一、为什么了解zookeeper
1.1 主流的分布式协调服务器:
1.1.1 Curator菜谱
- 锁:包括共享锁、共享可重入锁、读写锁等。(临时节点)(http://blog.csdn.net/sqh201030412/article/details/51456143)
- 选举:Leader选举。
- Barrier:屏障,阻止分布式计算直至某个条件被满足的“栅栏”。(http://blog.csdn.net/nimasike/article/details/51593358)
- 持久化结点:连接或Session终止后仍然在Zookeeper中存在的结点。
- 队列:分布式队列、分布式优先级队列等。(http://blog.csdn.net/chinabestchina/article/details/78956703)
1.1.2 复杂应用
防重复提交
广播消息、配置中心
https://www.cnblogs.com/tommyli/p/3766189.html
1.2 Paxos 算法的优秀实现(Zab协议)
一致性算法可以通过共享内存(需要锁)或者消息传递实现,Paxos 算法采用的是后者
是莱斯利·兰伯特(Leslie Lamport,就是 LaTeX 中的"La",此人在微软研究院)1990年提出的一种基于消息传递的一致性算法。[1] 这个算法被认为是类似算法中最有效的。
Paxos 算法解决的问题是一个分布式系统如何就某个值(决议)达成一致。一个典型的场景是,在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点执行相同的操作序列,那么他们最后能得到一个一致的状态。
二、基本概念
2.1 数据结构(类似于文件系统)
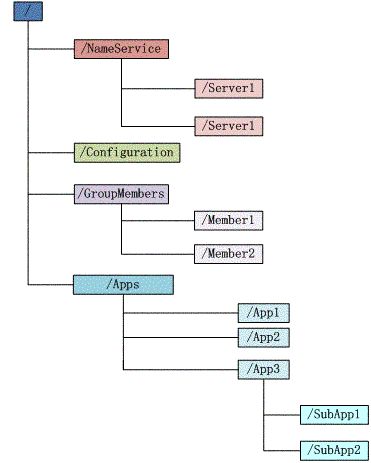
2.2 ZNode的类型(默认是persistent )
- PERSISTENT(永久的节点)
- EPHEMERAL(临时的,注册的客户端断开连接就会删除节点,临时节点不允许有子节点)
- PERSISTENT_SEQUENTIAL(znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护)
- EPHEMERAL_SEQUENTIAL(临时节点,命名规则同上)
- SEQUENTIAL:节点名末尾会自动追加一个10位数的单调递增的序号
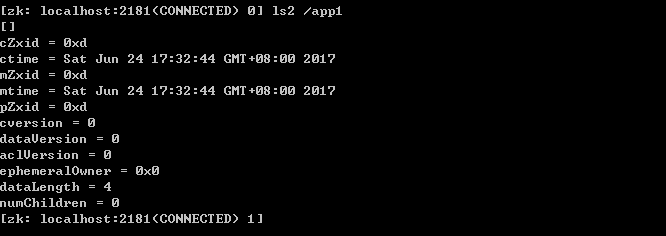
cZxid 就是 Create ZXID,表示节点被创建时的事务 ID。
mZxid 就是 Modified ZXID,表示节点最后一次被修改时的事务 ID。
ctime 就是 Create Time,表示节点创建时间。
mtime 就是 Modified Time,表示节点最后一次被修改的时间。
pZxid 表示该节点的子节点列表最后一次被修改时的事务 ID。只有子节点列表变更才会更新 pZxid,子节点内容变更不会更新。
cversion 表示子节点的版本号。
dataVersion 表示内容版本号。
dataLength 表示数据长度。
numChildren 表示子节点数。
ephemeralOwner 表示创建该临时节点时的会话 sessionID,如果是持久性节点那么值为 0。
2.3 ACLs(访问控制列表)
ACL可以控制访问ZooKeeper的节点,只能应用于特定的ZNode上,而不能应用于该ZNode的所有孩子节点上。它主要有如下五种权限:
-
- CREATE 允许创建Child Nodes
- READ 允许获取ZNode的数据,以及该节点的孩子列表
- WRITE 可以修改ZNode的数据
- DELETE 可以删除一个孩子节点
- ADMIN 可以设置权限
ZooKeeper内置了4种方式实现ACL:
-
- world 一个单独的ID,表示任何人都可以访问
- auth 不使用ID,只有认证的用户可以访问
- digest 使用username:password生成MD5哈希值作为认证ID
- ip 使用客户端主机IP地址来进行认证
2.4 Watcher(监视)
- ZooKeeper中的Watch是只能触发一次。也就是说,如果客户端在指定的ZNode设置了Watch,如果该ZNode数据发生变更,ZooKeeper会发送一个变更通知给客户端,同时触发设置的Watch事件。如果ZNode数据又发生了变更,客户端在收到第一次通知后没有重新设置该ZNode的Watch,则ZooKeeper就不会发送一个变更通知给客户端。
- ZooKeeper异步通知设置Watch的客户端。但是ZooKeeper能够保证在ZNode的变更生效之后才会异步地通知客户端,然后客户端才能够看到ZNode的数据变更。由于网络延迟,多个客户端可能会在不同的时间看到ZNode数据的变更,但是看到变更的顺序是能够保证有序一致的。
- ZNode可以设置两类Watch,一个是Data Watches(该ZNode的数据变更导致触发Watch事件),另一个是Child Watches(该ZNode的孩子节点发生变更导致触发Watch事件)。调用getData()和exists() 方法可以设置Data Watches,调用getChildren()方法可以设置Child Watches。调用setData()方法触发在该ZNode的注册的Data Watches。调用create()方法创建一个ZNode,将触发该ZNode的Data Watches;调用create()方法创建ZNode的孩子节点,则触发ZNode的Child Watches。调用delete()方法删除ZNode,则同时触发Data Watches和Child Watches,如果该被删除的ZNode还有父节点,则父节点触发一个Child Watches。
- 如果客户端与ZooKeeper Server断开连接,客户端就无法触发Watches,除非再次与ZooKeeper Server建立连接。
- 监视点只会保存在内存,如果客户端和服务端断开,所有监视点会从内存中清除。客户端也会维护一份监视点数据,在重连后,监视点会再次被同步到服务端
2.5 集群
2.5.1 系统模型如图所示:
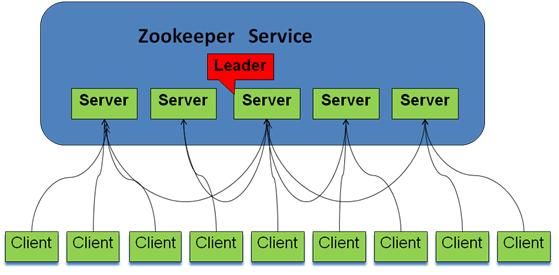
ZooKeeper被设计为复制集群架构,每个节点的数据都可以在集群中复制传播,使集群中的每个节点数据同步一致,从而达到服务的可靠性和可用性。
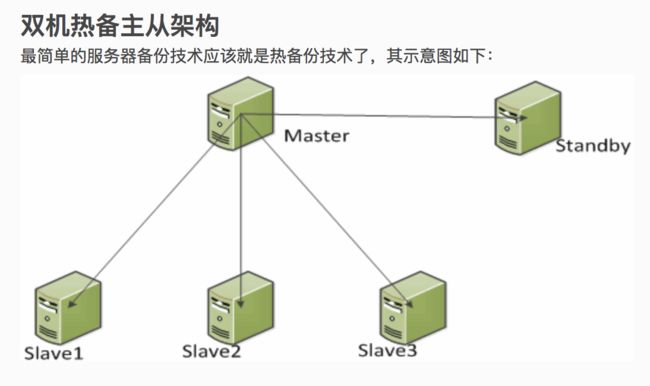
2.5.2 MySQL高可用复制架构
2.5.3 redis-cluster设计
从redis 3.0之后版本支持redis-cluster集群,Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。其redis-cluster架构图如下:
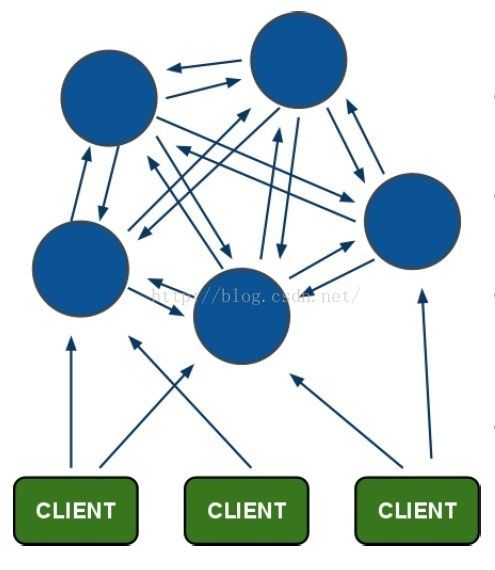
其结构特点:
1、所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
2、节点的fail是通过集群中超过半数的节点检测失效时才生效。
3、客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
4、redis-cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),cluster 负责维护node<->slot<->value。
5、Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中。
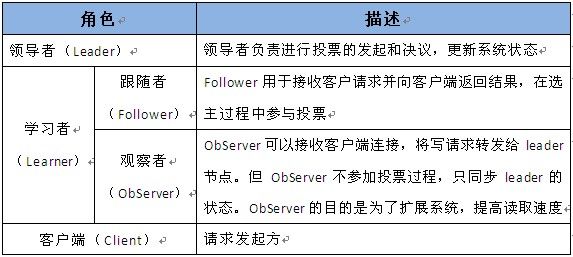
2.6 server角色
Zookeeper中的角色主要有以下三类,如下表所示:
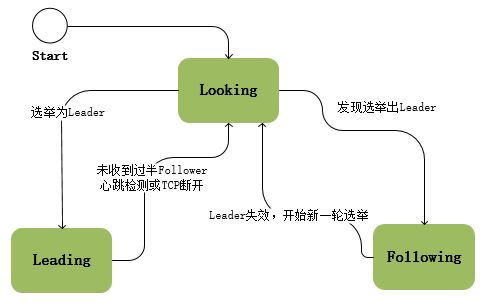
2.7 server状态
2.8 特性
- 最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
- 可靠性:具有简单、健壮、良好的性能,如果消息m被到一台服务器接受,那么它将被所有的服务器接受。
- 实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
- 等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
- 更新只能成功或者失败,没有中间状态。
- 包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
三、原理:
3.1、事务:
群首执行写操作(create、delete、setData)会产生事务
事务标识符zxid:long类型(64位)整数分为两部分:时间戳(计数器)(epoch,32位)和计数器(counter,32位,识别每一个消息)。时间戳表示何时获取了管理权,在每次群首选举发生的时候便会增加
事务更新:事务内容和事务标识
事务不支持回滚,事务的意义是确保事务的每一步操作都互不干扰
事务是幂等的
3.2、群首选举
仲裁模式、多数原则n/2+1
仲裁模式要求服务器间两两相交
群首选举算法可以OverWrite
脑裂场景:两个集合的服务器分别独立运行,形成了两个集群。
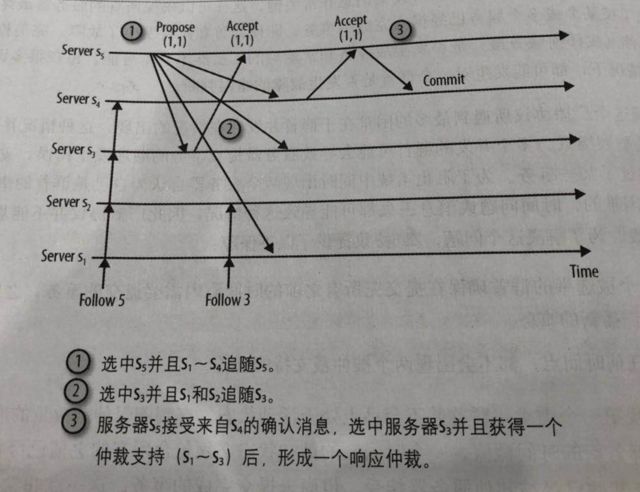
(1)正常网络情况下的选举:
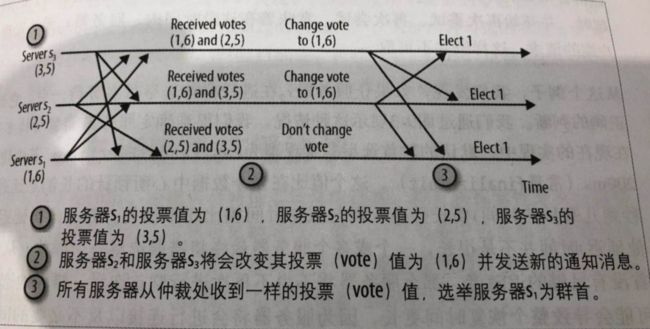
(2)消息交错导致一个服务器选择了另一个群首
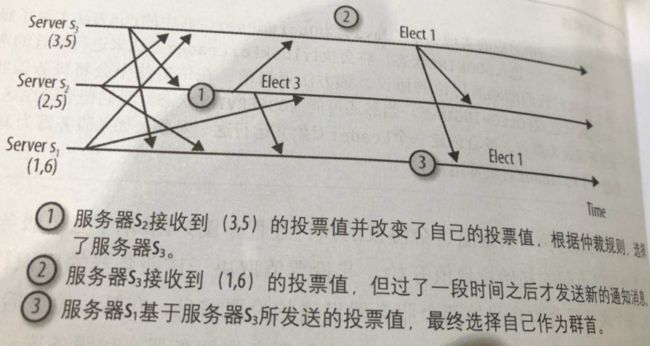
后果:s2选举了s3为群首,但是s3并不会作为群首响应s2,s2将一直超时、重试
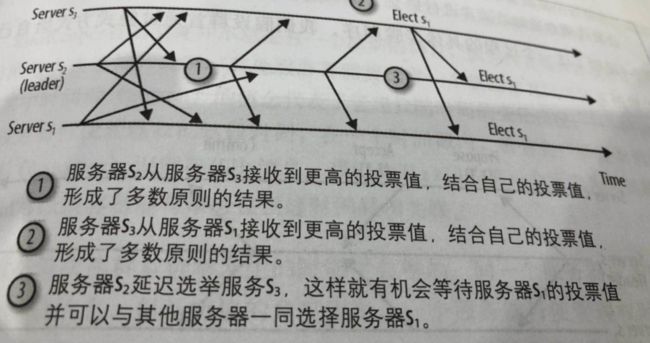
(3)群首选举时的长延迟,默认常量finalizeWait 200ms
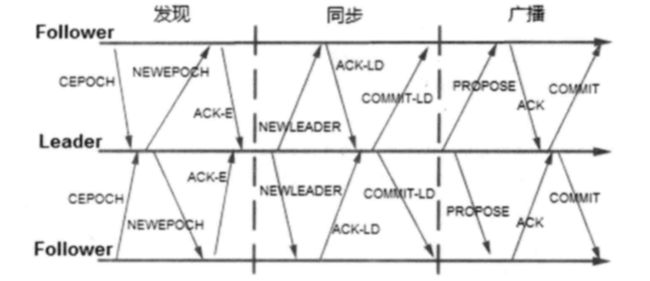
3.3、Zab协议:Zookeeper原子广播协议(Zookeeper Atomic Broadcast protocol)
Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。
Zab进一步可以细分为三个过程:
过程1:发现
即leade选举,参见3.2
过程2:同步
leader会挑选一个事务最旧的Follower f’(epoch=min(epoch)或epoch=min(epoch)且counter=min(counter)),广播leader和f’的事务差集I,即NEWLEADER,超过半数的follower ack-ld,leader 发送commit消息
过程3:广播
追随者接收到写操作请求转发给群首,群首发起一个提议,追随者响应ack,表示已接受该提议,当收到仲裁数量的ack后,群首发送消息通知追随者进行提交操作(二阶段提交),同时发送inform消息给观察者服务器
追随者在应答提案消息前,会检查是否为他的群首,以及确认事务的顺序正确
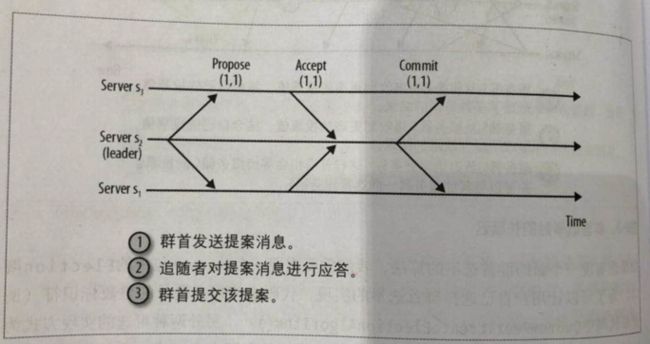
Q1:如果有服务器没有ack,群首如何做?
A1:ZAB协议在有过半的Follower服务器已经反馈Ack之后就开始提交Propose了,而不需要等待集群中所有Follower服务器都反馈响应。
Q2:如果A1成立,那么zk如何保证“client不论连接到哪个Server,展示给它都是同一个视图”?
Q3:commit操作发生失败?
A3:Leader在发送PROPOSAL消息之前,和Follower接收到PROPOSAL消息之后,都会立即将消息记录到日志中。这样在收到过半的ACK之后,既可以确认消息已经在过半的server中保存过了。即使之后的Commit消息发送失败,也在事实上通过了消息。丢失commit消息的follower会在下一个事务中发现这一点,并自动退出。通过重启来重新取得一致性。
Zab协议保障:
- 事务在服务器之间的传送顺序的一致:如果群首按照顺序广播了事务T和事务T’,那么每个服务器在提交T’事务前,保证事务T’已经提交完成
- 服务器不会跳过任何事务:如果某个服务器按照事务T、事务T’的顺序提交事务,所有其他服务器也必然会在提交事务T’前提交事务T
- 一个被选举的群首确保在提交完成所有之前的时间戳内需要提交的事务,之后才开始广播新的事务
- 在任何时间点,都不会出现两个被仲裁支持的群首(困难)
- 确保那些已经在Leader服务器上提交的事务最终被所有服务器都提交
- 确保丢弃那些只在Leader服务器上被提出的事务