【九度】抓取九度AC所有代码以及在CSDN的解题思路链接形成文件提交至github
前言
- 抓取在九度AC的所有代码。
- 抓取每个题目在CSDN解题思路的链接地址。
- 输出为多个Java/C++文件。
- 提交至github。
抓取九度代码
- 目前题目编号为1001至1557。
- 从该题目编号依次遍历url。
- url格式为:http://ac.jobdu.com/problem.php?pid=1000
- 即前缀加题目编号。
- 获取每个人的提交历史。
- url格式为:
http://ac.jobdu.com/status.php?pid=1000&user_id=wangzhenqing - 传递了两个参数,题目编号和用户名。
获取提交历史需要登陆,看了下登陆传递的参数。

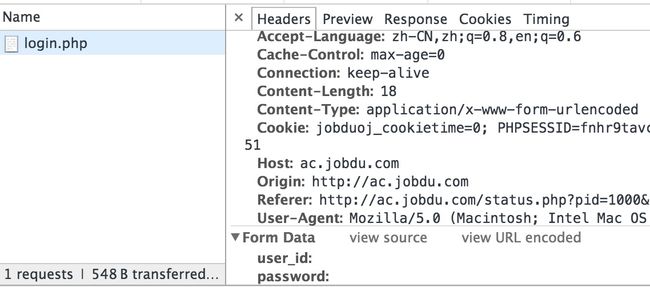
- 然后就是抓取过程。使用了Python的第三方依赖requests以及BeautifulSoup,具体代码如下:
# !/usr/bin/env python
# -*- coding: utf-8 -*-
# author: wangzhenqing - 这样就将文件抓取到了。
- 然后代码格式比较乱,没有说明,所以我又用Java对JavaAC代码进行了格式化。代码如下:
/**
* @author:wangzq
* @email:[email protected]
* @date:2015-06-30 11:01:54
* @description:将抓取的代码进行代码格式化
*/
import org.eclipse.jdt.core.JavaCore;
import org.eclipse.jdt.core.ToolFactory;
import org.eclipse.jdt.core.formatter.CodeFormatter;
import org.eclipse.jdt.core.formatter.DefaultCodeFormatterConstants;
import org.eclipse.jface.text.Document;
import org.eclipse.jface.text.IDocument;
import org.eclipse.text.edits.TextEdit;
import java.io.*;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Map;
public class JavaCodeFormatUtils {
/**
* 调用eclipse jdt core对生成的java源码进行格式化
* 尝试对传入的JavaSourceFile格式化,此操作若成功则将改变传入对象的内容
*
* @author pf-miles 2014-4-16 下午2:48:29
*/
@SuppressWarnings({"rawtypes", "unchecked"})
public static String reformatCode(String code, String fileName) {
String formatCode = "";
Map m = DefaultCodeFormatterConstants.getEclipseDefaultSettings();
m.put(JavaCore.COMPILER_COMPLIANCE, 1.6);
m.put(JavaCore.COMPILER_CODEGEN_TARGET_PLATFORM, 1.6);
m.put(JavaCore.COMPILER_SOURCE, 1.6);
m.put(DefaultCodeFormatterConstants.FORMATTER_LINE_SPLIT, "80");
m.put(DefaultCodeFormatterConstants.FORMATTER_TAB_CHAR,
JavaCore.SPACE);
IDocument doc = null;
try {
CodeFormatter codeFormatter = ToolFactory.createCodeFormatter(m);
TextEdit textEdit = codeFormatter.format(
CodeFormatter.K_UNKNOWN, code, 0, code.length(), 0, null);
if (textEdit != null) {
doc = new Document(code);
textEdit.apply(doc);
formatCode += doc.get() + "\n";
}
} catch (Exception e) {
System.err.println("格式化文件出错" + e);
e.printStackTrace();
}
if ("".equals(formatCode)) {
System.out.println(fileName);
return code;
}
return formatCode;
}
/**
* @param file
* @return
* @Description: 获取文件内容
* @date 2013-7-11,下午04:30:48
* @author wangzq
* @version 3.0.0
*/
public static String getFileCode(File file) {
String code = "";
try {
String encoding = "utf-8";
if (file.isFile() && file.exists()) { // 判断文件是否存在
InputStreamReader read = new InputStreamReader(
new FileInputStream(file), encoding);// 考虑到编码格式
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
while ((lineTxt = bufferedReader.readLine()) != null) {
code += lineTxt + "\n";
}
read.close();
} else {
System.err.println("找不到指定的文件");
}
} catch (Exception e) {
System.err.println("读取文件内容出错");
e.printStackTrace();
}
return code;
}
/**
* 获取目录下的所有文件。
*
* @param path
*/
public static void getDirectoryFiles(String path, String newPath) {
File dirFile = new File(path);
if (!dirFile.isDirectory()) {
System.err.println(path + "不是文件夹,请检查!");
}
File[] files = dirFile.listFiles();
int k = 0;
for (File file : files) { // 遍历文件
String fileName = file.getName();
String head = getCodeHead(fileName);
String code = getFileCode(file);
code = head + code;
code = reformatCode(code, fileName);
if ("".equals(code)) {
System.out.println(fileName);
}
// System.out.println(code);
writeCodeToFile(newPath + File.separator + fileName, code);
k++;
}
}
/**
* 将内容写入文件
*
* @param filePath
* @param code
*/
public static void writeCodeToFile(String filePath, String code) {
try {
File file = new File(filePath);
PrintStream ps = new PrintStream(new FileOutputStream(file));
ps.println(code);// 往文件里写入字符串
} catch (FileNotFoundException e) {
System.err.println("写文件内容出错");
e.printStackTrace();
}
}
/**
* 给每个文件增加文件头
*
* @param fileName
* @return
*/
public static String getCodeHead(String fileName) {
String probId = fileName.substring(2, 6);
String probName = fileName.substring(0, fileName.length() - 5);
SimpleDateFormat dateFormat = new
SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String head = "" + "\n";
head += "" + "\n";
head += "// " + probName + "\n";
head += "" + "\n";
head += "/**" + "\n";
head += " * @author:wangzq" + "\n";
head += " * @email:[email protected]" + "\n";
head += " * @date:" + dateFormat.format(new Date()) + "\n";
head += " * @url:http://ac.jobdu.com/problem.php?pid=" + probId + "\n";
head += " */" + "\n";
return head;
}
public static void main(String[] args) {
String path = "/Users/wangzhenqing/git_work/java/test";
String newPath = "/Users/wangzhenqing/git_work/java/new";
getDirectoryFiles(path, newPath);
}
}- 有一些因为代码的原因没有格式化成功,手动格式化即可。
抓取CSDN博客题目列表
- 然后我还不死心,我要抓取博客的题目列表,把解题思路的url加进去。
- 所以我抓取了CSDN的题目成为txt文档。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
# author: wangzhenqing - 然后用java解析生成的txt文件,并且把url加进去。其实可以用Python实现,不知道当时怎么想的。
/**
* @author:wangzq
* @email:[email protected]
* @date:2015-06-30 11:01:54
* @description:将抓取的代码进行代码格式化
*/
import java.io.*;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
public class JavaCodeUrlUtils {
private static Map articleMap =
new HashMap();
/**
* @param file
* @return
* @Description: 获取文件内容
* @date 2013-7-11,下午04:30:48
* @author wangzq
* @version 3.0.0
*/
public static String getFileCode(File file, String fileName) {
fileName = fileName.substring(0, fileName.length() - 5);
System.out.println(fileName);
if (fileName.equals("题目1040:Prime Number")) {
System.out.println(111);
}
String code = "";
try {
String encoding = "utf-8";
if (file.isFile() && file.exists()) { // 判断文件是否存在
InputStreamReader read = new InputStreamReader(
new FileInputStream(file), encoding);// 考虑到编码格式
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
while ((lineTxt = bufferedReader.readLine()) != null) {
code += lineTxt + "\n";
if (lineTxt.contains("@url:http://ac.jobdu.com/problem.php?pid")
&& articleMap.containsKey(fileName)) {
System.out.println(fileName);
code += " * 解题思路参考csdn:" + articleMap.get(fileName) + "\n";
}
}
read.close();
} else {
System.err.println("找不到指定的文件");
}
} catch (Exception e) {
System.err.println("读取文件内容出错");
e.printStackTrace();
}
return code;
}
/**
* 获取目录下的所有文件。
*
* @param path
*/
public static void getDirectoryFiles(String path, String newPath) {
File dirFile = new File(path);
if (!dirFile.isDirectory()) {
System.err.println(path + "不是文件夹,请检查!");
}
File[] files = dirFile.listFiles();
for (File file : files) {
String fileName = file.getName();
String code = getFileCode(file, fileName);
if ("".equals(code)) {
System.out.println(fileName);
}
// System.out.println(code);
writeCodeToFile(newPath + File.separator + fileName, code);
}
}
/**
* 将内容写入文件
*
* @param filePath
* @param code
*/
public static void writeCodeToFile(String filePath, String code) {
try {
File file = new File(filePath);
PrintStream ps = new PrintStream(new FileOutputStream(file));
ps.println(code);// 往文件里写入字符串
} catch (FileNotFoundException e) {
System.err.println("写文件内容出错");
e.printStackTrace();
}
}
/**
* @param filename
* @return
* @Description: 获取博客日志信息
* @date 2015-06-30 16:54:22
* @author wangzq
*/
public static void getCSDNArticles(String filename) {
File file = new File(filename);
try {
String encoding = "utf-8";
if (file.isFile() && file.exists()) { // 判断文件是否存在
InputStreamReader read = new InputStreamReader(
new FileInputStream(file), encoding);// 考虑到编码格式
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
while ((lineTxt = bufferedReader.readLine()) != null) {
lineTxt = lineTxt.trim();
String array[] = lineTxt.split(Pattern.quote("||"));
String head = "";
String url = array[1].trim();
if (array[0].contains("&&")) {
String headArr[] = array[0].split("&&");
for (int i = 0; i < headArr.length; i++) {
if (!headArr[i].contains("LeetCode")) {
head = headArr[i].replace("【九度】", "").trim();
articleMap.put(head, url);
}
}
} else if (array[0].contains("【九度】")) {
head = array[0].replace("【九度】", "").trim();
articleMap.put(head, url);
}
}
read.close();
} else {
System.err.println("找不到指定的文件");
}
} catch (Exception e) {
System.err.println("读取文件内容出错");
e.printStackTrace();
}
}
public static void main(String[] args) {
String path = "/Users/wangzhenqing/git_work/java/test";
String newPath = "/Users/wangzhenqing/git_work/java/new";
getCSDNArticles("/Users/wangzhenqing/git_work/java/1.txt");
System.out.println(articleMap.size());
for (String head : articleMap.keySet()) {
System.out.println(head);
System.out.println(articleMap.get(head));
}
System.out.println(articleMap.get("题目1040:Prime Number"));
getDirectoryFiles(path, newPath);
}
} - 然后就大功告成了。
- Jobdu的代码在https://github.com/wzqwsrf/Jobdu。
- 爬虫的代码在
https://github.com/wzqwsrf/python-demo/tree/master/jobdu。
遇到的问题
- 九度获取历史信息需要登陆,在用requests模拟浏览器登陆上耗费不少时间。
- Java代码格式化,研究了一下快捷键的源码,因为懒得手动去做。
- 抓取CSDN博客题目列表,好像每次只能抓到15个。所以我循环了22次。
- 不过总算是完成了,替我做了很多大量重复的无意义的工作。