数据网格产品经常会使用P2P进行通信,借此机会系统地学习一下P2P网络和其资源搜索策略。
1 P2P网络架构
谈到P2P就涉及到一个概念:Overlay Network(覆盖网络)。所谓覆盖网络是应用层网络,几乎不考虑网络层和物理层,它具体指的就是建立在另一个网络上的网络。例如P2P网络就是覆盖网络,因为它运行在互联网之前,但允许对未知IP主机的访问。通过DHT等算法,可以在事先不知道IP地址的情况下,访问到存储某个文件的结点。
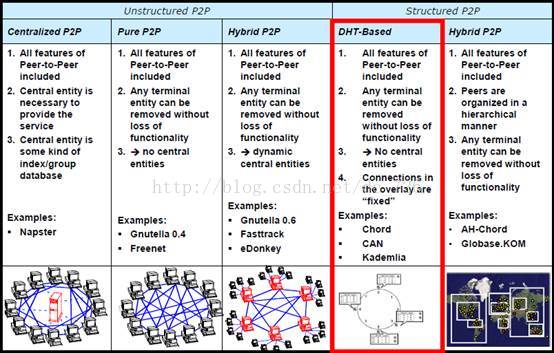
常见的P2P系统主要有Unstructured Network和Structured Network两种架构。
1.1 Unstructured Network
非结构化的P2P网络并不给覆盖网络强加某种特定架构,而是结点间随机形成链接。最流行的P2P网络,像Bittorrent、eMule、Gnutella、Kazaa等都是非结构化的P2P协议。因为缺少结构,所以网络面对频繁的动态添加和删除结点时,依然能够健壮地运行。但也正因为缺少结构,所以当某个结点想要搜索某些数据或文件时,查询必须flood整个网络(详见1.3搜索策略)。

1.2 Structured Network
结构化P2P网络将覆盖网络组织成某种特定的拓扑结构,并且它的协议能够保证:任何结点都能高效地搜索网络中的资源,即使资源是非常冷门的。常见的结构化P2P网络通常实现一致性哈希或者其变种分布式哈希表DHT分配文件的所有权到特定的结点。

1.3 搜索策略
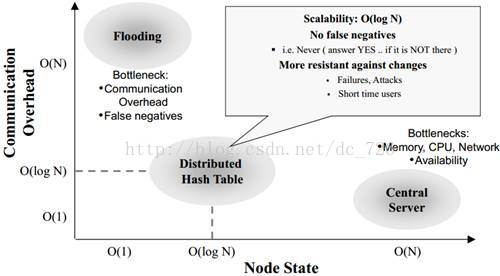
两种P2P网络可以使用不同的检索策略:中央索引、本地索引和分布式索引。分布式索引策略是对其他两种策略的权衡。
中央索引(中央服务器)
由一个中央服务器统一保存资源与结点的关系。这种方式搜索效率比较高,因为可以通过中央索引直接定位到目标结点,然而这种方式有时并不可行,特别是集群规模特别大时。

本地索引(flooding搜索)
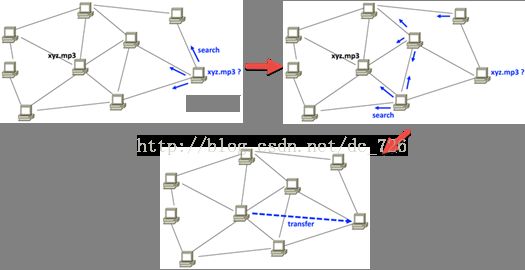
每个结点保存自己的资源信息,当寻找不属于自己的资源时,会flooding整个网络进行寻找。这种flooding的方式会在网络中引起大量的traffic,并使每个结点都要处理查询请求而导致高CPU和内存使用率。并且flooding不保证通信质量,所以flooding也无法保证一定能够找到保存指定数据的那个结点。因为热数据在多个结点上存在,所以比较容易搜索成功。反之,冷数据只在很少的结点上存在,所以搜索很可能会以失败告终。并且搜索效率也很低,也容易导致安全问题。
分布式索引
为了高效地在网络中搜索,结点需要保存满足特定条件的邻居的列表,这使得整个网络在高频率的添加删除结点时,没有非结构化网络那样健壮。使用DHT路由的结构化P2P网络的著名软件有BitTorrent,Kad Network,以及各种研究项目Chord等。基于DHT的网络在网络计算系统中也有广泛的应用,它帮助实现高效的资源发现和应用程序调度等。
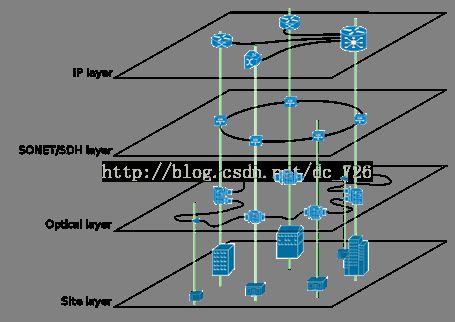
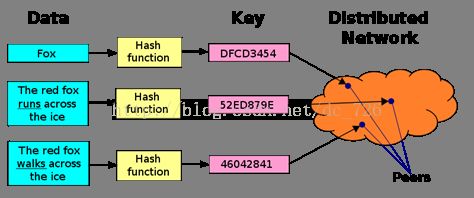
典型的P2P网络使用的架构和搜索策略如下:
2 基本的分区算法
经典的分区算法有直接取模和哈希取模。假设有K台服务器,我们可以这样确定数据X所在的服务器i:
Ø 直接取模i = X mod k:问题是数据分布不均匀。
Ø 哈希取模i = hash(X) mod k:问题是1)根据集群和数据规模,散列冲突可能会比较严重(只能通过替换更好的哈希算法来平衡);2)扩容添加结点或故障删除结点时(k->k±1),所有数据都要重新映射到新的结点上(通过后面介绍的两种分布式哈希可以解决)。
3 一致性哈希
3.1 构造
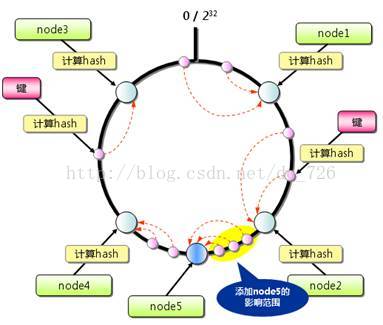
将结点和数据映射到同一个线性地址空间,结点负责保存前一结点到本结点之间的数据。

3.2 Lookup过程
首先,蓝色结点确定红色结点负责保存key1。然后,蓝色结点将lookup或insert请求发送给红色结点。所以lookup过程的算法复杂度是O(1)。

3.3 添加删除结点
当添加删除结点时,影响的只是很小的一部分数据。
4 分布式哈希表
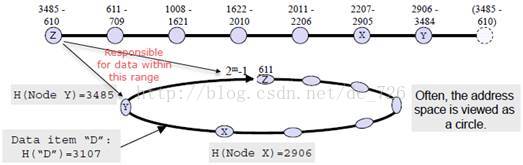
分布式哈希表DHT是一种概念模型或者说思想,其主要思路是:将每条文件索引K文件名或其他属性的哈希值-V存储文件的结点IP地址,组成一张巨大的文件索引哈希表。然后,再将这张大表按照一定规则分割成许多小块,并分布到各个结点上,每个结点负责维护其中一块。DHT使用一致性哈希的思想来最小化拓扑结构变化带来的影响,并构造overlay网络实现高效地搜索。
首先,将结点和数据映射到同一个线性地址空间,每个结点只负责地址空间中的一部分数据,但结点负责的信息通常是有重叠和冗余的。通常我们将这个线性地址空间看成一个环:
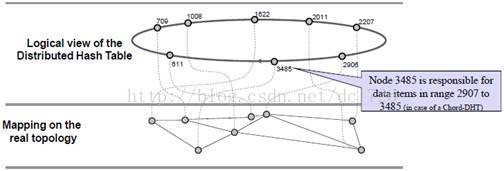
逻辑上地址空间形成的环对应着底层的物理拓扑结构,要注意的是真正的(underlay)的拓扑结构和逻辑的(overlay)拓扑结构通常是无关联的:
根据不同的DHT实现,查找过程会有不同。但不同的算法实现都类似于下图所示的过程,在地址空间中利用各种算法高效地找到负责保存数据的结点。注意,最后找到的数据分为两种:
Ø value就是我们要找的数据,它直接存储在结点上,这对于数据量不大的情况来说比较合适。
Ø value不是我们要找的数据,而是数据存储在另一台机器的地址信息(如下图所示)。这种间接的存储方式多了一步数据的获取,但是对于大文件的存储来说更加合适。

5 Chord实现
接下来要介绍的是最常见的MIT的Chord版DHT实现。
4.1 Chord环和Finger表
首先,Chord使用SHA-1哈希函数(生成160位的id)和取模:
Ø Node-id = SHA1(IP/mac)
Ø Key-id = SHA1(key)
Ø id-space mod ![]()
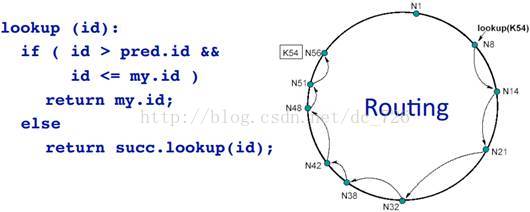
4.2 Lookup过程
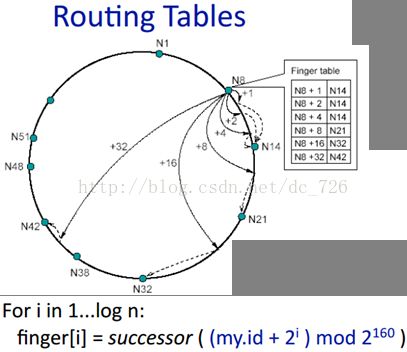
对于Chord版的DHT实现来说,这种Lookup过程是通过一张叫做Finger表的路由表来完成的,它根据计算数据id指数级增长时对应的各个结点,形成表中的信息:
在没有finger表的情况下,需要不断访问后继结点继续lookup,即O(n)跳才能找到目标结点:
有了finger表,就可以实现O(logN)的高效lookup:

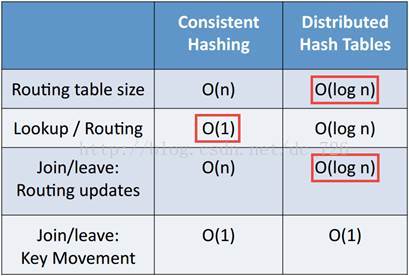
5 算法复杂度对比
除了搜索/路由外,其他几项都是DHT占优:
参考资料
1 Princeton - P2P Systems and Distributed Hash Tables
2 Overlay Network:http://en.wikipedia.org/wiki/Overlay_network
3 Peer-to-Peer:http://en.wikipedia.org/wiki/Peer-to-peer
4 Structured Homogenous P2P Overlay Networks
5 memcached全面剖析--4. memcached的分布式算法