HDFS2.x之RPC流程分析
1 概述
Hadoop提供了一个统一的RPC机制来处理client-namenode, namenode-dataname,client-dataname之间的通信。RPC是整个Hadoop中通信框架的核心,目前采用ProtocolBuf作为RPC的默认实现。RPC的整体调用流程如下:

2 Protobuf
Protocol buffer(以下简称PB),PB是Google开源的一种轻便高效的结构化数据存储格式,可以用于结构化数据的序列化和反序列化,很适合做数据存储或 RPC 数据交换格式,目前提供了 C++、Java、Python 三种语言的 API。序列化/反序列化速度快,网络或者磁盘IO传输的数据少。
RPC就是一台机器上的某个进程要调用另外一台机器上的某个进程的方法,中间通信传输的就是类似于“方法名、参数1、参数2……”这样的信息,是结构化的。
我们要定义一种PB实现的RPC传输格式,首先要定义相应的.proto文件,在Hadoop common工程里,这些文件放在hadoop-common\src\main\proto目录下;在Hadoop HDFS工程里这些文件放在hadoop-hdfs\src\main\proto目录下,以此类推。Hadoop编译脚本会调用相应的protoc二进制程序来编译这些以.proto结尾的文件,生成相应的.java文件。

由proto文件生成的类,均提供了读写二进制数据的方法:
(1)byte[] toByteArray():序列化message并且返回一个原始字节类型的字节数组;
(2)static Person parseFrom(byte[] data): 将给定的字节数组解析为message;
(3)void writeTo(OutputStream output): 将序列化后的message写入到输出流;
(4)static Person parseFrom(InputStream input): 读入并且将输入流解析为一个message;
另外,PB类中都有一些Builder子类,利用其中的build方法,可以完成对象的创建。PB的具体应用会在下面的RPC的Client和Server的分析中说明。
3 RPC Client端
以create方法为例,来说明RPC的具体执行流程。首先看下在Client端的执行过程。
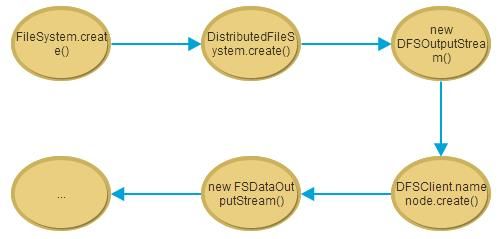
由HDFS客户端发起的create操作,在经过一系列的前置步骤之后,会通过DFSClient类中的namenode代理来完成,其定义如下:
final ClientProtocol namenode; …… NameNodeProxies.ProxyAndInfoproxyInfo = NameNodeProxies.createProxy(conf, nameNodeUri, ClientProtocol.class); this.dtService = proxyInfo.getDelegationTokenService(); this.namenode = proxyInfo.getProxy();
这说明此处的namenode实现的接口是ClientProtocol,也就是Client与NameNode之间RPC通信的协议。
HDFS2.x引入了NameNode的HA,这就使得Client端的底层代理是有多个的,分别连接Active NN和Standby NN。但是在实际运行过程中需要对Client调用呈现统一的接口,那么就出现了一个上层代理来统一上述这两个底层代理。所有由Clientfa来的方法调用都是先到达上层代理,通过上层代理转发到下层代理。并且,上层代理还会根据底层代理返回的Exception来决定是否进行Failover或者Retry等操作。
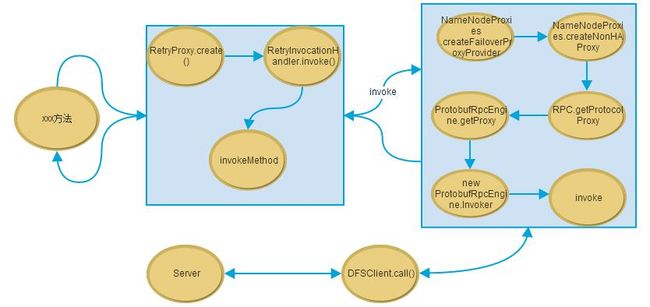
在使用HA模式时,客户端创建代理的总体流程是:

其中,
(1)RetryProxy.create方法会创建上层代理,用于接收客户端的请求,并根据情况调用连接到当前两个NameNode的底层代理。
Proxy.newProxyInstance( proxyProvider.getInterface().getClassLoader(), new Class[] { iface }, new RetryInvocationHandler(proxyProvider, retryPolicy) );
生成的这个代理对象实现了ClientProtocol接口,Client可以通过这个代理对象调用ClientProtocol接口中相应的方法。根据Java的动态代理机制,用户对这个代理对象的方法调用都转换为对RetryInvocationHandler(proxyProvider, retryPolicy)对象中invoke()方法的调用了。RetryInvocationHandler是与FailoverProxyProvider密切相关的,因为它需要FailoverProxyProvider提供底层代理的支持。
(2)当代理对象接收到请求的时候,会调用invoke方法来进行处理,这里的invoke方法是上层代理中的RetryInvocationHanlder.invoke方法。
首先要获取一个RetryPolicy,默认的策略是在构造RetryInvocationHandler时的参数。在Client与NameNode之间的ClientProtocol的RetryPolicy是:
RetryPolicies.failoverOnNetworkException(RetryPolicies.TRY_ONCE_THEN_FAIL, config.maxFailoverAttempts, config.failoverSleepBaseMillis,
config.failoverSleepMaxMillis)
接着,会调用invokeMethod方法调用底层的代理进行实际的处理:
Object ret = invokeMethod(method, args);
-> method.invoke(currentProxy, args);
currentProxy是现在正在使用的底层代理。当NN发生主从切换的时候,这个currentProxy也会发生相应的变化。
如果在调用过程中出现了异常,则针对不同的异常会做出不同的处理,这里的判断是根据生成动态代理(上层代理)的时候给定的RetryPolicy策略,默认的RetryPolicy是FailoverOnNetworkExceptionRetry,所以调用对应的shouldRetry()函数。
(2.1)如果Retry的次数已经超过最大尝试的次数了,那么就返回一个
RetryAction.RetryDecision.FAIL的RetryAction。
(2.2) 如果抛出的异常是ConnectionException、NoRouteToHostException、UnKnownHostException、StandbyException、RemoteException中的一个,说明底层代理在RPC过程中Active NN连不上或者宕机或者已经发生主从切换了,那么就需要返回一个RetryAction.RetryDecision.FAILOVER_AND_RETRY的RetryAction,需要执行performFailover()操作,然后用另外一个NN的底层代理重试。
(2.3)如果抛出的异常是SocketException、 IOException或者其他非RemoteException的异常,那么就无法判断这个RPC命令到底是不是执行成功了。可能是本地的Socket或者IO出问题,也可能是NN端的Socket或者IO问题。那就进行进一步的判断:如果被调用的方法是idempotent的,也就是多次执行是没有副作用的,那么就连接另外的一个底层代理重试;否则直接返回RetryAction.RetryDecision.FAIL。
(3)FailoverProxyProvider类的当前实现类为ConfiguredFailoverProxyProvider。它负责管理那两个activeNN和standbyNN的代理,当上层代理接收到来自用户的一个RPC命令之后,转发给当前正在使用的底层代理(由ConfiguredFailoverProxyProvider.currentProxyIndex决定,表示当前的代理对象的序号)执行,然后看是否抛出异常。如果抛出了异常,根据异常的种类来判断是执行failover,还是retry,或者两者都不做。如果需要切换NameNode代理的话,则会执行:
currentProxyIndex = (currentProxyIndex + 1) % proxies.size();
底层代理的实现是用的非HA模式:
current.namenode = NameNodeProxies.createNonHAProxy(conf,
current.address, xface, ugi, false).getProxy();
进一步调用->NameNodeProxies.createNNProxyWithClientProtocol
->RPC.getProtocolProxy
方法,并把生成的ClientNamenodeProtocolPB类型的代理对象proxy封装成ClientNamenodeProtocolTranslatorPB类型。
这里又会涉及到Java的动态代理,是在RPC.getProtocolProxy方法生成proxy对象的时候,RPC.getProtocolProxy的实现代码为:
return getProtocolEngine(protocol,conf).getProxy(protocol, clientVersion, addr, ticket, conf, factory, rpcTimeout, connectionRetryPolicy);
这里的引擎就是protocolbuf,所以,所有的RPC请求最终都会调用ProtobufRpcEngine类中的invoke方法进行和RPC的Server端通信以及数据的序列化和反序列化操作。
把Client的请求封装成call的操作返回也是在invoke中进行的:
val = (RpcResponseWritable) client.call(RPC.RpcKind.RPC_PROTOCOL_BUFFER,
new RpcRequestWritable(rpcRequest), remoteId);
封装的具体实现是调用的Client类中的call方法:
//封装成call
Call call = new Call(rpcKind, rpcRequest);
//建立和NameNode的连接
Connection connection = getConnection(remoteId, call);
//向NameNode发送数据
connection.sendParam(call);
RPC客户端的执行流程(HA模式)为:
4 RPC Server端
RPC的Server端的初始化方法是NameNode中被调用的:
rpcServer = createRpcServer(conf);
实际上初始化NameNodeRpcServer对象,调用其构造函数:
return new NameNodeRpcServer(conf, this);
在构造方法中,会初始化两个RPCServer,一个是serviceRpcServer,用来处理数据节点发来的RPC请求,另一个是clientRpcServer,用于处理客户端发来的RPC请求。
NameNodeRpcServer的构造方法会初始化RPC的Server端所需要的handler的数目(默认为10个),设置好处理引擎为Protocolbuf,初始化ClientNamenodeProtocolServerSideTranslatorPB类型的对象clientProtocolServerTranslator用来对传来的数据进行反序列化,对发送的数据进行序列化。
另外,会初始化提供不同RPC服务的对象BlockingService,针对客户端、数据节点端的有:
BlockingService clientNNPbService = ClientNamenodeProtocol.newReflectiveBlockingService(clientProtocolServerTranslator);
BlockingService dnProtoPbService = DatanodeProtocolService.newReflectiveBlockingService(dnProtoPbTranslator);
紧接着,会获取RPC的Server对象:
this.clientRpcServer = RPC.getServer(org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolPB.class, clientNNPbService, socAddr.getHostName(), socAddr.getPort(), handlerCount,
false,
conf,
namesystem.getDelegationTokenSecretManager());
此对象主要负责接收网络连接,读取数据,调用处理数据函数,返回结果。前两个参数表示如果RPC发送过来的是ClientNamenodeProtocolPB协议,那么负责处理这个协议的服务(com.google.protobuf.BlockingService类型的对象)就是clientNNPbService。
这个Server对象里有Listener, Handler, Responder内部类:
(1) Listener Thread:Server端会启一个Listener线程主要用于监听Client发送过来的Request,Listene会启动一个Reader的线程组,并把客户端发来的Connection对象通过NIO的SelectionKey传递给Reader, Listener相当于只作了一层转发;
(2) Reader Thread Pool:主要用于读取Listener传过来的Connection,并调用Connection的readAndProcess方法来读取Request,并封装成一个Call放到Call Queue中;
(3) Hanlder Thread Pool:Server会启动一组线程组来处理Call Queue中Call,并把处理的Respone中放到response queue中;
(4) Responder Thread:主要处理response queue中的response,并把response发送给client,如果当前response queue为空,则第一个新增的response会马上发送给client端,不会通过responer thread来发送。
这个RPC.getServer()会经过层层调用,因为现在默认的RPCEngine是ProtobufRpcEngine(ProtobufRpcEngine.java),就会调用到ProtobufRpcEngine.getServer这个函数,在这生成了一个Server对象,就是用于接收client端RPC请求,处理,回复的Server。这个Server对象是一个纯粹的网络服务的Server,在RPC中起到基础网络IO服务的作用。
RPC的Server端创建的总体流程是:

4.1 Reader处理
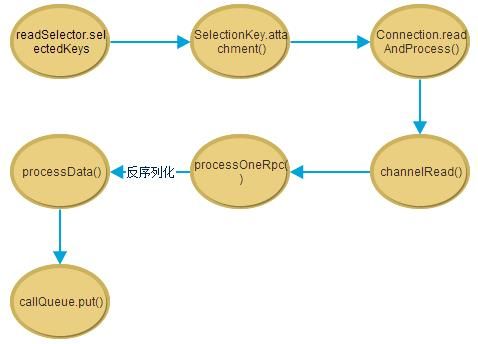
Server里的Reader线程也是基于Selector的异步IO模式,每次Select选出一个SelectionKey之后,会调用SelectionKey.attachment()把这个SelectionKey所attach的Connection对象获取(在Listener的run方法中进行的attatch),然后执行对应的readAndProcess()方法,把这个SelectionKey所对应的管道上的网络IO数据读入缓冲区。readAndProcess()方法会层层调用到Server.processData()方法,在这个方法内部,会把刚才从网络IO中读取的数据反序列化成对象rpcRequest对象。
rpcRequest对象的类型是继承自Writable类型的子类的对象,也就是说可以序列化/反序列化的类。这里rpcRequest对象里包含的RPC请求的内容对象是由.proto文件中Message生成的类,也就是说PB框架自动编译出来的类,后面可以通过调用这个类的get方法获取RPC中真正传输的数据。之后把生成的rpcRequest对象放到一个Call对象里面,再把Call对象放到队列Server.callQueue里面。
Reader的处理流程图如下:
4.2 Handler处理
Handler线程默认有10个,所以处理逻辑是多线程的。每个Handler线程会从刚才提到的callQueue中取一个Call对象,然后调用Server.call()方法执行这个Call对象中蕴含的RPC请求。Server.call()->RPC.Server.call()->Server.getRpcInvoker()->ProtobufRpcInvoker.call()在最后这个call()函数里面真正执行。
call方法会首先校验这个请求发过来的数据是不是合理的。然后就是获取实现这个协议的服务。实现协议的服务在初始化的时候已经注册过了,就是前面说的那个com.google.protobuf.BlockingService类型的对象clientNNPbService。
这个就是实现Client和NameNode之间的ClientNamenodeProtocol协议的服务,通过调用这句代码:
result = service.callBlockingMethod(methodDescriptor, null, param);
就会执行这个RPC请求的逻辑。service对象会把相应的方法调用转移到一个继承自BlockingInterface接口的实现类上。Service的真正实现类就是clientProtocolServerTranslator,是newReflectiveBlockingService()这个函数的参数。并且此类是ClientNamenodeProtocolProtos中的子类,是在HDFS编译的时候根据proto文件创建的。由于clientProtocolServerTranslator的构造方法中传递的参数是NameNodeRpcServer,因此进一步的方法调用都在NameNodeRpcServer中实现的。
Handler处理流程如下:

如果元数据操作逻辑NameNodeRpcServer里面抛出IOException,那么它都会把它封装成ServiceException,然后一路传递给client端。在client端,会通过ProtobufHelper.getRemoteException()把封装在ServiceException中的IOException获取出来。
RPC的Server端总体处理流程如下:
