Install Hadoop1.2.1 in Ubuntu12.04
Install Hadoop1.2.1 in Ubuntu12.04
- Install Hadoop121 in Ubuntu1204
-
- 配置Java环境变量
- 禁用ipv6
- 配置 SSH
- 下载解压hadoop-121
- 配置Hadoop
- Hadoop的运行
- 运行Hadoop前要删除临时文件
- 打开SSH
- 格式化HDFS文件系统
- 启动Hadoop环境
- 执行Hadoop自带例子
- 停止Hadoop守护进程
-
- 进一步阅读
- most relevant
- less relevant
root@jin-VirtualBox:~# ls /usr/java/jdk1.7.0_51/
bin jre README.html THIRDPARTYLICENSEREADME.txt
COPYRIGHT lib release
db LICENSE src.zip
include man THIRDPARTYLICENSEREADME-JAVAFX.txt配置Java环境变量
打开文件 /etc/profile ,在文件结尾处添加以下几行与上一步安装Java的目录相关的内容
JAVA_HOME=/usr/java/jdk1.7.0_51
CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH以后每次可能用到JavaVM之前,要检查Java是否可用,可以通过打印JRE版本(java -version)和JDK版本(javac -version)的命令来达到这种效果
执行
java -version如果打印出JRE版本信息,说明JRE环境变量有效,即类似下面的情况
root@jin-VirtualBox:/usr/local/hadoop# java -version
java version "1.7.0_51"
Java(TM) SE Runtime Environment (build 1.7.0_51-b13)
Java HotSpot(TM) 64-Bit Server VM (build 24.51-b03, mixed mode)执行
javac -version如果打印出JDK的版本信息,说明JDK环境变量设置有效,即类似下面的情况
root@jin-VirtualBox:/usr/local/hadoop# javac -version
1.7.0_51其中任何一个的版本信息打印异常,就执行以下命令
source profile然后再次检查Java是否可用,如果仍不能打印出Java版本信息,可能是/etc/profile 没有设置好,或者Java没有正确安装。查找原因,再次检查,直到其可用为止。
4.禁用ipv6
打开 /etc/sysctl.conf 文件,在文件末尾添加如下内容并保存
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1重启Ubuntu系统,执行如下命令
cat$/proc/sys/net/ipv6/conf/all/disable_ipv6如果打印 1 ,说明设置成功,ipv6已被禁用。
5.配置 SSH
生成秘钥对
root@jin-VirtualBox:/usr/local/hadoop# ssh-keygen -t rsa
然后一直按键,就会按默认的选项将生成的秘钥对保存在
~/.ssh/id_rsa文件中。进入 .ssh目录,执行如下命令
root@jin-VirtualBox:~/.ssh# cp id_rsa.pub authorized_keys
然后执行如下命令
ssh localhost
如果不用输入密码,说明配置成功。
配置SSH过程的屏幕输出记录如下:
root@jin-VirtualBox:/usr/local/hadoop# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
67:cc:ea:e5:a3:60:47:7f:cd:94:04:13:7d:dd:58:40 root@jin-VirtualBox
The key's randomart image is:
+--[ RSA 2048]----+
| ++E++|
| oo +|
| .. |
| o . . |
| S = o |
| . = + |
| o o o . o |
| . + o.. |
| o... |
+-----------------+
root@jin-VirtualBox:/usr/local/hadoop# cd ~/.ssh/
root@jin-VirtualBox:~/.ssh# ls
id_rsa id_rsa.pub known_hosts
root@jin-VirtualBox:~/.ssh# cp id_rsa.pub authorized_keys
root@jin-VirtualBox:~/.ssh# cd
root@jin-VirtualBox:~# ssh localhost
Welcome to Ubuntu 12.04.3 LTS (GNU/Linux 3.8.0-29-generic x86_64)
* Documentation: https://help.ubuntu.com/
388 packages can be updated.
212 updates are security updates.
New release '14.04.2 LTS' available.
Run 'do-release-upgrade' to upgrade to it.
Last login: Sun Mar 15 09:05:03 2015 from localhost6.下载解压hadoop-1.2.1
这里给出个下载各个版本的Hadoop的安装文件的网址http://archive.apache.org/dist/hadoop/core/ ,我这里下载的是 hadoop-1.2.1.tar.gz。
下载后解压到安装目录,我的安装目录如下所示
root@jin-VirtualBox:/usr/local/hadoop# ls
bin google-chrome_amd64.deb hadoop-tools-1.2.1.jar logs
build.xml hadoop-ant-1.2.1.jar input NOTICE.txt
c++ hadoop-client-1.2.1.jar ivy README.txt
CHANGES.txt hadoop-core-1.2.1.jar ivy.xml sbin
conf hadoop-examples-1.2.1.jar lib share
contrib hadoop-minicluster-1.2.1.jar libexec src
docs hadoop-test-1.2.1.jar LICENSE.txt webapps7.配置Hadoop
打开文件 /usr/local/hadoop/conf/hadoop-env.sh ,在文件末尾添加Java目录,内容如下
export JAVA_HOME=/usr/java/jdk1.7.0_51由于我要安装为分布式(Pseudo-Distributed)的Hadoop平台,所以需要配置conf/core-site.xml、conf/hdfs-site.xml和conf/mapred-site.xml,这三个文件都在Hadoop安装目录下。下面分别是配置后的这三个文件的内容
- conf/core-site.xml:
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://localhost:9000value>
property>
configuration>- conf/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>- conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.trackername>
<value>localhost:9001value>
property>
configuration>8.Hadoop的运行
运行Hadoop前要删除临时文件
如果不是第一次运行,需要删除 /tmp/* 临时文件,否则一些进程如 datanode 可能无法启动。
如下所示,/tmp/ 目录下有之前启动Hadoop所产生的一些文件,将其删除即可
root@jin-VirtualBox:/usr/local/hadoop# ls /tmp/
hadoop-root hsperfdata_root
hadoop-root-datanode.pid Jetty_0_0_0_0_50030_job____yn7qmk
hadoop-root-jobtracker.pid Jetty_0_0_0_0_50060_task____.2vcltf
hadoop-root-namenode.pid Jetty_0_0_0_0_50070_hdfs____w2cu08
hadoop-root-secondarynamenode.pid Jetty_0_0_0_0_50075_datanode____hwtdwq
hadoop-root-tasktracker.pid Jetty_0_0_0_0_50090_secondary____y6aanv
root@jin-VirtualBox:/usr/local/hadoop# rm -rf /tmp/*打开SSH
执行命令
ssh localhost屏幕输出:
root@jin-VirtualBox:~# ssh localhost
Welcome to Ubuntu 12.04.3 LTS (GNU/Linux 3.8.0-29-generic x86_64)
* Documentation: https://help.ubuntu.com/
388 packages can be updated.
212 updates are security updates.
New release '14.04.2 LTS' available.
Run 'do-release-upgrade' to upgrade to it.
Last login: Sun Mar 15 09:05:03 2015 from localhost
格式化HDFS文件系统
执行命令:
root@jin-VirtualBox:/usr/local/hadoop# bin/hadoop namenode -format屏幕输出:
root@jin-VirtualBox:/usr/local/hadoop# bin/hadoop namenode -format
15/03/15 09:21:44 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = jin-VirtualBox/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.2.1
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1503152; compiled by 'mattf' on Mon Jul 22 15:23:09 PDT 2013
STARTUP_MSG: java = 1.7.0_51
************************************************************/
15/03/15 09:21:45 INFO util.GSet: Computing capacity for map BlocksMap
15/03/15 09:21:45 INFO util.GSet: VM type = 64-bit
15/03/15 09:21:45 INFO util.GSet: 2.0% max memory = 1013645312
15/03/15 09:21:45 INFO util.GSet: capacity = 2^21 = 2097152 entries
15/03/15 09:21:45 INFO util.GSet: recommended=2097152, actual=2097152
15/03/15 09:21:45 INFO namenode.FSNamesystem: fsOwner=root
15/03/15 09:21:45 INFO namenode.FSNamesystem: supergroup=supergroup
15/03/15 09:21:45 INFO namenode.FSNamesystem: isPermissionEnabled=true
15/03/15 09:21:45 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
15/03/15 09:21:45 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
15/03/15 09:21:45 INFO namenode.FSEditLog: dfs.namenode.edits.toleration.length = 0
15/03/15 09:21:45 INFO namenode.NameNode: Caching file names occuring more than 10 times
15/03/15 09:21:46 INFO common.Storage: Image file /tmp/hadoop-root/dfs/name/current/fsimage of size 110 bytes saved in 0 seconds.
15/03/15 09:21:46 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/tmp/hadoop-root/dfs/name/current/edits
15/03/15 09:21:46 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/tmp/hadoop-root/dfs/name/current/edits
15/03/15 09:21:46 INFO common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted.
15/03/15 09:21:46 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at jin-VirtualBox/127.0.1.1
************************************************************/启动Hadoop环境
执行命令:
root@jin-VirtualBox:/usr/local/hadoop# bin/start-all.sh屏幕输出:
root@jin-VirtualBox:/usr/local/hadoop# bin/start-all.sh
starting namenode, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-namenode-jin-VirtualBox.out
root@localhost's password:
localhost: starting datanode, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-datanode-jin-VirtualBox.out
root@localhost's password:
localhost: starting secondarynamenode, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-secondarynamenode-jin-VirtualBox.out
starting jobtracker, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-jobtracker-jin-VirtualBox.out
root@localhost's password:
localhost: starting tasktracker, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-tasktracker-jin-VirtualBox.out然后可以用 jps 命令查看Hadoop进程启动情况,如下
root@jin-VirtualBox:/usr/local/hadoop# jps
24194 JobTracker
24430 TaskTracker
23854 DataNode
24111 SecondaryNameNode
24557 Jps
23618 NameNode从 jps 命令的打印输出可以看到一共有6个进程,这六个进程缺一不可,否则就意味着启动Hadoop失败,意味着前边步骤有误。
Hadoop守护进程的日志目录是${HADOOP_LOG_DIR} ,即(默认是 ${HADOOP_HOME}/logs).
可以通过浏览器查看NameNode和JobTracker,默认情况下她们的地址:
NameNode - http://localhost:50070/
JobTracker - http://localhost:50030/
下面第一张截图为JobTracker的WEB接口页面
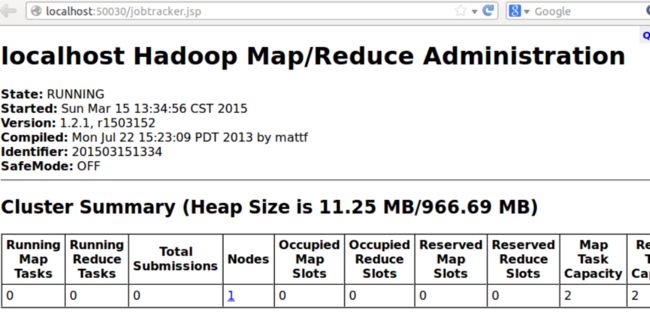
下面一张截图是NameNode的WEB接口页面
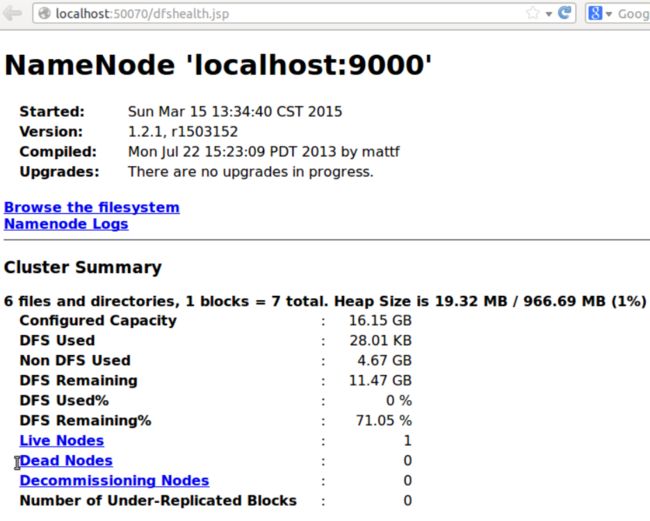
执行Hadoop自带例子
- 将conf文件夹的内容拷贝到分布式文件系统 的input文件,作为样例程序的输入:
bin/hadoop fs -put conf input- 执行样例程序:
bin/hadoop jar hadoop-examples-*.jar grep input output 'dfs[a-z.]+'我们执行的样例程序就是 hadoop-examples-1.2.1.jar,这是个编译好的jar包;参数input是输入,它位于的伪分布式文件系统中,供Hadoop程序调用,在本地文件是不能直接看到的;参数output是输出,它也位于分布式文件系统中,不能直接在本地系统看到。
Hadoop程序执行过程的屏幕输出内容如下:
root@jin-VirtualBox:/usr/local/hadoop# bin/hadoop jar hadoop-examples-*.jar grep input output 'dfs[a-z.]+'
15/03/15 09:23:15 INFO util.NativeCodeLoader: Loaded the native-hadoop library
15/03/15 09:23:15 WARN snappy.LoadSnappy: Snappy native library not loaded
15/03/15 09:23:15 INFO mapred.FileInputFormat: Total input paths to process : 17
15/03/15 09:23:16 INFO mapred.JobClient: Running job: job_201503150922_0001
15/03/15 09:23:17 INFO mapred.JobClient: map 0% reduce 0%
15/03/15 09:23:52 INFO mapred.JobClient: map 11% reduce 0%
15/03/15 09:24:23 INFO mapred.JobClient: map 23% reduce 0%
15/03/15 09:24:34 INFO mapred.JobClient: map 23% reduce 7%
15/03/15 09:24:38 INFO mapred.JobClient: map 35% reduce 7%
15/03/15 09:24:47 INFO mapred.JobClient: map 35% reduce 11%
15/03/15 09:24:50 INFO mapred.JobClient: map 41% reduce 11%
15/03/15 09:24:52 INFO mapred.JobClient: map 47% reduce 11%
15/03/15 09:24:56 INFO mapred.JobClient: map 47% reduce 15%
15/03/15 09:25:02 INFO mapred.JobClient: map 58% reduce 15%
15/03/15 09:25:12 INFO mapred.JobClient: map 58% reduce 19%
15/03/15 09:25:15 INFO mapred.JobClient: map 70% reduce 19%
15/03/15 09:25:21 INFO mapred.JobClient: map 82% reduce 19%
15/03/15 09:25:27 INFO mapred.JobClient: map 94% reduce 27%
15/03/15 09:25:31 INFO mapred.JobClient: map 100% reduce 27%
15/03/15 09:25:36 INFO mapred.JobClient: map 100% reduce 31%
15/03/15 09:25:40 INFO mapred.JobClient: map 100% reduce 100%
15/03/15 09:25:43 INFO mapred.JobClient: Job complete: job_201503150922_0001
15/03/15 09:25:45 INFO mapred.JobClient: Counters: 30
15/03/15 09:25:45 INFO mapred.JobClient: Job Counters
15/03/15 09:25:45 INFO mapred.JobClient: Launched reduce tasks=1
15/03/15 09:25:45 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=230152
15/03/15 09:25:45 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
15/03/15 09:25:45 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
15/03/15 09:25:45 INFO mapred.JobClient: Launched map tasks=17
15/03/15 09:25:45 INFO mapred.JobClient: Data-local map tasks=17
15/03/15 09:25:45 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=98921
15/03/15 09:25:45 INFO mapred.JobClient: File Input Format Counters
15/03/15 09:25:45 INFO mapred.JobClient: Bytes Read=34251
15/03/15 09:25:45 INFO mapred.JobClient: File Output Format Counters
15/03/15 09:25:45 INFO mapred.JobClient: Bytes Written=180
15/03/15 09:25:45 INFO mapred.JobClient: FileSystemCounters
15/03/15 09:25:45 INFO mapred.JobClient: FILE_BYTES_READ=82
15/03/15 09:25:45 INFO mapred.JobClient: HDFS_BYTES_READ=36085
15/03/15 09:25:45 INFO mapred.JobClient: FILE_BYTES_WRITTEN=985546
15/03/15 09:25:45 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=180
15/03/15 09:25:45 INFO mapred.JobClient: Map-Reduce Framework
15/03/15 09:25:45 INFO mapred.JobClient: Map output materialized bytes=178
15/03/15 09:25:45 INFO mapred.JobClient: Map input records=959
15/03/15 09:25:45 INFO mapred.JobClient: Reduce shuffle bytes=178
15/03/15 09:25:45 INFO mapred.JobClient: Spilled Records=6
15/03/15 09:25:45 INFO mapred.JobClient: Map output bytes=70
15/03/15 09:25:45 INFO mapred.JobClient: Total committed heap usage (bytes)=2363408384
15/03/15 09:25:45 INFO mapred.JobClient: CPU time spent (ms)=15020
15/03/15 09:25:45 INFO mapred.JobClient: Map input bytes=34251
15/03/15 09:25:45 INFO mapred.JobClient: SPLIT_RAW_BYTES=1834
15/03/15 09:25:45 INFO mapred.JobClient: Combine input records=3
15/03/15 09:25:45 INFO mapred.JobClient: Reduce input records=3
15/03/15 09:25:45 INFO mapred.JobClient: Reduce input groups=3
15/03/15 09:25:45 INFO mapred.JobClient: Combine output records=3
15/03/15 09:25:45 INFO mapred.JobClient: Physical memory (bytes) snapshot=2922946560
15/03/15 09:25:45 INFO mapred.JobClient: Reduce output records=3
15/03/15 09:25:45 INFO mapred.JobClient: Virtual memory (bytes) snapshot=17545351168
15/03/15 09:25:45 INFO mapred.JobClient: Map output records=3
15/03/15 09:25:46 INFO mapred.FileInputFormat: Total input paths to process : 1
15/03/15 09:25:49 INFO mapred.JobClient: Running job: job_201503150922_0002
15/03/15 09:25:50 INFO mapred.JobClient: map 0% reduce 0%
15/03/15 09:25:59 INFO mapred.JobClient: map 100% reduce 0%
15/03/15 09:26:13 INFO mapred.JobClient: map 100% reduce 100%
15/03/15 09:26:15 INFO mapred.JobClient: Job complete: job_201503150922_0002
15/03/15 09:26:15 INFO mapred.JobClient: Counters: 30
15/03/15 09:26:15 INFO mapred.JobClient: Job Counters
15/03/15 09:26:15 INFO mapred.JobClient: Launched reduce tasks=1
15/03/15 09:26:15 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=9585
15/03/15 09:26:15 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
15/03/15 09:26:15 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
15/03/15 09:26:15 INFO mapred.JobClient: Launched map tasks=1
15/03/15 09:26:15 INFO mapred.JobClient: Data-local map tasks=1
15/03/15 09:26:15 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=13744
15/03/15 09:26:15 INFO mapred.JobClient: File Input Format Counters
15/03/15 09:26:15 INFO mapred.JobClient: Bytes Read=180
15/03/15 09:26:15 INFO mapred.JobClient: File Output Format Counters
15/03/15 09:26:15 INFO mapred.JobClient: Bytes Written=52
15/03/15 09:26:15 INFO mapred.JobClient: FileSystemCounters
15/03/15 09:26:15 INFO mapred.JobClient: FILE_BYTES_READ=82
15/03/15 09:26:15 INFO mapred.JobClient: HDFS_BYTES_READ=295
15/03/15 09:26:15 INFO mapred.JobClient: FILE_BYTES_WRITTEN=107941
15/03/15 09:26:15 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=52
15/03/15 09:26:15 INFO mapred.JobClient: Map-Reduce Framework
15/03/15 09:26:15 INFO mapred.JobClient: Map output materialized bytes=82
15/03/15 09:26:15 INFO mapred.JobClient: Map input records=3
15/03/15 09:26:15 INFO mapred.JobClient: Reduce shuffle bytes=82
15/03/15 09:26:15 INFO mapred.JobClient: Spilled Records=6
15/03/15 09:26:15 INFO mapred.JobClient: Map output bytes=70
15/03/15 09:26:15 INFO mapred.JobClient: Total committed heap usage (bytes)=123277312
15/03/15 09:26:15 INFO mapred.JobClient: CPU time spent (ms)=2080
15/03/15 09:26:15 INFO mapred.JobClient: Map input bytes=94
15/03/15 09:26:15 INFO mapred.JobClient: SPLIT_RAW_BYTES=115
15/03/15 09:26:15 INFO mapred.JobClient: Combine input records=0
15/03/15 09:26:15 INFO mapred.JobClient: Reduce input records=3
15/03/15 09:26:15 INFO mapred.JobClient: Reduce input groups=1
15/03/15 09:26:15 INFO mapred.JobClient: Combine output records=0
15/03/15 09:26:15 INFO mapred.JobClient: Physical memory (bytes) snapshot=247898112
15/03/15 09:26:15 INFO mapred.JobClient: Reduce output records=3
15/03/15 09:26:15 INFO mapred.JobClient: Virtual memory (bytes) snapshot=1954955264
15/03/15 09:26:15 INFO mapred.JobClient: Map output records=3查看Hadoop程序的输出文件内容
有两种方法,一个是在本地文件系统上查看,一个是直接在分布式文件系统上查看。把程序输出从分布式文件系统拷贝到本地系统,然后在本地系统查看文件内容
bin/hadoop fs -get output output
cat output/*直接在分布式文件系统查看
bin/hadoop fs -cat output/*
文件内容如下:
cat: output/_logs: Is a directory
1 dfs.replication
1 dfs.server.namenode.
1 dfsadmin
停止Hadoop守护进程
每次使用Hadoop结束后不要忘了关闭Hadoop程序,命令:
root@jin-VirtualBox:/usr/local/hadoop# bin/stop-all.sh
屏幕输出:
root@jin-VirtualBox:/usr/local/hadoop# bin/stop-all.sh
stopping jobtracker
root@localhost's password:
localhost: stopping tasktracker
stopping namenode
root@localhost's password:
localhost: stopping datanode
root@localhost's password:
localhost: stopping secondarynamenode进一步阅读
most relevant
- Cluster Setup
http://hadoop.apache.org/docs/r1.2.1/cluster_setup.html - Single Node Setup
http://hadoop.apache.org/docs/r1.2.1/single_node_setup.html - HADOOP TUTORIALS
http://hadooptutorials.co.in/index.html - INSTALL HADOOP ON UBUNTU
http://hadooptutorials.co.in/tutorials/hadoop/install-hadoop-on-ubuntu.html#
less relevant
- 用MapReduce实现矩阵乘法
http://blog.fens.me/hadoop-mapreduce-matrix/ - MapReduce实现大矩阵乘法
http://blog.csdn.net/xyilu/article/details/9066973 - PageRank算法并行实现
http://blog.fens.me/algorithm-pagerank-mapreduce/ - Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
http://blog.csdn.net/hitwengqi/article/details/8008203 - 运行Hadoop遇到的问题
http://www.cnblogs.com/liangzh/archive/2012/04/06/2434602.html - hadoop 配置中的几个小笔记
http://blog.csdn.net/shomy_liu/article/details/43192231 - hadoop-2.6.0集群环境搭建
http://blog.csdn.net/fteworld/article/details/41944597 - Hadoop-2.6.0环境搭建精简极致指导
http://www.linuxidc.com/Linux/2015-01/111258.htm