【Scikit-learn】【模型预处理-1-数据获取】获取样本数据(iris/boston/digits等数据集) + 创建样本数据(回归/分类/聚类等数据集)
数据获取(setting data)主要介绍如何创建模拟数据(fake data)。
创建模拟数据并用模型进行拟合是模型测试的重要一个步骤。当我们code好一个算法后,如果手边没有数据,就可以创建模拟数据来测试算法的正确性和合理性。
1.从外部源获取样本数据
1.1scikit-learn内置数据库
方便起见,可以用scikit-learn的内置数据库,他们可用于测试不同的建模技术,比如回归和分类。
datasets模块主要有两种数据类型。
较小的测试数据集在sklearn包里面,可以通过datasets.load_*查看。
另外一些数据集需要通过datasets.fetch_*?下载,这些数据集更大,没有被自动安装。
有时这些大数据集可以更好的测试模型和算法,用于测试那些解决实际问题的算法,因为比较复杂足以模拟现实情形。
1.2示例代码
# -*- coding: utf-8 -*-
"""
@Author:蔚蓝的天空Tom
"""
#scikit-learn的内置数据库在datasets模块里
from sklearn import datasets
#加载iris数据集
iris = datasets.load_iris()
#加载digits数据集
digits = datasets.load_digits()
#加载boston数据集
boston = datasets.load_boston()
#digits.DESCR给出了digits数据集的概述
print('digits.DESCR:\n', digits.DESCR)
#在数字数据集的情况下digits.data,可以访问可用于对数字样本进行分类的功能
print('digits.data:\n', digits.data)
#并digits.target给出数字数据集的真实数据,即我们正在尝试学习的每个数字图像对应的数字
print('digits.target:\n', digits.target)
#0 image
print('digits.images[0]:\n',digits.images[0])
#1 image
print('digits.images[1]:\n', digits.images[1])
#4 image
print('digits.images[4]:\n', digits.images[4])1.3运行结果
runfile('C:/Users/tom/skl.py', wdir='C:/Users/tom')
digits.DESCR:
Optical Recognition of Handwritten Digits Data Set
===================================================
Notes
-----
Data Set Characteristics:
:Number of Instances: 5620
:Number of Attributes: 64
:Attribute Information: 8x8 image of integer pixels in the range 0..16.
:Missing Attribute Values: None
:Creator: E. Alpaydin (alpaydin '@' boun.edu.tr)
:Date: July; 1998
This is a copy of the test set of the UCI ML hand-written digits datasets
http://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits
The data set contains images of hand-written digits: 10 classes where
each class refers to a digit.
Preprocessing programs made available by NIST were used to extract
normalized bitmaps of handwritten digits from a preprinted form. From a
total of 43 people, 30 contributed to the training set and different 13
to the test set. 32x32 bitmaps are divided into nonoverlapping blocks of
4x4 and the number of on pixels are counted in each block. This generates
an input matrix of 8x8 where each element is an integer in the range
0..16. This reduces dimensionality and gives invariance to small
distortions.
For info on NIST preprocessing routines, see M. D. Garris, J. L. Blue, G.
T. Candela, D. L. Dimmick, J. Geist, P. J. Grother, S. A. Janet, and C.
L. Wilson, NIST Form-Based Handprint Recognition System, NISTIR 5469,
1994.
References
----------
- C. Kaynak (1995) Methods of Combining Multiple Classifiers and Their
Applications to Handwritten Digit Recognition, MSc Thesis, Institute of
Graduate Studies in Science and Engineering, Bogazici University.
- E. Alpaydin, C. Kaynak (1998) Cascading Classifiers, Kybernetika.
- Ken Tang and Ponnuthurai N. Suganthan and Xi Yao and A. Kai Qin.
Linear dimensionalityreduction using relevance weighted LDA. School of
Electrical and Electronic Engineering Nanyang Technological University.
2005.
- Claudio Gentile. A New Approximate Maximal Margin Classification
Algorithm. NIPS. 2000.
digits.data:
[[ 0. 0. 5. ..., 0. 0. 0.]
[ 0. 0. 0. ..., 10. 0. 0.]
[ 0. 0. 0. ..., 16. 9. 0.]
...,
[ 0. 0. 1. ..., 6. 0. 0.]
[ 0. 0. 2. ..., 12. 0. 0.]
[ 0. 0. 10. ..., 12. 1. 0.]]
digits.target:
[0 1 2 ..., 8 9 8]
digits.images[0]:
[[ 0. 0. 5. 13. 9. 1. 0. 0.]
[ 0. 0. 13. 15. 10. 15. 5. 0.]
[ 0. 3. 15. 2. 0. 11. 8. 0.]
[ 0. 4. 12. 0. 0. 8. 8. 0.]
[ 0. 5. 8. 0. 0. 9. 8. 0.]
[ 0. 4. 11. 0. 1. 12. 7. 0.]
[ 0. 2. 14. 5. 10. 12. 0. 0.]
[ 0. 0. 6. 13. 10. 0. 0. 0.]]
digits.images[1]:
[[ 0. 0. 0. 12. 13. 5. 0. 0.]
[ 0. 0. 0. 11. 16. 9. 0. 0.]
[ 0. 0. 3. 15. 16. 6. 0. 0.]
[ 0. 7. 15. 16. 16. 2. 0. 0.]
[ 0. 0. 1. 16. 16. 3. 0. 0.]
[ 0. 0. 1. 16. 16. 6. 0. 0.]
[ 0. 0. 1. 16. 16. 6. 0. 0.]
[ 0. 0. 0. 11. 16. 10. 0. 0.]]
digits.images[4]:
[[ 0. 0. 0. 1. 11. 0. 0. 0.]
[ 0. 0. 0. 7. 8. 0. 0. 0.]
[ 0. 0. 1. 13. 6. 2. 2. 0.]
[ 0. 0. 7. 15. 0. 9. 8. 0.]
[ 0. 5. 16. 10. 0. 16. 6. 0.]
[ 0. 4. 15. 16. 13. 16. 1. 0.]
[ 0. 0. 0. 3. 15. 10. 0. 0.]
[ 0. 0. 0. 2. 16. 4. 0. 0.]]1.4如何使用加载的数据集?
Step1:导入模块
#scikit-learn的内置数据库在datasets模块里
from sklearn import datasetsStep2:加载数据
#加载boston数据集
boston = datasets.load_boston()Step3:使用data和target
加载得到的boston并不是直接转换成Numpy数组,而是Bunch类型。Bunch可以看成一个词典,键被示例对象作为属性使用。
data属性:用data属性连接数据中包含自变量的Numpy数组
target属性:用target属性连接数据中的因变量。
x, y = boston.data, boston.target示例:
# -*- coding: utf-8 -*-
"""
@Author:蔚蓝的天空Tom
"""
#scikit-learn的内置数据库在datasets模块里
from sklearn import datasets
#加载boston数据集
boston = datasets.load_boston()
#使用数据集的data和target
x,y = boston.data,boston.target
print('type(boston.data):',type(x))
print('type(boston.target):',type(y))
print('boston.data:\n', boston.data)
print('boston.target:\n', boston.target)运行结果:
type(boston.data):
type(boston.target):
boston.data:
[[ 6.32000000e-03 1.80000000e+01 2.31000000e+00 ..., 1.53000000e+01
3.96900000e+02 4.98000000e+00]
[ 2.73100000e-02 0.00000000e+00 7.07000000e+00 ..., 1.78000000e+01
3.96900000e+02 9.14000000e+00]
[ 2.72900000e-02 0.00000000e+00 7.07000000e+00 ..., 1.78000000e+01
3.92830000e+02 4.03000000e+00]
...,
[ 6.07600000e-02 0.00000000e+00 1.19300000e+01 ..., 2.10000000e+01
3.96900000e+02 5.64000000e+00]
[ 1.09590000e-01 0.00000000e+00 1.19300000e+01 ..., 2.10000000e+01
3.93450000e+02 6.48000000e+00]
[ 4.74100000e-02 0.00000000e+00 1.19300000e+01 ..., 2.10000000e+01
3.96900000e+02 7.88000000e+00]]
boston.target:
[ 24. 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 15. 18.9
21.7 20.4 18.2 19.9 23.1 17.5 20.2 18.2 13.6 19.6 15.2 14.5
15.6 13.9 16.6 14.8 18.4 21. 12.7 14.5 13.2 13.1 13.5 18.9
20. 21. 24.7 30.8 34.9 26.6 25.3 24.7 21.2 19.3 20. 16.6
14.4 19.4 19.7 20.5 25. 23.4 18.9 35.4 24.7 31.6 23.3 19.6
22.8 23.4 24.1 21.4 20. 20.8 21.2 20.3 28. 23.9 24.8 22.9
...,
16.1 14.3 11.7 13.4 9.6 8.7 8.4 12.8 10.5 17.1 18.4 15.4
10.8 11.8 14.9 12.6 14.1 13. 13.4 15.2 16.1 17.8 14.9 14.1
12.7 13.5 14.9 20. 16.4 17.7 19.5 20.2 21.4 19.9 19. 19.1
19.1 20.1 19.9 19.6 23.2 29.8 13.8 13.3 16.7 12. 14.6 21.4
23. 23.7 25. 21.8 20.6 21.2 19.1 20.6 15.2 7. 8.1 13.6
20.1 21.8 24.5 23.1 19.7 18.3 21.2 17.5 16.8 22.4 20.6 23.9
22. 11.9]
1.5数据集文件在本地的路径???
使用datasets.get_data_home()可以查看datasets加载数据集的路径:
print(datasets.get_data_home())C:\Users\tom\scikit_learn_data2.创建样本数据
2.1为啥自己创建样本数据
如果实在没有数据,自己动手创建样本数据。这里介绍如何用scikit-learn创建一些试验用的样本数据。
和从dataset加载数据集一样,也需要导入datasets模块,然后使用“make_数据集名称”函数来创建样本数据集,而make_数据集名称的函数,datasets已经提供好了,只需要调用就可以。
#导入datasets模块
from sklearn import datasets2.2“make_数据集名称”函数
make_数据集名称的函数在datasets模块中已经提供,如下所示:
datasets.make_biclusters
datasets.make_blobs
datasets.make_checkerboard
datasets.make_circles
datasets.make_classification
datasets.make_friedman1
datasets.make_friedman2
datasets.make_friedman3
datasets.make_gaussian_quantiles
datasets.make_hastie_10_2
datasets.make_low_rank_matrix
datasets.make_moons
datasets.make_multilabel_classification
datasets.make_regression
datasets.make_s_curve
datasets.make_sparse_coded_signal
datasets.make_sparse_spd_matrix
datasets.make_sparse_uncorrelated
datasets.make_spd_matrix
datasets.make_swiss_roll2.3创建默认的回归数据集
创建回归数据就需要用函数:sklearn.datasets.make_regression()
# -*- coding: utf-8 -*-
"""
@Author:蔚蓝的天空Tom
Aim:使用sklearn.datasets.make_数据集名称创建数据集
"""
#导入datasets模块
from sklearn import datasets
import numpy as np
def make_dataset():
reg_data = datasets.make_regression()
print('type(reg_data):', type(reg_data))
print('np.shape(reg_data[0]):', np.shape(reg_data[0]))
print('np.shape(reg_data[1]):', np.shape(reg_data[1]))
if __name__=='__main__':
make_dataset()下面是运行结果:
type(reg_data):
np.shape(reg_data[0]): (100, 100)
np.shape(reg_data[1]): (100,) 解释:
reg_data是一个tuple元组对象,
第一个元素reg_data[0]是一个100*100的矩阵,100个样本,每个样本10个特征(自变量)
第二个元素reg_data[1]是一个因变量,对应自变量的样本数量,也是100个样本。
默认情况下,只有10个特征和因变量相关,其他90个特征都与因变量无关。
2.4创建自定义回归数据集
创建自定义回归数据集,也是用函数:sklearn.datasets.make_regression()
# -*- coding: utf-8 -*-
"""
@Author:蔚蓝的天空Tom
Aim:使用sklearn.datasets.make_数据集名称创建自定义回归数据集
"""
import sklearn
from sklearn import datasets
import numpy as np
def make_dataset():
'''创建一个(5, 4)的矩阵,3个特征与因变量相关,误差系数0.2,两个因变量'''
reg_data = sklearn.datasets.make_regression(5, 4, 3, 2, 1.0)
print('type(reg_data):', type(reg_data))
print('np.shape(reg_data[0]):', reg_data[0].shape)
print('np.shape(reg_data[1]):', reg_data[1].shape)
print(reg_data[0])
print(reg_data[1])
if __name__=='__main__':
make_dataset()运行结果:
runfile('C:/Users/tom/skl.py', wdir='C:/Users/tom')
type(reg_data):
np.shape(reg_data[0]): (5, 4)
np.shape(reg_data[1]): (5, 2)
[[-0.73705188 -0.93247734 -1.55733945 0.26999472]
[ 0.00293358 0.11518704 -0.31592267 1.97928462]
[-0.47676447 0.02056597 0.36606973 -0.96841994]
[-2.64726925 0.37042588 1.57393408 -2.88966099]
[ 0.11630562 -0.28589382 -0.91362942 -1.54737346]]
[[ -84.94058663 -15.08196338]
[ 114.29718537 77.98579547]
[ -99.31436152 -35.34584721]
[-410.66023535 -101.07333699]
[ -81.63215143 -64.25420569]]
解释:
上面代码使用sklearn.datasets.make_regression()函数创建了自定义回归数据集:5个样本,4个特征的样本,其中3个特征和因变量有关,误差系数0.2,2个因变量
2.5创建非均衡的分类数据集
# -*- coding: utf-8 -*-
"""
@Author:蔚蓝的天空Tom
Aim:使用sklearn.datasets.make_数据集名称创建数据集
"""
#导入datasets模块
import sklearn
from sklearn import datasets
import numpy as np
def make_classification_dataset():
class_set = datasets.make_classification(weights=[0.1])
print('type(class_set):', type(class_set))
print('np.shape(class_set[0]):', np.shape(class_set[0]))
print('np.shape(class_set[1]):', np.shape(class_set[1]))
print('np.bincount(class_set[1]):', np.bincount(class_set[1]))
print('class_set[0]:\n', class_set[0])
print('class_set[1]:\n', class_set[1])
if __name__=='__main__':
make_classification_dataset()运行结果:
runfile('C:/Users/tom/skl.py', wdir='C:/Users/tom')
type(class_set):
np.shape(class_set[0]): (100, 20)
np.shape(class_set[1]): (100,)
np.bincount(class_set[1]): [11 89]
class_set[0]:
[[ 0.15984021 0.24169017 1.82124207 ..., 0.1222807 -2.05318975
0.91718089]
[ 1.62690873 -1.21176587 -1.00683397 ..., 0.0798417 -0.68858431
1.63949305]
[ 0.86604744 -1.59632124 -1.27628663 ..., -0.0189034 -0.04692722
0.17478466]
...,
[ 0.38644212 -1.13961715 1.47605143 ..., -0.11353083 0.61592403
0.20563102]
[ 1.7012878 -0.74427877 -0.33914127 ..., 0.24237423 -0.8491314
1.56469418]
[ 1.15517498 0.4518697 0.13116246 ..., -0.5242128 -0.55132599
-0.56071672]]
class_set[1]:
[1 1 1 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1 1 0 1 1 0 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 0 1 1 1 1 1 1 0 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1]
说明:
class_set是一个tuple元组对象,
第一个属性class_set[0]是一个(100, 20)的数组对象
第二个属性class_set[1]是一个长度为100的数组对象
可以知道,分类值∈{0, 1}
2.6创建K-Means聚类数据及
使用sklearn.dataset.make_*函数也可以创建聚类数据集。而且有一些函数可以为不同的聚类算法创建对应的数据集
sklearn.datasets.make_blobs函数可以创建K-Means聚类数据集。
# -*- coding: utf-8 -*-
"""
@Author:蔚蓝的天空Tom
Aim:使用sklearn.datasets.make_blobs创建K-means聚类数据集
"""
#导入datasets模块
import sklearn
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
def make_kmeans_dataset():
'''make_blobs函数可以轻松创建K-Means聚类数据集'''
blobs = datasets.make_blobs(200)
f = plt.figure(figsize=(8, 4))
ax = f.add_subplot(111)
ax.set_title("A blob with 3 centers")
colors = np.array(['r', 'g', 'b'])
x = blobs[0][:,0]
y = blobs[0][:,1]
ax.scatter(x, y, color=colors[blobs[1].astype(int)], alpha=0.75)
if __name__=='__main__':
make_kmeans_dataset()运行结果:
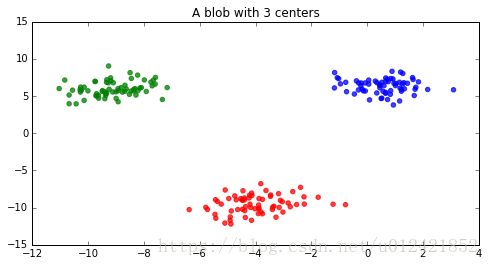
聚类数据很容易理解,就不做解释了。
参考文献:
[1]《Scikit-learn秘籍》
(end)