个人读书笔记,详情参考《MySQL技术内幕 Innodb存储引擎》
1,checkpoint产生的背景
数据库在发生增删查改操作的时候,都是先在buffer pool中完成的,为了提高事物操作的效率,buffer pool中修改之后的数据,并没有立即写入到磁盘,这有可能会导致内存中数据与磁盘中的数据产生不一致的情况。
事物要求之一是持久性(Durability),buffer pool与磁盘数据的不一致性的情况下发生故障,可能会导致数据无法持久化。
为了防止在内存中修改但尚未写入到磁盘的数据,在发生故障重启数据之后产生事物未持久化的情况,是通过日志(redo log)先行的方式来保证的。
redo log可以在故障重启之后实现“重做”,保证了事物的持久化的特性,但是redo log空间不可能无限制扩大,对于内存中已修改但尚未提交到磁盘的数据,也即脏页,也需要写入磁盘。
对于内存中的脏页,什么时候,什么情况下,将多少脏页写入磁盘,是由多方面因素决定的。
checkpoint的工作之一,就是对于内存中的脏页,在一定条件下将脏页刷新到磁盘。
2,checkpoint的分类
按照checkpoint刷新的方式,MySQL中的checkpoint分为两种,也即sharp checkpoint和fuzzy checkpoint。
sharp checkpoint:在关闭数据库的时候,将buffer pool中的脏页全部刷新到磁盘中。
fuzzy checkpoint:数据库正常运行时,在不同的时机,将部分脏页写入磁盘,进刷新部分脏页到磁盘,也是为了避免一次刷新全部的脏页造成的性能问题。
3 ,checkpoint发生的时机
checkpoint都是将buffer pool中的脏页刷新到磁盘,但是在不同的情况下,checkpoint会被以不同的方式触发,同时写入到磁盘的脏页的数量也不同。
3.1, Master Thread checkpoint
在Master Thread中,会以每秒或者每10秒一次的频率,将部分脏页从内存中刷新到磁盘,这个过程是异步的。正常的用户线程对数据的操作不会被阻塞。
3.2 ,FLUSH_LRU_LIST checkpoint
FLUSH_LRU_LIST checkpoint是在单独的page cleaner线程中执行的。
MySQL对缓存的管理是通过buffer pool中的LRU列表实现的,LRU 空闲列表中要保留一定数量的空闲页面,来保证buffer pool中有足够的空闲页面来相应外界对数据库的请求。
当这个空间页面数量不足的时候,发生FLUSH_LRU_LIST checkpoint。
空闲页的数量由innodb_lru_scan_depth参数表来控制的,因此在空闲列表页面数量少于配置的值的时候,会发生checkpoint,剔除部分LRU列表尾端的页面。

3.3 ,Async/Sync Flush checkpoint
Async/Sync Flush checkpoint是在单独的page cleaner线程中执行的。
Async/Sync Flush checkpoint 发生在重做日志不可用的时候,将buffer pool中的一部分脏页刷新到磁盘中,在脏页写入磁盘之后,事物对应的重做日志也就可以释放了。
关于redo_log文件的的大小,可以通过innodb_log_file_size来配置。
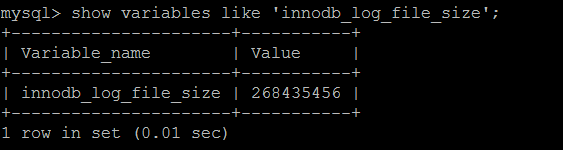
对于是执行Async Flush checkpoint还是Sync Flush checkpoint,由checkpoint_age以及async_water_mark和sync_water_mark来决定。
定义:
checkpoint_age = redo_lsn-checkpoint_lsn,也即checkpoint_age等于最新的lsn减去已经刷新到磁盘的lsn的值
async_water_mark = 75%*innodb_log_file_size
sync_water_mark = 90%*innodb_log_file_size
1)当checkpoint_age
在mysql 5.6之后,不管是Async Flush checkpoint还是Sync Flush checkpoint,都不会阻塞用户的查询进程。
个人认为:
由于磁盘是一种相对较慢的存储设备,内存与磁盘的交互是一个相对较慢的过程
由于innodb_log_file_size定义的是一个相对较大的值,正常情况下,由前面两种checkpoint刷新脏页到磁盘,在前面两种checkpoint刷新脏页到磁盘之后,脏页对应的redo log空间随即释放,一般不会发生Async/Sync Flush checkpoint。同时也要意识到,为了避免频繁低发生Async/Sync Flush checkpoint,也应该将innodb_log_file_size配置的相对较大一些。
3.4, Dirty Page too much Checkpoint
Dirty Page too much Checkpoint是在Master Thread 线程中每秒一次的频率实现的。
Dirty Page too much 意味着buffer pool中的脏页过多,执行checkpoint脏页刷入磁盘,保证buffer pool中有足够的可用页面。
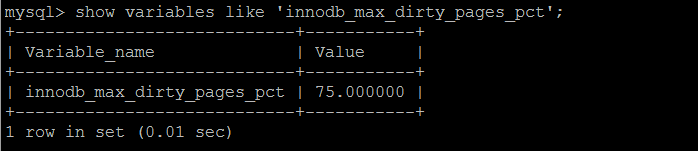
Dirty Page 由innodb_max_dirty_pages_pct配置,innodb_max_dirty_pages_pct的默认值在innodb 1.0之前是90%,之后是75%。
总结:
MySQL数据库(当然其他关系数据也有类似的机制),为了提高事物操作的效率,在事物提交之后并不会立即将修改后的数据写入磁盘,而是通过日志先行(write log ahead)的方式保证事物的持久性。
对于将事物修改的数据页面,也即脏页,通过异步的方式刷新到磁盘中,checkpoint正是实现这种异步刷新脏页到磁盘的实施者。
不同的情况下,会发生不同的checkpoint,将不同数量的脏页刷新到磁盘,从而到达管理内存(第1,2,4种checkpoint)和redo log可用空间(第3种checkpoint)的目的。