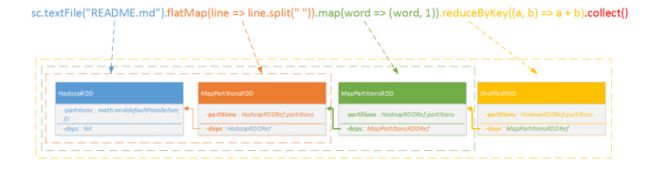
最终转化的RDD分为四层,每层都依赖于上层RDD,将ShffleRDD封装为一个Job存入DAGSchedulerEventProcessLoop待处理,如果我们的代码中存在几段上面示例代码,那么就会创建对应对的几个ShffleRDD分别存入DAGSchedulerEventProcessLoop
9.3RDD分解为待执行任务集合(TaskSet)
Job提交后,DAGScheduler根据RDD层次关系解析为对应的Stages,同时维护Job与Stage的关系。
将最上层的Stage根据并发关系(findMissingPartitions )分解为多个Task,将这个多个Task封装为TaskSet提交给TaskScheduler。非最上层的Stage的存入处理的列表中(waitingStages += stage)
流程如下:

1)DAGSchedulerEventProcessLoop中,线程【dag-scheduler-event-loop】处理到JobSubmitted
2)调用DAGScheduler进行handleJobSubmitted
a)首先根据RDD依赖关系依次创建Stage族,Stage分为ShuffleMapStage,ResultStage两类
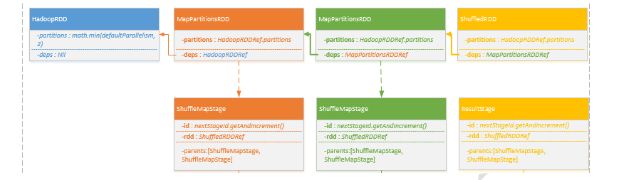
b)更新jobId与StageId关系Map
c)创建ActiveJob,调用LiveListenerBug,发送SparkListenerJobStart指令
d)找到最上层Stage进行提交,下层Stage存入waitingStage中待后续处理
i.调用OutputCommitCoordinator进行stageStart()处理
ii.调用LiveListenerBug, 发送 SparkListenerStageSubmitted指令
iii.调用SparkContext的broadcast方法获取Broadcast对象
根据Stage类型创建对应多个Task,一个Stage根据findMissingPartitions分为多个对应的Task,Task分为ShuffleMapTask,ResultTask

iv.将Task封装为TaskSet,调用TaskScheduler.submitTasks(taskSet)进行Task调度,关键代码如下:
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
- 1
- 2
9.4TaskSet封装为TaskSetManager并提交至Driver
TaskScheduler将TaskSet封装为TaskSetManager(new TaskSetManager(this, taskSet, maxTaskFailures, blacklistTrackerOpt)),存入待处理任务池(Pool)中,发送DriverEndpoint唤起消费(ReviveOffers)指令

1)DAGSheduler将TaskSet提交给TaskScheduler的实现类,这里是TaskChedulerImpl
2)TaskSchedulerImpl创建一个TaskSetManager管理TaskSet,关键代码如下:
new TaskSetManager(this, taskSet, maxTaskFailures, blacklistTrackerOpt)
- 1
3)同时将TaskSetManager添加SchedduableBuilder的任务池Poll中
4)调用SchedulerBackend的实现类进行reviveOffers,这里是standlone模式的实现类StandaloneSchedulerBackend
5)SchedulerBackend发送ReviveOffers指令至DriverEndpoint
9.5Driver将TaskSetManager分解为TaskDescriptions并发布任务到Executor
Driver接受唤起消费指令后,将所有待处理的TaskSetManager与Driver中注册的Executor资源进行匹配,最终一个TaskSetManager得到多个TaskDescription对象,按照TaskDescription想对应的Executor发送LaunchTask指令
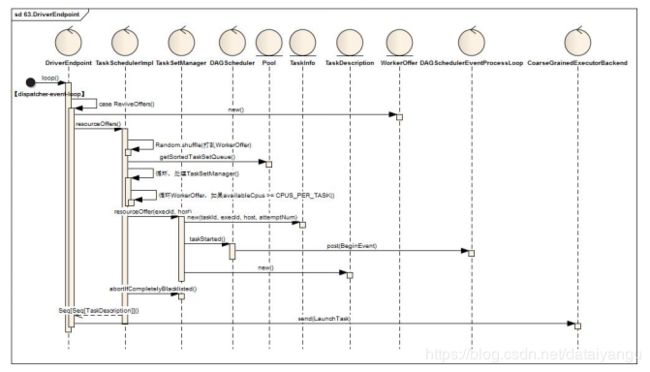
当Driver获取到ReviveOffers(请求消费)指令时
1)首先根据executorDataMap缓存信息得到可用的Executor资源信息(WorkerOffer),关键代码如下
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
- 1
- 2
- 3
- 4
2)接着调用TaskScheduler进行资源匹配,方法定义如下:
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {..}
- 1
a)将WorkerOffer资源打乱(val shuffledOffers = Random.shuffle(offers))
b)将Poo中待处理的TaskSetManager取出(val sortedTaskSets = rootPool.getSortedTaskSetQueue),
c)并循环处理sortedTaskSets并与shuffledOffers循环匹配,如果shuffledOffers(i)有足够的Cpu资源( if (availableCpus(i) >= CPUS_PER_TASK) ),调用TaskSetManager创建TaskDescription对象(taskSet.resourceOffer(execId, host, maxLocality)),最终创建了多个TaskDescription,TaskDescription定义如下:
new TaskDescription(
taskId,
attemptNum,
execId,
taskName,
index,
sched.sc.addedFiles,
sched.sc.addedJars,
task.localProperties,
serializedTask)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3)如果TaskDescriptions不为空,循环TaskDescriptions,序列化TaskDescription对象,并向ExecutorEndpoint发送LaunchTask指令,关键代码如下:
for (task <- taskDescriptions.flatten) {
val serializedTask = TaskDescription.encode(task)
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
- 1
- 2
- 3
- 4
- 5
- 6
第10章Task执行和回执
DriverEndpoint最终生成多个可执行的TaskDescription对象,并向各个ExecutorEndpoint发送LaunchTask指令,本节内容将关注ExecutorEndpoint如何处理LaunchTask指令,处理完成后如何回馈给DriverEndpoint,以及整个job最终如何多次调度直至结束。
10.1Task的执行流程
Executor接受LaunchTask指令后,开启一个新线程TaskRunner解析RDD,并调用RDD的compute方法,归并函数得到最终任务执行结果

1)ExecutorEndpoint接受到LaunchTask指令后,解码出TaskDescription,调用Executor的launchTask方法
2)Executor创建一个TaskRunner线程,并启动线程,同时将改线程添加到Executor的成员对象中,代码如下:
private val runningTasks = new ConcurrentHashMap[Long, TaskRunner]
runningTasks.put(taskDescription.taskId, taskRunner)
- 1
- 2
TaskRunner
1)首先向DriverEndpoint发送任务最新状态为RUNNING
2)从TaskDescription解析出Task,并调用Task的run方法
Task
1)创建TaskContext以及CallerContext(与HDFS交互的上下文对象)
2)执行Task的runTask方法
a)如果Task实例为ShuffleMapTask:解析出RDD以及ShuffleDependency信息,调用RDD的compute()方法将结果写Writer中(Writer这里不介绍,可以作为黑盒理解,比如写入一个文件中),返回MapStatus对象
b)如果Task实例为ResultTask:解析出RDD以及合并函数信息,调用函数将调用后的结果返回
TaskRunner将Task执行的结果序列化,再次向DriverEndpoint发送任务最新状态为FINISHED
10.2Task的回馈流程
TaskRunner执行结束后,都将执行状态发送至DriverEndpoint,DriverEndpoint最终反馈指令CompletionEvent至DAGSchedulerEventProcessLoop中
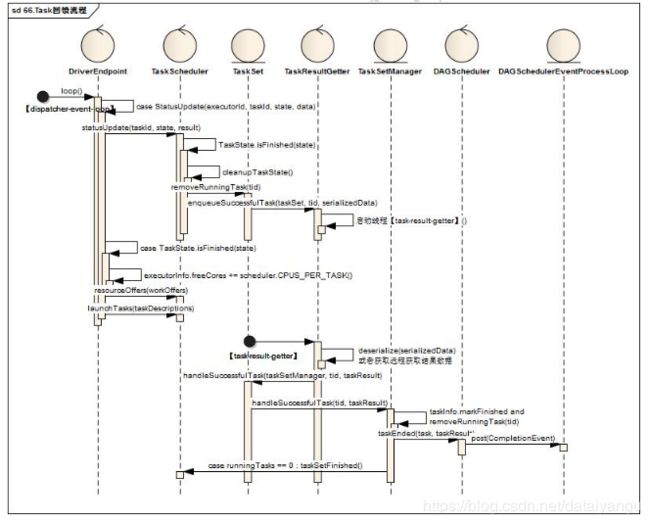
1)DriverEndpoint接受到StatusUpdate消息后,调用TaskScheduler的statusUpdate(taskId, state, result)方法
2)TaskScheduler如果任务结果是完成,那么清除该任务处理中的状态,并调动TaskResultGetter相关方法,关键代码如下:
val taskSet = taskIdToTaskSetManager.get(tid)
taskIdToTaskSetManager.remove(tid)
taskIdToExecutorId.remove(tid).foreach { executorId =>
executorIdToRunningTaskIds.get(executorId).foreach { _.remove(tid) }
}
taskSet.removeRunningTask(tid)
if (state == TaskState.FINISHED) {
taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData)
} else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) {
taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
TaskResultGetter启动线程启动线程【task-result-getter】进行相关处理
1)通过解析或者远程获取得到Task的TaskResult对象
2)调用TaskSet的handleSuccessfulTask方法,TaskSet的handleSuccessfulTask方法直接调用TaskSetManager的handleSuccessfulTask方法
TaskSetManager
1)更新内部TaskInfo对象状态,并将该Task从运行中Task的集合删除,代码如下:
val info = taskInfos(tid)
info.markFinished(TaskState.FINISHED, clock.getTimeMillis())
removeRunningTask(tid)
- 1
- 2
- 3
2)调用DAGScheduler的taskEnded方法,关键代码如下:
sched.dagScheduler.taskEnded(tasks(index), Success, result.value(), result.accumUpdates, info)
DAGScheduler向DAGSchedulerEventProcessLoop存入CompletionEvent指令,CompletionEvent对象定义如下:
private[scheduler] case class CompletionEvent(
task: Task[_],
reason: TaskEndReason,
result: Any,
accumUpdates: Seq[AccumulatorV2[_, _]],
taskInfo: TaskInfo) extends DAGSchedulerEvent
- 1
- 2
- 3
- 4
- 5
- 6
10.3Task的迭代流程
DAGSchedulerEventProcessLoop中针对于CompletionEvent指令,调用DAGScheduler进行处理,DAGScheduler更新Stage与该Task的关系状态,如果Stage下Task都返回,则做下一层Stage的任务拆解与运算工作,直至Job被执行完毕:

1)DAGSchedulerEventProcessLoop接收到CompletionEvent指令后,调用DAGScheduler的handleTaskCompletion方法
2)DAGScheduler根据Task的类型分别处理
3)如果Task为ShuffleMapTask
a)待回馈的Partitions减取当前partitionId
b)如果所有task都返回,则markStageAsFinished(shuffleStage),同时向MapOutputTrackerMaster注册MapOutputs信息,且markMapStageJobAsFinished
c)调用submitWaitingChildStages(shuffleStage)进行下层Stages的处理,从而迭代处理最终处理到ResultTask,job结束,关键代码如下:
private def submitWaitingChildStages(parent: Stage) {
...
val childStages = waitingStages.filter(_.parents.contains(parent)).toArray
waitingStages --= childStages
for (stage <- childStages.sortBy(_.firstJobId)) {
submitStage(stage)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4)如果Task为ResultTask
a)改job的partitions都已返回,则markStageAsFinished(resultStage),并cleanupStateForJobAndIndependentStages(job),关键代码如下
for (stage <- stageIdToStage.get(stageId)) {
if (runningStages.contains(stage)) {
logDebug("Removing running stage %d".format(stageId))
runningStages -= stage
}
for ((k, v) <- shuffleIdToMapStage.find(_._2 == stage)) {
shuffleIdToMapStage.remove(k)
}
if (waitingStages.contains(stage)) {
logDebug("Removing stage %d from waiting set.".format(stageId))
waitingStages -= stage
}
if (failedStages.contains(stage)) {
logDebug("Removing stage %d from failed set.".format(stageId))
failedStages -= stage
}
}
// data structures based on StageId
stageIdToStage -= stageId
jobIdToStageIds -= job.jobId
jobIdToActiveJob -= job.jobId
activeJobs -= job
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
至此,用户编写的代码最终调用Spark分布式计算完毕。
第11章Spark的数据存储
Spark计算速度远胜于Hadoop的原因之一就在于中间结果是缓存在内存而不是直接写入到disk,本文尝试分析Spark中存储子系统的构成,并以数据写入和数据读取为例,讲述清楚存储子系统中各部件的交互关系。
11.1存储子系统概览
Storage模块主要分为两层:
1)通信层:storage模块采用的是master-slave结构来实现通信层,master和slave之间传输控制信息、状态信息,这些都是通过通信层来实现的。
2)存储层:storage模块需要把数据存储到disk或是memory上面,有可能还需replicate到远端,这都是由存储层来实现和提供相应接口。
而其他模块若要和storage模块进行交互,storage模块提供了统一的操作类BlockManager,外部类与storage模块打交道都需要通过调用BlockManager相应接口来实现。

上图是Spark存储子系统中几个主要模块的关系示意图,现简要说明如下
1)CacheManager RDD在进行计算的时候,通过CacheManager来获取数据,并通过CacheManager来存储计算结果
2)BlockManager CacheManager在进行数据读取和存取的时候主要是依赖BlockManager接口来操作,BlockManager决定数据是从内存(MemoryStore)还是从磁盘(DiskStore)中获取
3)MemoryStore 负责将数据保存在内存或从内存读取
4)DiskStore 负责将数据写入磁盘或从磁盘读入
5)BlockManagerWorker 数据写入本地的MemoryStore或DiskStore是一个同步操作,为了容错还需要将数据复制到别的计算结点,以防止数据丢失的时候还能够恢复,数据复制的操作是异步完成,由BlockManagerWorker来处理这一部分事情
6)ConnectionManager 负责与其它计算结点建立连接,并负责数据的发送和接收
7)BlockManagerMaster 注意该模块只运行在Driver Application所在的Executor,功能是负责记录下所有BlockIds存储在哪个SlaveWorker上,比如RDD Task运行在机器A,所需要的BlockId为3,但在机器A上没有BlockId为3的数值,这个时候Slave worker需要通过BlockManager向BlockManagerMaster询问数据存储的位置,然后再通过ConnectionManager去获取。
11.2启动过程分析
上述的各个模块由SparkEnv来创建,创建过程在SparkEnv.create中完成
val blockManagerMaster = new BlockManagerMaster(registerOrLookup(
"BlockManagerMaster",
new BlockManagerMasterActor(isLocal, conf)), conf)
val blockManager = new BlockManager(executorId, actorSystem, blockManagerMaster, serializer, conf)
val connectionManager = blockManager.connectionManager
val broadcastManager = new BroadcastManager(isDriver, conf)
val cacheManager = new CacheManager(blockManager)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这段代码容易让人疑惑,看起来像是在所有的cluster node上都创建了BlockManagerMasterActor,其实不然,仔细看registerOrLookup函数的实现。如果当前节点是driver则创建这个actor,否则建立到driver的连接。
def registerOrLookup(name: String, newActor: => Actor): ActorRef = {
if (isDriver) {
logInfo("Registering " + name)
actorSystem.actorOf(Props(newActor), name = name)
} else {
val driverHost: String = conf.get("spark.driver.host", "localhost")
val driverPort: Int = conf.getInt("spark.driver.port", 7077)
Utils.checkHost(driverHost, "Expected hostname")
val url = s"akka.tcp://spark@$driverHost:$driverPort/user/$name"
val timeout = AkkaUtils.lookupTimeout(conf)
logInfo(s"Connecting to $name: $url")
Await.result(actorSystem.actorSelection(url).resolveOne(timeout), timeout)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
初始化过程中一个主要的动作就是BlockManager需要向BlockManagerMaster发起注册
11.3通信层

BlockManager包装了BlockManagerMaster,发送信息包装成BlockManagerInfo。Spark在Driver和Worker端都创建各自的BlockManager,并通过BlockManagerMaster进行通信,通过BlockManager对Storage模块进行操作。
BlockManager对象在SparkEnv.create函数中进行创建:
def registerOrLookupEndpoint(
name: String, endpointCreator: => RpcEndpoint):
RpcEndpointRef = {
if (isDriver) {
logInfo("Registering " + name)
rpcEnv.setupEndpoint(name, endpointCreator)
} else {
RpcUtils.makeDriverRef(name, conf, rpcEnv)
}
}
…………
val blockManagerMaster = new BlockManagerMaster(registerOrLookupEndpoint(
BlockManagerMaster.DRIVER_ENDPOINT_NAME,
new BlockManagerMasterEndpoint(rpcEnv, isLocal, conf, listenerBus)),
conf, isDriver)
// NB: blockManager is not valid until initialize() is called later.
val blockManager = new BlockManager(executorId, rpcEnv, blockManagerMaster,
serializer, conf, mapOutputTracker, shuffleManager, blockTransferService, securityManager,numUsableCores)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
并且在创建之前对当前节点是否是Driver进行了判断。如果是,则创建这个Endpoint;否则,创建Driver的连接。
在创建BlockManager之后,BlockManager会调用initialize方法初始化自己。并且初始化的时候,会调用BlockManagerMaster向Driver注册自己,同时,在注册时也启动了Slave Endpoint。另外,向本地shuffle服务器注册Executor配置,如果存在的话。
def initialize(appId: String): Unit = { ………… master.registerBlockManager(blockManagerId, maxMemory, slaveEndpoint)// Register Executors' configuration with the local shuffle service, if one should exist. if (externalShuffleServiceEnabled && !blockManagerId.isDriver) { registerWithExternalShuffleServer() }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
而BlockManagerMaster将注册请求包装成RegisterBlockManager注册到Driver。Driver的BlockManagerMasterEndpoint会调用register方法,通过对消息BlockManagerInfo检查,向Driver注册。
private def register(id: BlockManagerId, maxMemSize: Long, slaveEndpoint: RpcEndpointRef) { val time = System.currentTimeMillis() if (!blockManagerInfo.contains(id)) { blockManagerIdByExecutor.get(id.executorId) match { case Some(oldId) => // A block manager of the same executor already exists, so remove it (assumed dead) logError("Got two different block manager registrations on same executor - " + s" will replace old one $oldId with new one $id") removeExecutor(id.executorId) case None => } logInfo("Registering block manager %s with %s RAM, %s".format( id.hostPort, Utils.bytesToString(maxMemSize), id))blockManagerIdByExecutor(id.executorId) = id blockManagerInfo(id) = new BlockManagerInfo( id, System.currentTimeMillis(), maxMemSize, slaveEndpoint) } listenerBus.post(SparkListenerBlockManagerAdded(time, id, maxMemSize))
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
不难发现BlockManagerInfo对象被保存到Map映射中。
在通信层中BlockManagerMaster控制着消息的流向,这里采用了模式匹配,所有的消息模式都在BlockManagerMessage中。
11.4存储层

Spark Storage的最小存储单位是block,所有的操作都是以block为单位进行的。
在BlockManager被创建的时候MemoryStore和DiskStore对象就被创建出来了
val diskBlockManager = new DiskBlockManager(this, conf)
private[spark] val memoryStore = new MemoryStore(this, maxMemory)
private[spark] val diskStore = new DiskStore(this, diskBlockManager)
- 1
- 2
- 3
11.4.1Disk Store
由于当前的Spark版本对Disk Store进行了更细粒度的分工,把对文件的操作提取出来放到了DiskBlockManager中,DiskStore仅仅负责数据的存储和读取。
Disk Store会配置多个文件目录,Spark会在不同的文件目录下创建文件夹,其中文件夹的命名方式是:spark-UUID(随机UUID码)。Disk Store在存储的时候创建文件夹。并且根据“高内聚,低耦合”原则,这种服务型的工具代码就放到了Utils中(调用路径:DiskStore.putBytes—>DiskBlockManager.createLocalDirs—>Utils.createDirectory):
def createDirectory(root: String, namePrefix: String = "spark"): File = {
var attempts