Flink入门这一篇就够了
Flink入门这一篇就够了
Flink介绍
1.Apache Flink是一个开源的分布式,高性能,高可用,准确的流处理框架
2.主要由JAVA代码实现
3.支持实时流处理和批处理,批数据只是流数据的一个极限特例
4.flink原生支持了迭代计算,内存管理和程序优化
抽像级别
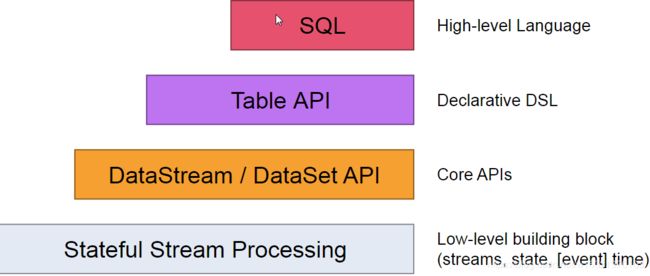
Flink基本组件介绍
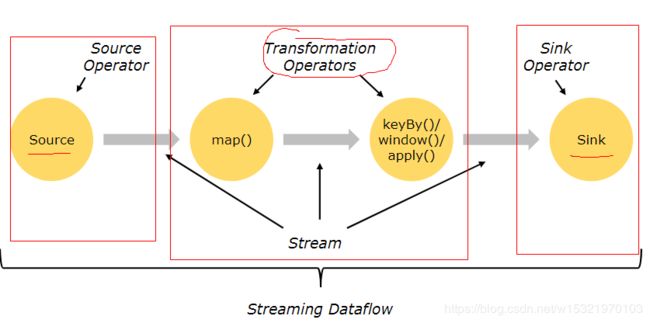
Flink运行图
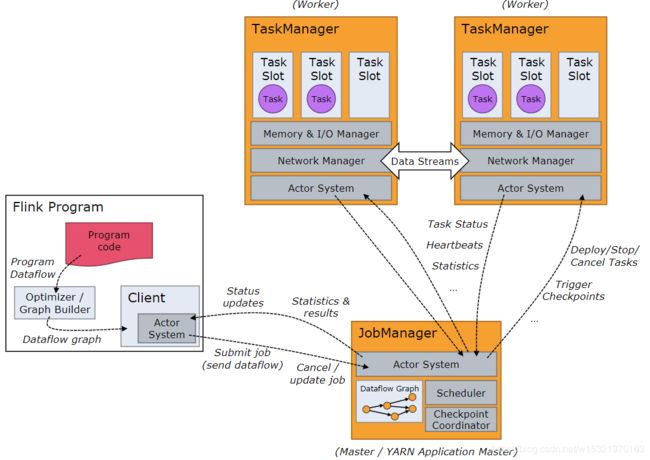
JobManagers (也称为 masters)用来协调分布式计算。负责进行任务调度,协调checkpoints,协调错误恢复等等。
至少需要一个JobManager。高可用部署下会有多个JobManagers,其中一个作为leader,其余处于standby状态。
TaskManagers(也称为 workers)真正执行dataflow中的tasks(更准确的描述是,subtasks),并且对 streams进行缓存和交换。至少需要一个TaskManager。
client 不作为程序执行的一部分,只是用于准备和发送作业给JobManager。 客户端可以断开连接,或者保持连接以接收进度报告。客户端可以作为触发执行的Java/Scala 程序的一部分也可以运行在命令行进程中./bin/flink run …
Flink的起动模式
本地模式 : 什么都不用配置直接bin/ start-cluster
standalong (cluster) : 单独部署一套集群
standlong + yarn : 和hdfs配合使用
具体使用方式用后面再介绍
1.先看本地模式
Linux中安装好JDK1.8
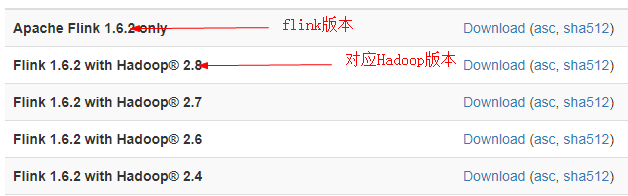
Flink下载(没有windows版本)
https://flink.apache.org/downloads.html
 通过sftp将下载好的文件传入到linux系统上(连接上虚拟机后 alt + p)
通过sftp将下载好的文件传入到linux系统上(连接上虚拟机后 alt + p)
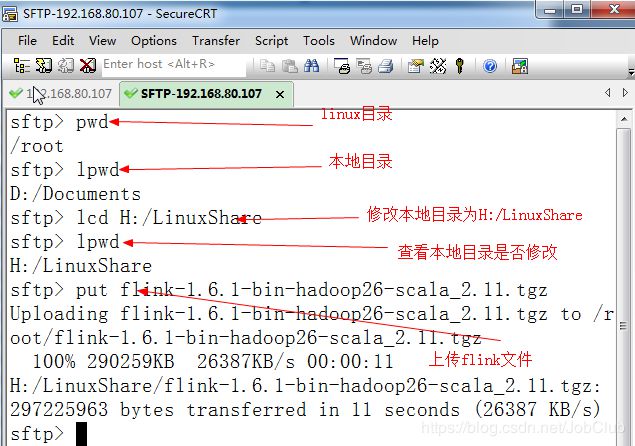 在/root下可以将文件移动到指定目录中
在/root下可以将文件移动到指定目录中
[root@hadoop301 ~]# mv flink-1.6.1-bin-hadoop26-scala_2.11.tgz /opt
解压
[root@hadoop301 ~]# tar -zxvf flink-1.6.1-bin-hadoop26-scala_2.11.tgz
进入目录启动
[root@hadoop301 flink-1.6.1]# ./bin/start-cluster.sh
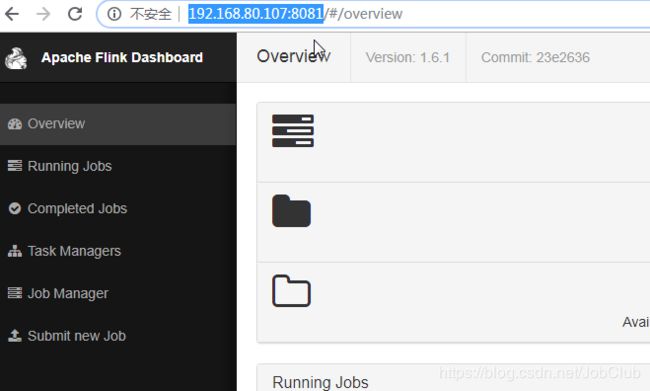
点开浏览器输入linuxIP端口为8081打开网页
在IDEA中可以开始写JAVA代码了(也可以使用scala)自行查看
https://ci.apache.org/projects/flink/flink-docs-release-1.6/quickstart/setup_quickstart.html
1.创建一个maven工程
2.pom文件
org.apache.flink
flink-java
1.6.1
org.apache.flink
flink-streaming-java_2.11
1.6.1
org.apache.flink
flink-clients_2.11
1.6.1
Word Count 代码-读取本地文件
//获取环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//读取本地文件-放入到数据集合中
DataSet text = env.readTextFile("/path/to/file");
DataSet> counts =
text.flatMap(new Tokenizer())
.groupBy(0)
.sum(1);
counts.writeAsCsv(outputPath, "\n", " ");
public static class Tokenizer implements FlatMapFunction> {
@Override
public void flatMap(String value, Collector> out) {
//value是文件中一行一行的数据,将每行数据进行切割
String[] tokens = value.toLowerCase().split("\\W+");
//token是分割出来的单词
for (String token : tokens) {
//如果切割出来的的单词
if (token.length() > 0) {
//写入集合进行统计
out.collect(new Tuple2(token, 1));
}
}
}
}