高斯过程和机器学习2——高斯分类
高斯过程分类
对于分类问题,高斯过程就不那么简单。前面我们是可以得出似然函数,先验分布均为高斯得出后验也是高斯分布。这种在解析计算上有良好的驯良性。对于分类问题输出值y不是连续的而是离散的,自然p(y|D)不能用高斯分布,比如二分类问题y=0,1就服从伯努利分布。(这里是否可以考虑中间输出y’的先验分布为两个高斯分布的叠加,一个均值为1一个为0,类似于核密度估计然后再用sigmod函数映射为离散值(或者找一个期望决策值来看预测值与其相对大小)(即p(y|y’)似然函数?)这样纸的话似然函数仍然不是高斯分布啊,所以还是要对这一步决策函数做高斯近似?)
分类问题一般有两种,一种是概率生成方法(generative approach)一种是判别方法(discriminate approach).前者就是由贝叶斯法则得出后验 p ( y ∣ x ) = p ( x ∣ y ) p ( x ) ∑ c p ( C c ) p ( x ∣ C c ) p(y|x)=\frac{p(x|y)p(x)}{\sum_cp(C_c)p(x|C_c)} p(y∣x)=∑cp(Cc)p(x∣Cc)p(x∣y)p(x)比如直接假设类别的条件概率为正态分布即 p ( x ∣ C c ) = N ( μ c , σ c ) p(x|C_c)=N(\mu_c,\sigma_c) p(x∣Cc)=N(μc,σc)这是一种比较强的假设,不满足时效果可能很差。后者是直接对p(y|x)建模,比如对于二分类,我们自然想到先进性回归然后再由激活响应函数或者叫链接函数将(-inf,inf)挤压到变化锐利的[0,1]区间建模,比如传统【线性逻辑回归】里:
p ( C 1 ) = λ ( w T x ) , λ ( z ) = 1 / ( 1 + e x p − z ) p(C_1)=\lambda(w^Tx),\lambda(z)=1/(1+exp^{-z}) p(C1)=λ(wTx),λ(z)=1/(1+exp−z)
也可以采用【概率回归】 λ = Φ ( z ) = ∫ − ∞ z N ( z ∣ 0 , 1 ) \lambda=\Phi(z)=\int_{-\infty}^zN(z|0,1) λ=Φ(z)=∫−∞zN(z∣0,1)函数进行挤压。两者方法各有千秋,可能是参数模型也可能是非参数模型,比如最近邻原则,本章采用判别方法。
同样的在得到x y分布模型后,我们仍然需要决策函数来判断模型好坏,通常用损失函数Loss,他应当满足当类别被错分时函数值增加。一种例子就是【0-1损失函数】,正确分类为0错分值为1.注意损失函数可能不是对称的,比如经典的把癌症误诊为无病和无病的误诊为癌症损失代价是不对等的。那么我们做的就是最小化期望损失函数:
m i n : R i s k = ∑ c L ( c , c ′ ) p ( C c ∣ x ) = ∫ L ( y , c ( X ) ) p ( X , y ) d X d y min :Risk=\sum_cL(c,c')p(C_c|x)=\bm{\int L(y,c(X))p(X,y)dXdy} min:Risk=c∑L(c,c′)p(Cc∣x)=∫L(y,c(X))p(X,y)dXdy
线性分类模型
考虑线性二分类标签为(+1,-1),有 p ( y = + 1 ∣ x , w ) = σ ( x T w ) , σ p(y=+1|x,w)=\sigma(x^Tw),\sigma p(y=+1∣x,w)=σ(xTw),σ为sigmod函数,此为线性逻辑回归,当然我们也可以不用sigmod函数用上面说到的高斯分布的累计函数作为激活函数,就是线性概率回归。点(xi,yi)似然函数为:
p ( y i ∣ x i ) = { σ ( x i T w ) , i f y i = + 1 1 − σ ( x i T w ) , i f y i = − 1 p(yi|xi)=\begin{cases} \sigma(x_i^Tw),\quad if yi=+1\\ 1-\sigma(x_i^Tw), \quad if yi=-1 \end{cases} p(yi∣xi)={σ(xiTw),ifyi=+11−σ(xiTw),ifyi=−1
注意到 σ ( − z ) = 1 − σ ( z ) \sigma(-z)=1-\sigma(z) σ(−z)=1−σ(z),容易把似然函数写作 p ( y i ∣ x i , w ) = σ ( y i ∗ x i T w ) p(yi|xi,w)=\sigma(yi*x_i^Tw) p(yi∣xi,w)=σ(yi∗xiTw)
定义logit(x)=log(p(y=+1|x)/p(y=-1|x)),称之为log odds ratio
在贝叶斯线性回归里我们有先验 w ∼ N ( 0 , σ p ) w\sim N(0,\sigma_p) w∼N(0,σp)我们可以由贝叶斯规则,得到未归一化的对数后验:
p ( w ∣ X , y ) ∝ p ( w ) Π i n p ( y i ∣ w , x i ) l o g ( p ( w ∣ X , y ) ⋍ − 1 2 w T σ p − 1 w + ∑ i n l o g σ ( y i ∗ x i T w ) p(w|X,y)\varpropto p(w)\Pi_i^np(y_i|w,x_i)\\ log(p(w|X,y)\backsimeq -\frac{1}{2}w^T\sigma_p^{-1}w+\sum_i^nlog\sigma(yi*x_i^Tw) p(w∣X,y)∝p(w)Πinp(yi∣w,xi)log(p(w∣X,y)⋍−21wTσp−1w+i∑nlogσ(yi∗xiTw)
如果只用最大似然函数进行参数估计,那么|w|会变得无限大而且容易过拟合,所以这里上面我用的最大后验法,而注意到上式最大对数后验的时候就包含了了正则惩罚项 w T σ p − 1 w w^T\sigma_p^{-1}w wTσp−1w。原文还给了图示例最大后验对于线性不可分时的效果图,意在表明这种正则化估计可以不用过拟合,也就是会过滤掉极少的异常点(线性不可分),这里略去。上面对数后验凸函数,容易得到极大值,一般采用IRLS迭代权值最小二乘法,也有文献指出用共轭梯度会更快。
参数模型确定好后就是预测了:
![]()
对于多分类问题引入softmax,似然函数为:
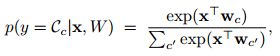
对应的对数似然函数(为什么都要取对数,这里就不赘述了):
∑ i = 1 n ∑ c = 1 C δ c , y i [ x i T w c − l o g ( ∑ c ′ e x p ( x i T w c ′ ) ) ] \sum_{i=1}^n\sum_{c=1}^C\delta_{c,yi}[x_i^Tw_c-log(\sum_{c'}exp(x_i^Tw_{c'}))] i=1∑nc=1∑Cδc,yi[xiTwc−log(c′∑exp(xiTwc′))]
高斯过程分类
如上所述,要用到高斯过程回归,我们需要找个潜在回归函数,然后将其挤压到小的区间产生分类输出:
π ( x ) = p ( y = + 1 ∣ x ) = σ ( f ( x ) ) \pi(x)=p(y=+1|x)=\sigma(f(x)) π(x)=p(y=+1∣x)=σ(f(x)),当然遗憾的是我们无法观测潜在函数f的值,我们只有分类结果的离散值y。这么写出来f仅仅是数学解析分析需要,我们后面会看到他会被积分消去。
有个练习题可以看到,我们的无噪声的似然函数 p ( y ∣ f ) = σ ( f ) p(y|f)=\sigma(f) p(y∣f)=σ(f)是光滑的等价于独立的噪声加上一个阶跃激活似然函数。预测分布:
p ( y ∗ ∣ X , y , x ∗ ) = ∫ p ( y ∗ ∣ X , f , x ∗ ) p ( f ∣ X , y ) d f \bm{p(y_*|X,y,x_*)=\int p(y_*|X,f,x_*)p(f|X,y)df } p(y∗∣X,y,x∗)=∫p(y∗∣X,f,x∗)p(f∣X,y)df
there,posterior is given by bayes rule: p ( f ∣ X , y ) = p ( y ∣ f ) p ( f ∣ X ) / p ( y ∣ X ) \bm{p(f|X,y)=p(y|f)p(f|X)/p(y|X)} p(f∣X,y)=p(y∣f)p(f∣X)/p(y∣X)
期望预测输出概率:
π ( x ) = p ( y = + 1 ∣ X , y , x ∗ ) = ∫ σ ( f ∗ ) p ( f ∗ ∣ X , y , x ∗ ) d f ∗ \pi(x)=p(y=+1|X,y,x_*)=\int \sigma(f_*)p(f_*|X,y,x_*)df_* π(x)=p(y=+1∣X,y,x∗)=∫σ(f∗)p(f∗∣X,y,x∗)df∗
上式中的似然函数p(y*|f*)即sigmod函数包含在积分中,不好解析。上上式子中似然函数P(f|X,y)也不是高斯的(注意p(f)先验我们是假设为高斯分布N(0,K))。因此需要做数值近似处理。比如拉普拉斯近似,EP期望传播方法
拉普拉斯近似(二分类)
后验的高斯近似形式为q q ( f ∣ X , y ) = N ( f ∣ f ^ , A − 1 ) ∝ e x p ( − 1 / 2 ( f − f ^ ) T ) A − 1 ( f − f ^ ) \bm{q(f|X,y)=N(f|\hat f,A^{-1})\varpropto exp(-1/2(f-\hat f)^T)A^{-1}(f-\hat f)} q(f∣X,y)=N(f∣f^,A−1)∝exp(−1/2(f−f^)T)A−1(f−f^) equation1
其中 f ^ = a r g m a x f p ( f ∣ X , y ) , A = − ▽ f 2 p ( f ∣ X , y ) ∣ f = f ^ \bm{\hat f=argmax_f p(f|X,y), A=-\triangledown_f^2p(f|X,y)|_{f=\hat f}} f^=argmaxfp(f∣X,y),A=−▽f2p(f∣X,y)∣f=f^
同上面,高斯先验为: p ( f ) = p ( f ∣ X ) ∼ N ( 0 , K ) p(f)=p(f|X)\sim N(0,K) p(f)=p(f∣X)∼N(0,K)这和之前的贝叶斯线性回归2.29式子 y = f + ϵ y=f+\epsilon y=f+ϵ这里是 y = σ ( f ) y=\sigma(f) y=σ(f)是相似的.f都是潜在函数变量,服从先验高斯分布。
为避免本章的似然、后验和先验的混淆以及贝叶斯规则的颠倒和记号误解。这里强调一下(x,y)才是数据集和样本,光x是相当于无条件已知的,所以X一直出现在条件概率“|”右边条件项,记号p(?|x)=p(?)是等价的表明依存关系。都是单变量的先验。只有当|右边出现(x,y)是才是后验的意思。贝叶斯表明一种“因果互换”的味道,所以后验也可能是先验,似然更多的表明是一种依赖概率关系比如x->y,y->z所以不用太过纠结根据具体情况来划分。
接下来我们针对主要目标式equation1做几个工作:1、如何求 f ^ , A \hat f,A f^,A ? 2、如何预测?3、程序实现细节
posterior
注意到前面的 p ( f ∣ X , y ) = p ( y ∣ f ) p ( f ∣ X ) / p ( y ∣ X ) \bm{p(f|X,y)=p(y|f)p(f|X)/p(y|X)} p(f∣X,y)=p(y∣f)p(f∣X)/p(y∣X)分母一项是与f无关的,所以可以仿造GPR似然估计参数一样得到:
Φ ( f ) = l o g p ( y ∣ f ) + l o g p ( f ∣ X ) = l o g p ( y ∣ f ) − 1 2 f T K − 1 f − 0.5 l o g ∣ K ∣ − 0.5 n l o g ( 2 π ) \Phi(f)=logp(y|f)+logp(f|X)\\ =logp(y|f)-\frac{1}{2}f^TK^{-1}f-0.5log|K|-0.5nlog(2\pi) Φ(f)=logp(y∣f)+logp(f∣X)=logp(y∣f)−21fTK−1f−0.5log∣K∣−0.5nlog(2π)
其中K,就是之前一章所说的高斯回归的方差矩阵,对f求导得:
▽ Φ = ▽ p ( y ∣ f ) − K − 1 f ▽ 2 Φ = ▽ 2 p ( y ∣ f ) − K − 1 = − W − K − 1 \triangledown\Phi=\triangledown p(y|f)-K^{-1}f\\ \triangledown^2\Phi=\triangledown^2p(y|f)-K^{-1}=-W-K^{-1} ▽Φ=▽p(y∣f)−K−1f▽2Φ=▽2p(y∣f)−K−1=−W−K−1
上式二阶求导项W是对角矩阵(因为yi仅取决于fi),注意到如果p(y|f)是凹的,W非负,Hessian矩阵就是负定的,所 Φ ( f ) \Phi(f) Φ(f)似然函数极大值也是唯一确定的。
另外注意,似然函数是针对n个数据集的也就是说上面式子中X,y,f都是n维的,我们列出分别求导表格式子(也就是对应的nn矩阵 W的每一项(对角矩阵),grad_log p(y|f)是n维向量,各分量为 d l o g p ( y i ∣ f i ) d f i \frac{dlogp(yi|fi)}{dfi} dfidlogp(yi∣fi)):

其中 π i = p ( y i = + 1 ∣ f i ) , t = ( y + 1 ) / 2 \pi_i=p(yi=+1|fi),\bm{t=(y+1)/2} πi=p(yi=+1∣fi),t=(y+1)/2,那么求极值,令导数为0:
▽ Φ = 0 − > f ^ = K ( ▽ l o g p ( y ∣ f ^ ) ) \triangledown\Phi=0 ->\bm{\hat f=K(\triangledown logp(y|\hat f))} ▽Φ=0−>f^=K(▽logp(y∣f^))
由于其中的梯度一项是非线性的,不好求解我们采用梯度迭代求解该非线性方程得到:

用分块矩阵的方式对其进行拆分:

k21意思是n2n1的矩阵,K的分块矩阵一块。f1对应着n1个不好解释的数据,f2对应着线性预测(很像GPR把f2看作测试点),当f2的值导致预测不准的时候该点在下次迭代将被视为不可解释点。n=n1+n2. f为n行一列向量。
再看之前的后验的高斯近似equation1KaTeX parse error: Expected 'EOF', got '}' at position 41: …,y)|_{f=\hat f}}̲所以这里对应 A = K − 1 + W A=K^{-1}+W A=K−1+W所以迭代求解完成后,高斯近似的后验分布为:
q ( f ∣ X , y ) = N ( f ∣ f ^ , ( K − 1 + W ) − 1 ) \bm{q(f|X,y)=N(f|\hat f,(K^{-1}+W)^{-1})} q(f∣X,y)=N(f∣f^,(K−1+W)−1)
由于有海塞矩阵预测的f*不可控,这样近似得到的后验可能不准确,分布椭圆形。
predict
正如GPR一样,在得到似然函数p(y|X)分布后,我们会预测(条件分布)p(y*|y,x*)分布即均值和方差。
这里GPC,上面我们得到近似的高斯后验q(f|X,y)后进行预测f(x*),也是同样的认为f和f服从联合分布得到条件预测p(f|f)。可以看到这里高斯后验q(f)在预测的时候就变成了f*的似然函数.所以我说后验和似然是相对的,要充分理解。
高斯回归预测f*
由于潜在隐藏函数变量f是可以高斯回归得到的, q ( f ∗ ∣ f , X , y ) = p ( f ∣ X , y , f ∗ ) p ( f ∗ ) / p ( f ) q(f_*|f,X,y)=p(f|X,y,f_*)p(f_*)/p(f) q(f∗∣f,X,y)=p(f∣X,y,f∗)p(f∗)/p(f)高斯回归一样,我们直接由GPR得到:
f ∗ = k ( x ∗ ) T K − 1 f f_*=k(x_*)^TK^{-1}f f∗=k(x∗)TK−1f都服从高斯分布,两边去期望得到 E ( f ∗ ) = k ( x ∗ ) T K − 1 E ( f ) = k ( x ∗ ) T K − 1 f ^ E(f_*)=k(x_*)^TK^{-1}E(f)=k(x_*)^TK^{-1}\hat f E(f∗)=k(x∗)TK−1E(f)=k(x∗)TK−1f^
前面得到 f ^ = K ( ▽ l o g p ( y ∣ f ^ ) ) \bm{\hat f=K(\triangledown logp(y|\hat f))} f^=K(▽logp(y∣f^)) equation2
从而 E ( f ∗ ) = k ( x ∗ ) T ▽ l o g p ( y ∣ f ^ ) E(f_*)=k(x_*)^T\triangledown logp(y|\hat f) E(f∗)=k(x∗)T▽logp(y∣f^),这就是预测的均值期望 μ f ∗ \mu_{f*} μf∗
如果前面不进行高斯近似处理我们得到真正的解析期望如下:
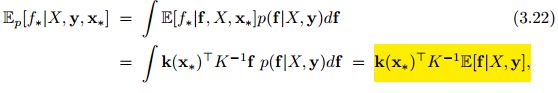
可以看到,两者形式相同,我们是用近似高斯分布的q(f|X,y)的期望代替了真实的期望E[f|X,y].
对于式子equation2我可以看到,预测的线性组合中正面例子也就是 ▽ i l o g p ( y i ∣ f i ) \triangledown_ilogp(yi|fi) ▽ilogp(yi∣fi)大于0的数据会产生正的系数加,反之产生负的系数。明显正例会让f更偏向想与正分类,负例会让f预测分类倾向于负类。注意到当这个梯度约为0时,也就是前面所说属于n2数据集的可解释数据点,系数为0,表明改样本点对预测不起作用,这和支持向量机SVM非常相像。
因为 q ( f ∗ ∣ x ∗ , X , y ) = p ( f ∣ X , f , x ∗ ) q ( f ∣ X , y ) q(f_*|x_*,X,y)=p(f|X,f,x_*)q(f|X,y) q(f∗∣x∗,X,y)=p(f∣X,f,x∗)q(f∣X,y)q表示是近似高斯。我们已可以得到预测方差为:
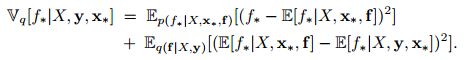
第一项是f*关于某值f的条件分布的方差,等同之前的高斯回归所以可以直接得到该项的方差为:
k ∗ ∗ − k ∗ T K − 1 k ∗ k_{**}-k_*^TK^{-1}k_* k∗∗−k∗TK−1k∗
第二项是由于 E ( f ∗ ) = k ( x ∗ ) T K − 1 f E(f_*)=k(x_*)^TK^{-1}f E(f∗)=k(x∗)TK−1f取决于f,而由于f高斯近似所带来的附加方差(误差),为:
k ∗ T K − 1 c o v ( f ∣ X , y ) K − 1 k ∗ k_*^TK^{-1}cov(f|X,y)K^{-1}k_* k∗TK−1cov(f∣X,y)K−1k∗其中 c o v ( f ∣ X , y ) = ( W + K − 1 ) − 1 cov(f|X,y)=(W+K^{-1})^{-1} cov(f∣X,y)=(W+K−1)−1
两个式子加起来得到:
Σ q ( f ∗ ) = k ∗ ∗ − k ∗ T ( W + K − 1 ) − 1 k ∗ \Sigma_{q(f*)}=k_{**}-k_*^T(W+K^{-1})^{-1}k_* Σq(f∗)=k∗∗−k∗T(W+K−1)−1k∗很像之前的GPR的结果形式。
我们得到预测分布; q ( f ∗ ∣ X , y , x ∗ ) ∼ N ( E ( f ∗ ) , Σ q ( f ∗ ) ) q(f*|X,y,x*)\sim N(E(f_*),\Sigma_{q(f*)}) q(f∗∣X,y,x∗)∼N(E(f∗),Σq(f∗))
由f*得到预测分类
那么在潜在分布基础上我们得到分类预测,就是:
y ∗ = π ( x ∗ ) = E ( σ ( f ∗ ) ) = ∫ σ ( f ∗ ) q ( f ∗ ∣ X , y , x ∗ ) d f ∗ y*=\pi(x*)=E(\sigma(f*))=\int\sigma(f*)q(f*|X,y,x*)df* y∗=π(x∗)=E(σ(f∗))=∫σ(f∗)q(f∗∣X,y,x∗)df∗
注意上面的最终分类预测是取分类结果概率分布的期望而非是取期望结果的分类也就是 σ ( E ( q ( f ∗ ∣ X , y , x ∗ ) ) ) \sigma(E(q(f*|X,y,x*))) σ(E(q(f∗∣X,y,x∗)))两者是有不同的。前者我们称之为均值预测后者我们称为MAP预测 Bishop指出对于二分类按照概率较高的方式分类的话两者结果完全相同。
如果只是取概率较高来分类的话我们没必要求解上式的积分,但我们往往需要得到分类的确信也就是分布,这样在做拒绝项的才有依据。因此我们有很多中近似的方法得到上面的积分式。比如取激活函数sigmod函数为高斯累积函数而不是logstic函数的上式驯良可以直接积分出解析式。反之,我们则需要进行采样和近似的方法求解一维积分。注意到激活函数 σ ( z ) \sigma(z) σ(z)是 p ( z ) = s e c h 2 ( z / 2 ) / 4 p(z)=sech^2(z/2)/4 p(z)=sech2(z/2)/4的cdf,也就是p(z)看作混合高斯分布,激活函数就是误差函数的线性组合可进行近似。还有一种近似 π ( x ∗ ) = λ ( k ( f ∗ ∣ y ) f ∗ ˉ ) , k ( f ∗ ∣ y ) = 8 / ( 1 + π Σ q ∗ ) \pi(x*)=\lambda(k(f*|y)\bar{f*}),k(f*|y)=8/(1+\pi\Sigma_{q*}) π(x∗)=λ(k(f∗∣y)f∗ˉ),k(f∗∣y)=8/(1+πΣq∗)等等详见文献
implementation
实现过程我们主要关注一些数值稳定和减少计算量。预测分类算法如下:
f的预测:

其中B的特征值是限制在1和1+max(Kij)/4之间因此可以chol分解。保证其有很好的条件数,可逆。
其中B的计算O(n^2),chol分解=牛顿迭代次数* O ( n 3 / 6 ) O(n^3/6) O(n3/6)
4-8行是牛顿迭代求解f
算法将计算转化为: ( w + k − 1 ) − 1 = K − K W 1 / 2 B − 1 W 1 / 2 K (w+k^{-1})^{-1}=K-KW^{1/2}B^{-1}W^{1/2}K (w+k−1)−1=K−KW1/2B−1W1/2K
这样可以防止左边K不可逆。
由于: ( w − 1 + k ) − 1 = W 1 / 2 B − 1 W 1 / 2 (w^{-1}+k)^{-1}=W^{1/2}B^{-1}W^{1/2} (w−1+k)−1=W1/2B−1W1/2
这样也能防止W不可逆,并且可以很好的计算q(f*|y)的方差:
D ( q ( f ∗ ∣ y ) ) = k ∗ ∗ − V T V , w h e r e V = L \ W 1 / 2 k ( x ∗ ) \bm{D(q(f*|y))=k_{**}-V^TV},where \bm{V=L\backslash W^{1/2}k(x*)} D(q(f∗∣y))=k∗∗−VTV,whereV=L\W1/2k(x∗)
第10行最后是计算det(B)转化为L的对角元素求和。见chol分解相关知识。
根据f预测分类:

另外K有的时候还是会转化为KaTeX parse error: Expected 'EOF', got '\epsilonI' at position 3: K+\̲e̲p̲s̲i̲l̲o̲n̲I̲来提高数值稳定。
边缘似然分布
计算边缘似然分布p(y|X)会有用处,比如优化超参数??
p ( y ∣ X ) = ∫ p ( y ∣ f ) p ( f ∣ X ) d f = ∫ e x p ( Φ ( f ) ) d f p(y|X)=\int p(y|f)p(f|X)df=\int exp(\Phi(f))df p(y∣X)=∫p(y∣f)p(f∣X)df=∫exp(Φ(f))df
泰勒展开 Φ ( f ) = Φ ( f ^ ) − 1 2 ( f − f ^ ) T A ( f − f ^ ) \Phi(f)=\Phi(\hat f)-\frac{1}{2}(f-\hat f)^TA(f-\hat f) Φ(f)=Φ(f^)−21(f−f^)TA(f−f^)所以可以近似得到:
p ( y ∣ X ) = q ( y ∣ X ) = e x p ( Φ ( f ^ ) ) ∫ e x p ( − 1 2 ( f − f ^ ) T A ( f − f ^ ) ) d f p(y|X)=q(y|X)=exp(\Phi(\hat f))\int exp(-\frac{1}{2}(f-\hat f)^TA(f-\hat f))df p(y∣X)=q(y∣X)=exp(Φ(f^))∫exp(−21(f−f^)TA(f−f^))df
上式可以解析计算,因此可以用作近似下面式子的值
l o g p ( y ∣ X , θ ) = − 1 / 2 f ^ T K − 1 f ^ + l o g p ( y ∣ f ^ ) − 0.5 l o g ∣ B ∣ logp(y|X,\theta)=-1/2\hat f^TK^{-1}\hat f+logp(y|\hat f)-0.5log|B| logp(y∣X,θ)=−1/2f^TK−1f^+logp(y∣f^)−0.5log∣B∣
相关符号上面都有给出。