搜索引擎原理
通过搜索引擎进行数据查询时,搜索引擎并不是直接在数据库中进行查询,而是搜索引擎会对数据库中的数据进行一遍预处理,单独建立起一份索引结构数据。
我们可以将索引结构数据想象成是字典书籍的索引检索页,里面包含了关键词与词条的对应关系,并记录词条的位置。
我们在通过搜索引擎搜索时,搜索引擎将关键字在索引数据中进行快速对比查找,进而找到数据的真实存储位置。
Elasticsearch
开源的 Elasticsearch 是目前全文搜索引擎的首选。
它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它。
Elasticsearch 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
Elasticsearch 是用Java实现的。
搜索引擎在对数据构建索引时,需要进行分词处理。分词是指将一句话拆解成多个单字或词,这些字或词便是这句话的关键词。如
我在广州。
‘我’、‘在’、‘广’、‘州’、‘广州’等都可以是这句话的关键词。
Elasticsearch 不支持对中文进行分词建立索引,需要配合扩展elasticsearch-analysis-ik来实现中文分词处理。
使用Docker安装Elasticsearch及其扩展
获取镜像,可以通过网络pull
docker image pull delron/elasticsearch-ik:2.4.6-1.0
修改elasticsearch的配置文件 elasticsearc-2.4.6/config/elasticsearch.yml第54行,更改ip地址为本机ip地址
network.host: 10.211.55.5
创建docker容器运行
docker run -dti --network=host --name=elasticsearch -v /home/python/elasticsearch-2.4.6/config:/usr/share/elasticsearch/config delron/elasticsearch-ik:2.4.6-1.0
使用haystack对接Elasticsearch
Haystack为Django提供了模块化的搜索。它的特点是统一的,熟悉的API,可以让你在不修改代码的情况下使用不同的搜索后端(比如 Solr, Elasticsearch, Whoosh, Xapian 等等)。
我们在django中可以通过使用haystack来调用Elasticsearch搜索引擎。
1)安装
pip install drf-haystack
pip install elasticsearch==2.4.1
drf-haystack是为了在REST framework中使用haystack而进行的封装(如果在Django中使用haystack,则安装django-haystack即可)。
2)注册应用
INSTALLED_APPS = [ ... 'haystack', ... ]
3)配置
在配置文件中配置haystack使用的搜索引擎后端
# Haystack HAYSTACK_CONNECTIONS = { 'default': { 'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine', 'URL': 'http://10.211.55.5:9200/', # 此处为elasticsearch运行的服务器ip地址,端口号固定为9200 'INDEX_NAME': 'meiduo', # 指定elasticsearch建立的索引库的名称 }, } # 当添加、修改、删除数据时,自动生成索引 HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
注意:
HAYSTACK_SIGNAL_PROCESSOR 的配置保证了在Django运行起来后,有新的数据产生时,haystack仍然可以让Elasticsearch实时生成新数据的索引
4)创建索引类
通过创建索引类,来指明让搜索引擎对哪些字段建立索引,也就是可以通过哪些字段的关键字来检索数据。
在应用中新建search_indexes.py文件,用于存放索引类
from haystack import indexes from .models import SKU class SKUIndex(indexes.SearchIndex, indexes.Indexable): """ SKU索引数据模型类 """ text = indexes.CharField(document=True, use_template=True) def get_model(self): """返回建立索引的模型类""" return SKU def index_queryset(self, using=None): """返回要建立索引的数据查询集""" return self.get_model().objects.filter(is_launched=True)
在SKUIndex建立的字段,都可以借助haystack由elasticsearch搜索引擎查询。
其中text字段我们声明为document=True,表名该字段是主要进行关键字查询的字段, 该字段的索引值可以由多个数据库模型类字段组成,具体由哪些模型类字段组成,我们用use_template=True表示后续通过模板来指明。其他字段都是通过model_attr选项指明引用数据库模型类的特定字段。
在REST framework中,索引类的字段会作为查询结果返回数据的来源。
6)在templates目录中创建text字段使用的模板文件
具体在templates/search/indexes/goods/sku_text.txt文件中定义
注意:templates/search/indexes/这个路径是固定的,goods是你使用的应用名,后缀_text.txt也是固定的,不能随便写
{{ object.name }}
{{ object.caption }}
{{ object.id }}
此模板指明当将关键词通过text参数名传递时,可以通过sku的name、caption、id来进行关键字索引查询。
7)手动生成初始索引
python manage.py rebuild_index
8)创建序列化器
在 应用名/serializers.py中创建haystack序列化器
from drf_haystack.serializers import HaystackSerializer class SKUSerializer(serializers.ModelSerializer): """ SKU序列化器 """ class Meta: model = SKU fields = ('id', 'name', 'price', 'default_image_url', 'comments') class SKUIndexSerializer(HaystackSerializer): """ SKU索引结果数据序列化器 """ object = SKUSerializer(read_only=True) class Meta: index_classes = [SKUIndex] fields = ('text', 'object')
说明:
-
SKUIndexSerializer序列化器中的object字段是用来向前端返回数据时序列化的字段。
Haystack通过Elasticsearch检索出匹配关键词的搜索结果后,还会在数据库中取出完整的数据库模型类对象,放到搜索结果的object属性中,并将结果通过SKUIndexSerializer序列化器进行序列化。所以我们可以通过声明搜索结果的object字段以SKUSerializer序列化的形式进行处理,明确要返回的搜索结果中每个数据对象包含哪些字段
9)创建视图
在 应用名/views.py中创建视图
from drf_haystack.viewsets import HaystackViewSet class SKUSearchViewSet(HaystackViewSet): """ SKU搜索 """ index_models = [SKU] serializer_class = SKUIndexSerializer
10)定义路由
通过REST framework的router来定义路由
router = DefaultRouter()
router.register(...)
...
urlpatterns += router.urls
bug说明:
如果在配置完haystack并启动程序后,出现如下异常,是因为drf-haystack还没有适配最新版本的REST framework框架
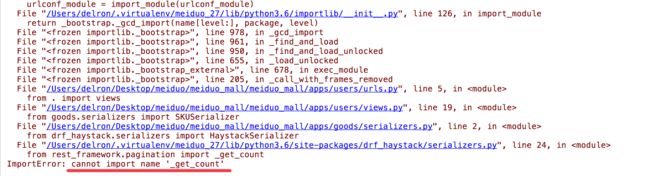
可以通过修改REST framework框架代码,补充_get_count函数定义即可
文件路径 虚拟环境下的 lib/python3.6/site-packages/rest_framework/pagination.py
def _get_count(queryset): """ Determine an object count, supporting either querysets or regular lists. """ try: return queryset.count() except (AttributeError, TypeError): return len(queryset)