渲染流水线
最近学习CG,总是有点不懂的地方,回头想想,觉得应该是渲染流水线方面不是特别透彻的原因,所以,学习了《CG教程_可编程实时图形权威指南》以及《GPU编程与CG语言之阳春白雪下里巴人》中关于渲染流水线方面的知识,再参入一部分网上博客的内容。有所收获,所以来与大家分享。
本文的主线:渲染流水线的设计模式》渲染流水线的分类及其意义》渲染流水线的具体流程。
渲染流水线的设计
为了解决D3D或者OpenGL对不同硬件厂商的支持,解决移植性的问题,可以通过将加速卡功能抽象出来,统一定义接口的形式来实现。于是,人们采用了典型的分层模式(参阅:设计模式),将一套应用程序分为3个层次: 应用程序层 -> 硬件抽象层 -> 硬件层。 如下图

图 1
应用层就是游戏和应用软件开发人员的开发主体,他们调用统一的加速卡API来进行上层开发,而不用考虑移植性问题。
硬件抽象层则抽象出硬件的加速功能,进行有利于应用层开发的封装,并向应用层开放API。
硬件层将硬件驱动提供给抽象层,以实现抽象层加速功能的有效性。
这个 结构有两个好处 :1. 有效的将游戏和应用程序 与硬件加速卡隔离开,这就很好的提升了程序的移植能力。2. 开发人员的知识复用率得到提高,从而降低了这类软件的开发。
渲染流水线的分类及其意义
首先,我们需要了解一个概念:Shader,中文名,着色器。着色器其实就是一段在GPU运行的程序。我们平时的程序,是在CPU运行。
· 由于GPU的硬件设计结构与CPU有着很大的不同,所以GPU需要一些新的编程语言。目前,微软提供了 HLSL(High Level Shading Language),通过Direct3D图形软件库来写Shader。OpenGL提供了GLSL(OpenGL Shading Language)来写Shader程序。NIVIDIA希望显卡的程序开发独立于DX和GL的图形软件库,与微软共同研发了CG语言(C for graphics)。因为它是在HLSL的基础上进行开发的,所以他的语法跟HLSL非常相似。并且,CG编写的Shader可以编译到D3D和GL能适应的环境。
程序员在使用图形渲染程序时,假如对着色器进行了编程,则称渲染流水线为 可编程渲染流水线 。假如没有对着色器进行编程,而是使用了默认的着色器时,称渲染流水线为 固定渲染流水线 。(也称可编程管线或固定管线,管线就是流水线的意思)
从上面的字面意思大家可以看出,实际上可编程渲染流水线与固定渲染流水线的区别只是在于我们是否对GPU进行编程。而其它的都是一样的。那么这个时候大家心中一定会有一个疑问,可编程渲染流水线存在的意义是什么?
这个要从现实与虚拟的差距说起,我们知道现实的世界五彩缤纷,而我们对于现实世界的模拟,实际上就是对现实世界里面各种存在的事物进行一一的模拟。而默认的着色器,对于模拟五彩缤纷的世界就捉襟见肘了。而要让编写默认着色器的程序员把所有的情况一一列举,不仅会使得SDK非常庞大,而且也不太可能办到。所以,有必要让渲染流水线可编程,以满足用户无穷的胃口。打个比方,画家在画一幅画的时候,要用的色彩或许有上万种,我们无法为他提供所有可能用到的色彩,只能让画家可以通过自己的喜好混合不同的颜色。你可以把着色器理解为这里面的各种颜色,自己写的着色器就是自己调的颜色。
渲染流水线的具体流程
前面说了,渲染流水线包括了 应用程序层 -> 硬件抽象层 -> 硬件层。 我们首先讲解一下应用程序层以及这一层能够做的事。
1. 应用程序层
应用程序层主要与内存,CPU打交道,诸如碰撞检测,场景图监理,视锥裁剪等经典算法在此阶段执行。在阶段的末端,几何体的数据(顶点坐标,法向量,纹理坐标,纹理)等通过数据总线传送到图形硬件(时间瓶颈)。
这里面讲到了两个东西:经典算法与数据总线。为什么特意提一下呢?这需要我们先了解一下后续的一些知识:GPU会对我们一些不会进行绘制的物体进行剔除,比如物体的背面或者超出视域体范围的物体。假如我们把游戏里面所有的物体全部抛给GPU,那么GPU的负担就会特别重。所以这部分的优化做不好,那么即使有很劲爆的 GPU,也难以渲染出一个绚丽的游戏世界。而数据总线,每次能够传输的数据量是有限的,并且数据总线是整台计算机共用的,在我们的游戏里面,数据总线把游戏里面的数据从内存传送到了GPU。假如我们对它好不客气,那么不仅我们的游戏运行的时候会经常出现卡顿的现象,我们整台电脑运行的速度也会下降。
2. 硬件抽象层
在这一层,我们目前使用的是DirectX与OpenGL。对于这一部分,主要是一些API等的调用。这方面不是我们今天的重点,所以直接到重点部分。
3. 硬件层
硬件层在渲染流水线中最为复杂,也最为重要。前面已经提到,可编程渲染流水线与固定渲染流水线的区别在于是否对着色器进行编程。
首先我们先了解固定渲染流水线它主要分为以下几个阶段:顶点变换->图元装配与光栅化->片段纹理映射和着色->光栅化操作。如下图

图 2
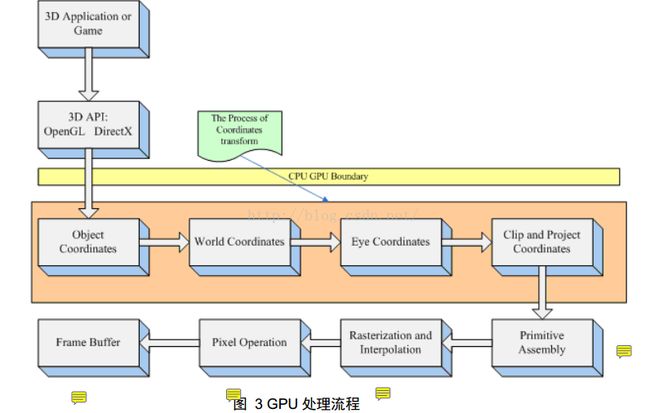
下面,我们再看一下可编程渲染流水线硬件层的流程图。

图 3
对比上面的两个图我们发现,在可编程渲染流水线中,固定渲染流水线中的顶点变换与片段纹理映射和着色被分离出来,作为可编程顶点处理器与可编程片段处理器。而如前面所述,假如我们使用DirectX或者OpenGL自带着色程序,那么两条流水线其实是一样的。所以,下面我们将对可编程渲染流水线进行讲解。
下面,我们主要从 可编程顶点处理器,图元装配,光栅化和插值,可编程片段处理器,光栅化操作 来讲解硬件层的渲染流水线。
1) 可编程顶点处理器(下面的流水线都是指硬件层部分)
顶点变换:在固定渲染流水线或者可编程渲染流水线中这都是第一个处理阶段。这个阶段对顶点进行了一系列的数学变换。包括了世界变换,取景变换,投影变换,视口变换。另外,贴图纹理坐标的产生,照亮顶点以及决定顶点的颜色,都在这个阶段进行。
主要流程为下面的两层
顶点坐标变化顺序
从object space到 world space
1),object space coordinate就是模型文件中的顶点值,这些值是在模型建模时得到的;
2),object space coordinate 与其他物体没有任何参照关系;
3),将一个模型导入计算机后,就应该给它一个相对于坐标原点的位置,那么这个位置就是
world space coordinate,从 object space coordinate 到world space coordinate 的变换过程
由一个四阶矩阵控制,通常称之为 worldmatrix。
4),无论在现实世界,还是在计算机的虚拟空间中,物体都必须和一个固定的坐标原点进行
参照才能确定自己所在的位置,这是 world space coordinate的实际意义所在
*顶点法向量在模型文件中属于 object space,在 GPU 的顶点程序中必须将法向量转换到
world space 中才能使用,法向量从 object space 到 world space 的转换矩阵是 world matrix
的转置矩阵的逆矩阵
从 world space 到 eye space
1),屏幕显示的内容随着视点的变化而变化,这是因为 GPU 将物体顶点坐标从 world spa
ce 转换到了 eye space。
2),所谓 eye space,即以 camera(视点或相机)为原点,由视线方向、视角和
远近平面,共同组成一个梯形体的三维空间,称之为 viewing frustum(视锥),
如图 4 所示。近平面,是梯形体较小的矩形面,作为投影平面,远平面是梯形体
较大的矩形,在这个梯形体中的所有顶点数据是可见的,而超出这个梯形体之外
的场景数据,会被视点去除( Frustum Culling,也称之为视锥裁剪)。
从 eye space 到 project and clip space
一旦顶点坐标被转换到 eye space 中,就需要判断哪些点是视点可见的。
位于 viewing frustum 梯形体以内的顶点,被认定为可见,而超出这个梯形体之外
的场景数据,会被视点去除( Frustum Culling,也称之为视锥裁剪)。这一步通常
称之为“clip(裁剪) ”,识别指定区域内或区域外的图形部分的过程称之为裁剪
算法。
投影:把一个物体从n维变换到n-1维的过程称为投影。所以我们三维的世界转换到2D的屏幕上的过程也叫做投影。
视域体裁剪:在以摄像机为中心,由视线方向,视角和远近平面共同构成的一个梯形体,在梯形体内的物体可见,梯形体外的物体不可见。裁剪这部分不可见物体的过程称为视域体裁剪。
在下图中,梯形体为三维空间中的一部分,超出梯形体部分的物体将会被剔除。而在视域体中的物体,最终会形成一幅图像,展示在近平面上。这里默认裁剪平面与投影片面重合。

图 4
投影矩阵:将3D世界里顶点变换到投影平面上的矩阵。即一个三维的顶点与这个矩阵相乘,能够将空间中的顶点变换到投影平面上(最终的顶点依然具有4个维度,第四个维度只是用来区分3维的向量是点还是普通的数学向量)。具体,大家可以参考下面的链接
ttp://blog.csdn.net/popy007/article/details/1797121#comments
回归我们的问题,到底是投影先还是裁剪先呢?
实际上,当我们把空间中的点变换到投影平面的时候,假如一个点不在视域体的范围内,那么变换后的点的坐标不会在(-1,-1,-1)到(1,1,1)的范围内(OpenGL以这个为标准),说明这个点是被裁剪的顶点。而假如变换后的坐标在这个范围内,其(x,y)坐标就是对应的视口坐标系的坐标了。所以,实际上我们做投影变换的时候其实也同时为裁剪做了准备,也就是裁剪跟投影其实是同步的,只是裁剪的周期会比较长一点。
这里其实有个问题刚好被我跳过了,就是为什么不直接在3D的空间里面进行裁剪,要转换到投影屏幕上才进行裁剪。这里涉及到实现的难度的问题。视域体是一个3D的梯形,我们要在3D的空间里对顶点进行剔除,是一件非常难以实现的事,所以才将顶点变换到投影平面上。
下面让我们看一下可编程顶点着色器的工作流程。

图 5
2) 图元装配
图元:实际上就是点,线,面。
图元装配阶段的工作:根据伴随顶点序列的集合图元分类信息把顶点装配几何图元。产生一系列的三角形,线段和点。(之前的流水线只是对顶点进行处理)。(将顶点根据 primitive(原始的连接关系) ,还原出网格结构,网格由顶点和索引组成)
挑选:光栅器根据多边形的朝前或朝后来丢弃一些多边形。在此阶段进行。(CG教程P13)
多边形经过挑选后 ,进入光栅化插值。
3) 光栅化插值
首先解释一下,为什么要用光栅化插值而不用光栅化。我学习渲染流水线主要是通过上面的那个流程图来学习的,而他的作者将光栅化分为了光栅化插值与光栅化操作,所以我也继续沿用了他的方法。下面先介绍几个概念。
光栅化:一个决定哪些像素被几何图元覆盖的过程。光栅化的结果是像素位置的集合和片段位置的集合。(CG教程_P13)
片段:是更新一个特定像素潜在需要的一个状态。
术语片段是因为光栅化会把每个几何图元,例如三角形,所覆盖的像素分解成像素大小的片段。一个片段有一个与之相关联的像素位置,深度值和经过插值的参数,例如颜色,第二(反射)颜色和一个或多个纹理坐标集。这些各种各样的经过插值的参数是来自变换过的顶点,这些顶点组成了某个用来生成片段的几何图元。如果一个片段通过了各种各样的光栅化测试,这个片段将被用于更新帧缓存中的像素。(可以把片段看成是潜在的像素)。(来自CG教程_可编程实时图形权威指南P14)
在这个阶段,光栅器还可以根据多边形的朝前或朝后来丢弃一些多边形(挑选culling)。
· 实际裁减是一个较大的概念,为了减少需要绘制的顶点个数,而识别指定区域内或区域外的图形部分的算法都称之为裁减。 裁减算法 主要包括:视域剔除(View Frustum Culling)、背面剔除(Back-Face Culling)、遮挡剔除(Occlusing Culling)和视口裁减等。在上面提到的裁剪是指背面剔除。遮挡剔除在下一个光栅化操作阶段进行。(下里巴人P27)
4) 可编程片段处理器
可编程片段处理器需要许多和可编程顶点处理器一样的数学操作,但是它们还支持纹理操作,纹理操作使得处理器可以通过一组纹理坐标存取纹理图像,然后返回一个纹理图像过滤的采样。(注意了,纹理在这个地方进行映射。假如没有编写着色器程序,也是在这里映射,只不过使用的是默认的着色器)
那什么是纹理过滤。大家可以参考这个链接,浅墨讲解了DX的四大纹理过滤http://blog.csdn.net/poem_qianmo/article/details/8567848。
浅墨的博客在我以前学习DX的时候给了我很大的帮助,大家可以多关注他的博客(认为是卖广告的请忽略)。
前面有讲到,可编程与固定渲染流水线的区别在于是否对着色器进行编程。第一个可能进行编程的地方在可编程顶点处理器,第二个可能进行编程的在可编程片段处理器这里。
可编程片段处理器,因为纹理操作等都在这里进行,所以假如我们希望我们的游戏非常绚丽,特效非常丰富,这部分需要我们投下很大的精力。不过因为我们今天是解释渲染流水线,所以在这个地方我们不做太多的解释。下面,我们了解一下其内部流程。

图 6
5) 光栅化操作
在前面,光栅化与可编程片段处理器会提供给我们片段以及一些相关的数据,比如片段的ALPHA,其深度等(片段的概念见前面,忘了可以认为是没有存在屏幕上的像素)。在这一步我们将会对其进行各种测试,而假如它通过了所有的测试,片段将会显示在屏幕上。

图 7
抖动显示:一种能够使用较少的颜色种类模拟较多颜色的显示模式。
在这个阶段,光栅器根据多边形的朝前或朝后来丢弃一些多边形(挑选culling)。光栅操作阶段将根据许多测试来检查每个片段,这些测试包括剪切,alpha,模板和 深度等测试。这些测试设计了片段最后的颜色或深度,像素的位置和一些像素值(例如像素的深度值和颜色值)。如果任何一项测试失败了,片段就会在这个阶段被丢弃,而更新像素的颜色值,虽然一个模板写入的操作也许会发生。通过了深度测试就可以用片段的深度值代替像素的深度值了。(CG,P14)
到这里为止,整个渲染流水线已经结束,最后附上CG教程里的一张图来结束今天的教程。
写博客的时候或许会出现一些问题,欢迎大家批评改正!
http://www.lexue163.com/v_377_lTloRxUeaNOv.html