决策树相关算法——Boosting之Adaboost&GBDT详细说明与实现
前言
本篇博客主要记录的是集成学习中的Boosting提升算法的相关实现,主要分为以下四个部分,Boosting的提出,Boosting经典算法Adaboost的分析与实现,Adaboost算法的特例提升树的分析,梯度提升算法GBDT的提出原因及分析。
Github实现代码地址
补充:对于机器学习类的算法,一般包括三个部分:算法模型(即定义的预测的输出表达式一般有逻辑回归、线性回归、SVM、神经网络)、损失函数(即数据真实的分布和按照算法模型预测的数据分布间的差异,一般有最小二乘法、极大似然、交叉熵),学习算法(即求解算法模型中的未知参数的方法,一般有梯度下降法、前向分步算法等迭代求解算法)
1.Boosting 的提出
Boosting作为一种统计学习方法,学习一系列弱分类器,并将它们线性组合为一个强分类器。
Boosting的一般方式为:
1.根据初始训练数据集训练出基分类器。
2.根据基分类器上的表现上(误差)上,调整训练集的样本权重——使之前分错的样本更受分类器关注,然后再对调整后的训练集样本和前几个分类器加权累加组合进行训练得到下一个分类器。
3.如此重复学习出M个分类器,最后的组合分类器便是由这M个分类器加权累加组成。
1.1Boosting(提升)方法需要解决的两个问题:
1.每一轮训练,如何改变训练数据的权值和概率分布
2.如何将学习的多个弱分类器进行组合成一个强分类器
接下来主要是提升方法的几个示例算法Adaboost、提升树、GBDT梯度提升树
2.Boosting经典算法Adaboost的分析与实现
2.1Adaboost的引入
问题: Adaboost如何解决提升方法的两个问题
解释: 对于问题1,提高前一轮训练中错误分类的的样本的权重,而降低哪些被正确分类样本的权重;对于问题2,加权多数表决的方法,加大分类误差率小的弱分类器的权重,减少分类误差率大的弱分类器的权重。
2.2Adaboost的分析
Adaboost的分析将按照机器学习的算法来分析,包括三个部分:算法模型——线性组合的加法模型f(x)、代价函数L(y,f(x))、学习算法——前向分步算法。
2.2.1Adaboost算法模型
线性组合的加法模型f(x)
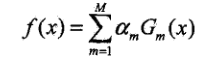
最终预测表达式
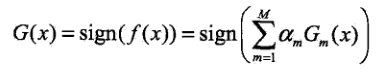
图中参数说明: Gm(x)表示弱分类器,这里表示阈值分类器即x
前面为弱分类器的权重。
2.2.2Adaboost代价函数的缘由
此处详细分析,首先展示出代价函数的公式:
![]()
分析1: 接下来进行推理,最终的训练数据集上的分类误差率可以表示为,其中I函数表示指示函数,也可以理解为特征函数当存在G(xi)!=yi时为1,否则为0:
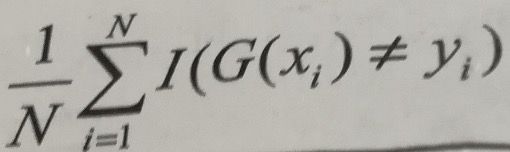
分析2: 要想使得该误差率最小,可以使得它的变相的上界最小即,当G(xi)!=yi时,yif(xi)<0,所以exp(-yif(xi))>=1可以推出下面不等式的左半部分,右半部分可以参考书上资料。
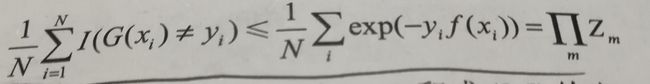
分析3:其中Zm表示为如下,由公式可以得出Zm>0,所以要使得上式右半部分极小,需要使得不相干的Zm每个极小即可求解出参数,要使得Zm最小需要选取合适的Gm。看Zm的表达式可以得出Zm只与第m轮的系数该系数表示分类器的权重是大于0的和分类器Gm有关,所以得出不相干的Zm:
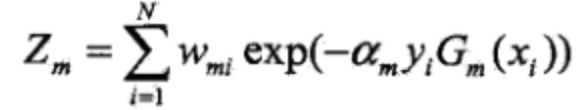
总结:根据上面分析,可以得出为什么Adaboost的代价函数是指数函数。
2.2.3Adaboost学习算法——代价函数为指数函数的前向分步算法
一、对前向分步算法的介绍
说明1: 前向分步算法用于求解加法模型的参数。加法模型的一般表达方式为如下,其中,b(x; rm)为基函数,rm是基函数的参数,βm为基函数的系数。
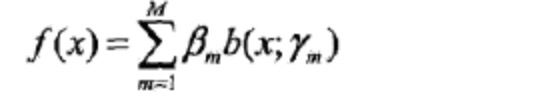
说明2: 对于加法模型,在给定训练数据及损失函数L(y,f(x))的条件下,学习加法模型f(x)的参数就成为经验风险极小化损失函数极小化问题。(Adaboost的算法模型即为加法模型,代价函数为指数函数——上面一节已经表述原因)
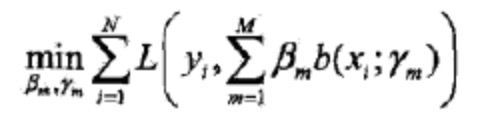
二、前向分步算法是如何根据代价函数求解出Adaboost加法模型的参数
前向分步算法求解的思想是: 因为要学习的一个算法模型是线性加法模式的,如果能从前向后,每一步只学习一个基函数的参数和其对应的系数,逐步逼近代价函数,那么就可以简化计算上面的加法模型的代价函数的代价,每一步只需要计算如下一小步代价函数即可:
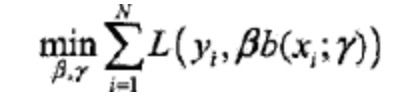
具体完整的前向分步算法过程截取网上的图片如下:

前向分步算法在Adaboost求解参数的过程
Adaboost加法模型为:
Adaboost代价函数为:
![]()
过程1: 假设经过m-1次步后的前向分步算法后得到了fm-1(x),有:
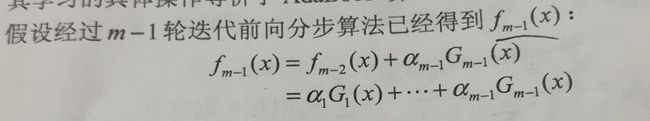
过程2: 此时的目标是根据第m步的前向分步算法计算出参数am,Gm(x),fm(x),其中fm(x)的表达式为:
![]()
此时的求解参数的等式可以表示为:
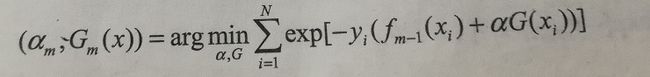
进一步化简:
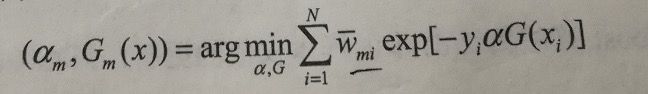
说明: 最小化上式即可求解出am,Gm(x),其中Wmi=exp[-yi*fm-1(xi)]与am和Gm不相干,所以与上式的最小化没有关系。
过程3: 因为am表示弱分类器的权重,所以大于0,所以推出必须使得Gm的分类误差率最小。分别对am,em求偏导等于0。得出:
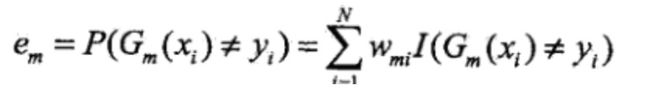
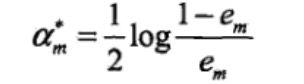
2.3实现一个基于阈值分类器的Adaboost算法
实验部分: 本实验的基函数为阈值分类器,数据集为Adult,属于二分类问题。上篇博客已经对数据集进行了数值处理,详细处理后的数据集可以在GitHub上下载。
Step1定义整个算法的计算步骤
flods = [train_file, test_file]
print('load data...')
from ML.DecisionTree import decision_tree as dt
train_x, train_y, test_x, test_y = dt.load_data(flods)
print('finish data load...')
start_time = time.time()
#
adboost = AdaBoostBasic(M = 15)
adboost.train(train_x,train_y)
end_time = time.time()
train_time = end_time - start_time
print('total train time is :%.3f'%train_time)
pred_y = []
for sample in test_x:
pred_yi = adboost.predict(sample)
pred_y.append(pred_yi)
Step2定义Adaboost的训练步骤,即前向分步算法的学习过程
def train(self,train_x,train_y):
self._init_parameters_(train_x,train_y)
#计算M个弱分类器
for iter in range(self.M):
print('start %d ThresholdClass ...'%(iter))
#对于多维度的分类,需要计算特定的维度的最好的分类器即误差率最小
# 分别对应的误差率,特征index,分类器对象
best_ThresholdClass = (1,None,None)
#从多维度的数据中找出维度对应的误差最小的特征及对应的分类器
for feature_index in range(self.feature_num):
#取feature对应的列,作为单维特征
feature_X = self.X[:,feature_index]
thresholdClass = ThresholdClass(feature_X,self.y,self.w)
error_rate = thresholdClass.train()
if error_rate < best_ThresholdClass[0]:
best_ThresholdClass = (error_rate,feature_index,thresholdClass)
error_rate_iter = best_ThresholdClass[0]
print('No %d ThresholdClass error rate is : %f , feature index is :%d'% (iter,best_ThresholdClass[0],best_ThresholdClass[1]))
#记录下第iter轮的分类器
self.classifier.append(best_ThresholdClass)
# 记录下参数alpha
alpha_iter = 100
if error_rate_iter == 1.1:
#没有分错的情况
self.alpha.append(alpha_iter)
else:
alpha_iter = self._get_alpha(error_rate_iter)
self.alpha.append(alpha_iter)
#更新训练集记录的权值分布
Zm = self._get_Z_m(alpha_iter,best_ThresholdClass[1],best_ThresholdClass[2])
self._updata_w(alpha_iter,best_ThresholdClass[1],best_ThresholdClass[2],Zm)
Step3定义Adaboost的基分类器
class ThresholdClass():
"""
构造一个阈值分类器
x= -1 ,val = 0
Adult是二分类问题,当阈值分类器输出val为1表示预测为正例,当阈值分类器输出val为0表示预测为负例
"""
def __init__(self,train_x,train_y,w):
"""
初始化阈值分类器
:param features: 特征集
:param labels:标签集
:param w: 样本对应的权重
"""
self.X = train_x
self.y = train_y
self.sample_num = train_x.shape[0]
#每个样本对应的参数
self.w = w
#初始化 feature取值的阈值范围
self.values = self._get_V_list(self.X)
self.best_V = -1
def train(self):
"""
计算使得分类误差率最小的阈值
:return: 返回误差率
"""
best_error_rate = 1.1
error_rate = 0.0
for V in self.values:
#计算每个阈值对应的误差率
for feature_v_index in range(self.sample_num):
val = 0
if self.X[feature_v_index] < V:
val = 1
# error 出现的情况
if val != self.y[feature_v_index]:
error_rate = error_rate + self.w[feature_v_index] * 1
if error_rate != 0.0 and error_rate < best_error_rate:
best_error_rate = error_rate
self.best_V = V
#没有error的情况
if best_error_rate == 1.1:
self.best_V = V
return best_error_rate
def predict(self,feature_value):
"""
:param feature_value:单个维度的值
:return:预测值
"""
if feature_value < self.best_V:
return 1
else:
return 0
def _get_V_list(self,X):
"""
:param X:特征对应的取值
:return:该特征对应的阈值可取值列表
"""
values_set = set(X)
values = []
for iter,value in enumerate(values_set):
if iter==0:
continue
else:
values.append(value-0.5)
return values
代码实现结论和感悟
1.如果样本的特征有n维,我们针对每一维特征求一个分类器,选取这些分类器中分类误差率最低的分类器作为本轮的分类器,将其特征index与分类器一起存入G(x)中。
2.一般来说对于算法模型的类的封装,类的属性变量为算法模型的参数,模型参数的求解为函数train的过程,对于耗时的train的过程需要使用C代码来求解模型参数,求解结束后python再调用C代码求解的参数结果
2.4多分类Adaboost思路
2.3中的实验求解的算法模型是属于2分类多特征的算法模型。对于多分类的算法模型如何用Adaboost求解尼???
思路一:加法模型的基分类器为多分类器,计算出使得误差率最小的基分类器及其系数,再线性组合成最终的分类器。
思路二:加法模型的基分类器为多分类器,但输出的是每个类别的概率,所有类别的概率加起来的值为1.参考Adaboost.M2算法。
3.Adaboost算法的特例提升树的分析
前面提到的经典Adaboost的弱分类器一般是阈值分类器,当以决策树为弱分类器的提升方法则为提升树。一般是以CART树为基函数,因为CART既可以做到分类预测,也可以做到回归预测。不过此时的CART树是一个决策树桩即只有一个根结点和两个叶子结点。
3.1分类问题的提升树
对于分类问题的提升树,基函数为决策树桩,其实就是上面例子中实现的阈值函数,实现的过程主要是参见2.3,它的代价函数是指数函数,对于分类问题的代价函数为什么是指数函数可以参见2.2.2。
3.2回归问题的提升树
对于回归问题的提升树,基函数为回归决策树桩,但是对于回归问题,此时的代价函数并不是指数函数,而是平方损失。但是对于提升方法的机器学习算法还是三个部分,算法模型——加法模型,学习方法——前向分步算法,代价函数——平方损失。
3.2.1回归问题的提升树的算法模型
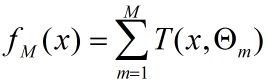
其中基函数可以表示为:
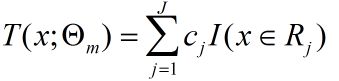
其中I表示指示函数,意思为当x位于Rj的区域则该值为1,输出Rj区域对应的回归值Cj。
3.2.2回归问题的提升树的代价函数
一般来说,对于回归问题的代价函数使用平方损失函数为:
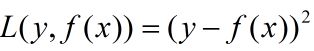
3.2.3回归问题的提升树的学习方法
思想核心:分步学习每一个阶段的参数,假设已经学习到第m步,有下面式子,其中fm-1(x)为已经求解的。
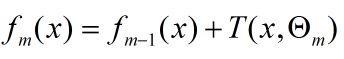
要优化的式子为:
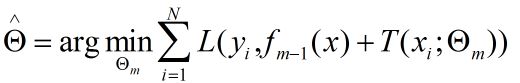
根据代价函数和上面的式子可求出:
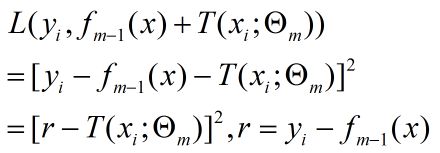
结论:为了使上式极小化,所以需要寻找一个回归树T(x),使它的值为r,即拟合r,根据r的公式可知,r为数据样本的残差。
4.梯度提升算法GBDT的提出原因及分析
4.1梯度提升,梯度的概念
梯度是一个向量,即有方向有大小;
梯度的方向是最大方向导数的方向;
梯度的值是最大方向导数的值。
4.2引入梯度提升算法GBDT的原因
我们知道,对于提升方法中的加法模型的参数求解一般使用前向分步算法求解,如分类提升树它的代价函数是指数函数,至于为什么是指数函数,前面2.2.2有相关介绍,回归提升树它的代价函数是平方损失。对于指数函数和平方损失使用前向分步算法,分步学习每一个阶段的基函数的参数是可以简单做到的。但如果基函数不是决策树或者阈值分类器时,那么它的代价函数则不是指数函数或者平方损失,是其他损失函数Hige loss,log loss等,此时每一个阶段的优化并不容易。为什么会优化不容易??:
首先明确每一步要优化的公式,假设第m步要优化的式子为:
此时,T(x)并不一定表示回归树,表示任意的一个假设函数——基函数,此时L为代价函数为一般函数(不是指数函数和平方损失),假设此时为损失函数为log损失函数:
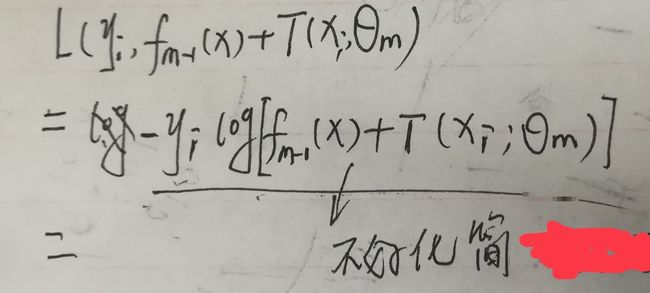
所以此时需要另找其他方法,解决任何损失函数不容易极小化来求前向分步中第m步的参数的问题。
GBDT如何解决上述问题
此时GBDT的方法是:提出用损失函数的负梯度在第m-1步模型的值作为m-1步算法模型预测与样本之间的残差值得近视,从而第m步只需拟合该负梯度值即可。
为什么GBDT能达到优化代价函数,从而求解出当前第m步基函数模型参数的效果尼???
具体分析过程如下图:
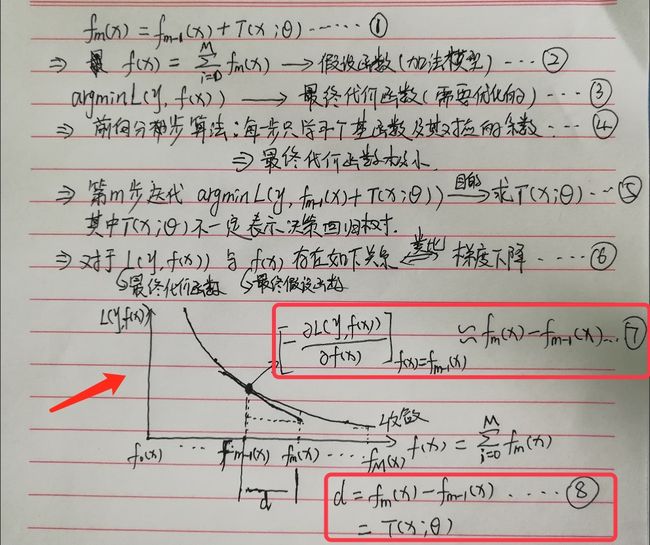
分析: 由式子7和式子8可知要使得第m步的代价函数极小需要使用Tm(x)去拟合第m-1步时的负梯度值。于是第m步的基函数便可以求出,如何迭代直至第M步。
最终GBDT的算法实现步骤如下(截取网上的图):

思考总结
1.boosting的思想:利用弱分类器(基函数)不断调整样本的权重从而调整误差,迭代学习出M个弱分类器,在进行相应的组合。——属于迭代类算法
2.Adaboost算法是:不断调整样本的权重来达到降低模型分类误差,最后使用线性组合基函数的方式,基函数可以有多种形式。当基函数为阈值分类器的时候,属于分类问题的提升树。
3.对于提升树算法模型,是基函数为决策树的Adaboost特殊算法,因为决策树有回归决策树和分类决策树,所以存在回归提升树和分类提升树。回归提升树学习的代价函数是平方误差,而分类提升树学习的是指数函数。
问题1:为什么Adaboost以阈值分类器为基函数的加法模型(分类提升树)里面的基函数前面有系数而回归提升树的加法模型中的基函数前面没有系数???
回答1:可以把分类提升树对样本进行类别预测的过程看成多个弱分类器分别对某个样本进行分类预测,再根据每个分类器在训练集上表现进行权重分布,所以有了系数。而回归提升树使用前向分步算法优化(极小化)代价函数时,每一步迭代是不断拟合残差(样本真实值与提升树当前步骤的预测值的差距),来达到缩小预测值与真实数据间的分布,进行拆分的是样本数据,所以回归提升树前面没有系数。