2019独角兽企业重金招聘Python工程师标准>>> 
每次丢了东西,我们都希望有一种方法能快速定位出失物。现在,目标检测算法或许能做到。目标检测的用途遍布多个行业,从安防监控,到智慧城市中的实时交通监测。简单来说,这些技术背后都是强大的深度学习算法。
在这篇文章中,我们会进一步地了解这些用在目标检测中的算法,首先要从RCNN家族开始,例如RCNN、Fast RCNN和Faster RCNN。
1. 解决目标检测任务的简单方法(利用深度学习)
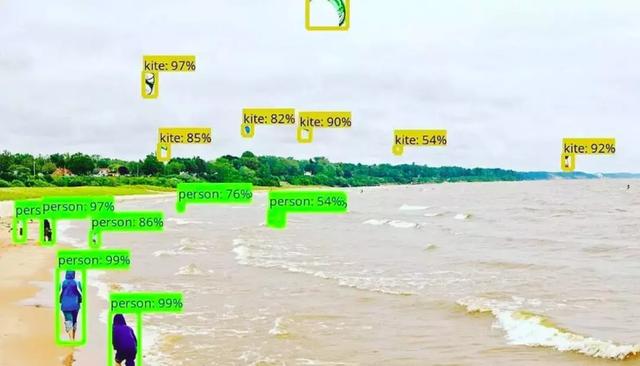
下图是描述目标检测算法如何工作的典型例子,图中的每个物体(不论是任务还是风筝),都能以一定的精确度被定位出来。
首先我们要说的就是在图像目标检测中用途最广、最简单的深度学习方法——卷积神经网络(CNN)。我要讲的是CNN的内部工作原理,首先让我们看看下面这张图片。
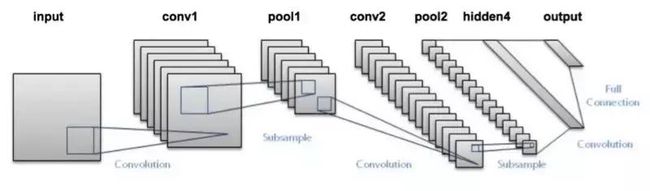
向网络中输入一张图片,接着将它传递到多个卷积和池化层中。最后输出目标所属的类别,听上去非常直接。
对每张输入的图片,我们都有对应的输出类别,那么这一技术能检测图片中多种目标吗?答案是肯定的!下面就让我们看看如何用一个卷积神经网络解决通用的目标检测问题。
1.首先,我们把下面的图片用作输入:

2.之后,我们将图片分成多个区域:

3.将每个区域看作单独的图片。
4.把这些区域照片传递给CNN,将它们分到不同类别中。
5.当我们把每个区域都分到对应的类别后,再把它们结合在一起,完成对原始图像的目标检测:

使用这一方法的问题在于,图片中的物体可能有不同的长宽比和空间位置。例如,在有些情况下,目标物体可能占据了图片的大部分,或者非常小。目标物体的形状也可能不同。
有了这些考虑因素,我们就需要分割很多个区域,需要大量计算力。所以为了解决这一问题,减少区域的分割,我们可以使用基于区域的CNN,它可以进行区域选择。
2. 基于区域的卷积神经网络介绍
2.1 RCNN简介
和在大量区域上工作不同,RCNN算法提出在图像中创建多个边界框,检查这些边框中是否含有目标物体。RCNN使用选择性搜索来从一张图片中提取这些边框。
首先,让我们明确什么是选择性搜索,以及它是如何辨别不同区域的。组成目标物体通常有四个要素:变化尺度、颜色、结构(材质)、所占面积。选择性搜索会确定物体在图片中的这些特征,然后基于这些特征突出不同区域。下面是选择搜索的一个简单案例:
- 首先将一张图片作为输入:

- 之后,它会生成最初的sub-分割,将图片分成多个区域:

- 基于颜色、结构、尺寸、形状,将相似的区域合并成更大的区域:

- 最后,生成最终的目标物体位置(Region of Interest)。
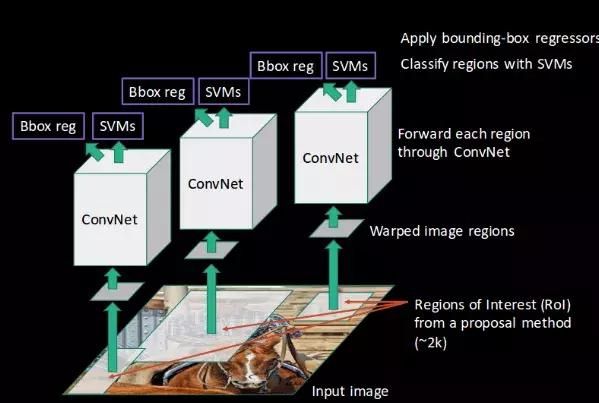
用RCNN检测目标物体的步骤如下:
- 我们首先取一个预训练卷积神经网络。
- 根据需要检测的目标类别数量,训练网络的最后一层。
- 得到每张图片的感兴趣区域(Region of Interest),对这些区域重新改造,以让其符合CNN的输入尺寸要求。
- 得到这些区域后,我们训练支持向量机(SVM)来辨别目标物体和背景。对每个类别,我们都要训练一个二元SVM。
- 最后,我们训练一个线性回归模型,为每个辨识到的物体生成更精确的边界框。
下面我们就用具体的案例解释一下。
- 首先,将以下图片作为输入:

- 之后,我们会用上文中的选择性搜索得到感兴趣区域:

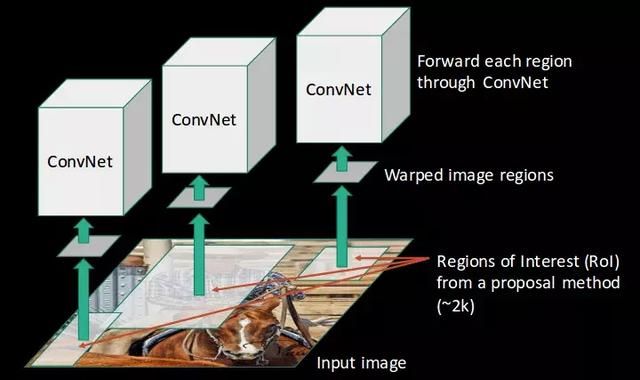
- 将这些区域输入到CNN中,并经过卷积网络:
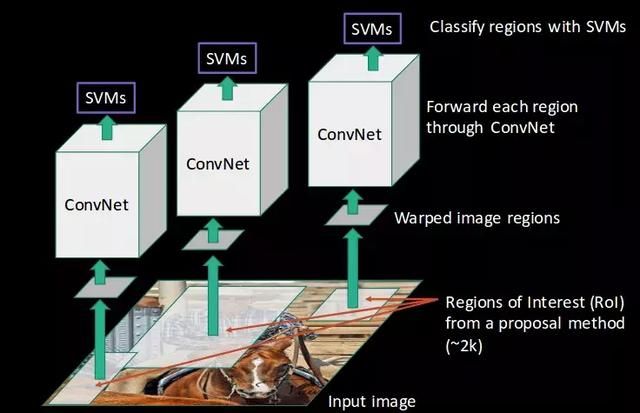
- CNN为每个区域提取特征,利用SVM将这些区域分成不同类别:
- 最后,用边界框回归预测每个区域的边界框位置:
这就是RCNN检测目标物体的方法。
2.2 RCNN的问题
现在,我们了解了RCNN能如何帮助进行目标检测,但是这一技术有自己的局限性。训练一个RCNN模型非常昂贵,并且步骤较多:
- 根据选择性搜索,要对每张图片提取2000个单独区域;
- 用CNN提取每个区域的特征。假设我们有N张图片,那么CNN特征就是N*2000;
- 用RCNN进行目标检测的整个过程有三个模型:
- 用于特征提取的CNN
- 用于目标物体辨别的线性SVM分类器
- 调整边界框的回归模型。
这些过程合并在一起,会让RCNN的速度变慢,通常每个新图片需要40—50秒的时间进行预测,基本上无法处理大型数据集。
所以,这里我们介绍另一种能突破这些限制的目标检测技术。
3. Fast RCNN
3.1 Fast RCNN简介
想要减少RCNN算法的计算时间,可以用什么方法?我们可不可以在每张图片上只使用一次CNN即可得到全部的重点关注区域呢,而不是运行2000次。
RCNN的作者Ross Girshick提出了一种想法,在每张照片上只运行一次CNN,然后找到一种方法在2000个区域中进行计算。在Fast RCNN中,我们将图片输入到CNN中,会相应地生成传统特征映射。利用这些映射,就能提取出感兴趣区域。之后,我们使用一个Rol池化层将所有提出的区域重新修正到合适的尺寸,以输入到完全连接的网络中。
简单地说,这一过程含有以下步骤:
- 输入图片。
- 输入到卷积网络中,它生成感兴趣区域。
- 利用Rol池化层对这些区域重新调整,将其输入到完全连接网络中。
- 在网络的顶层用softmax层输出类别。同样使用一个线性回归层,输出相对应的边界框。
所以,和RCNN所需要的三个模型不同,Fast RCNN只用了一个模型就同时实现了区域的特征提取、分类、边界框生成。
同样,我们还用上面的图像作为案例,进行更直观的讲解。
- 首先,输入图像:
图像被传递到卷积网络中,返回感兴趣区域:

之后,在区域上应用Rol池化层,保证每个区域的尺寸相同:

最后,这些区域被传递到一个完全连接的网络中进行分类,并用softmax和线性回归层同时返回边界框:

3.2 Fast RCNN的问题
但是即使这样,Fast RCNN也有某些局限性。它同样用的是选择性搜索作为寻找感兴趣区域的,这一过程通常较慢。与RCNN不同的是,Fast RCNN处理一张图片大约需要2秒。但是在大型真实数据集上,这种速度仍然不够理想。
4.Faster RCNN
4.1 Faster RCNN简介
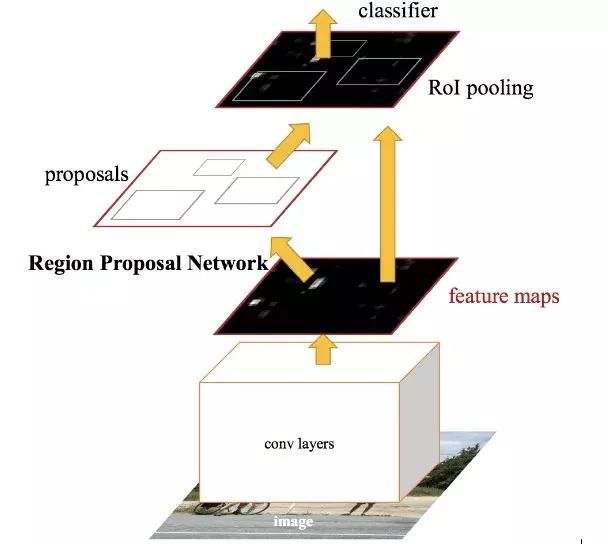
Faster RCNN是Fast RCNN的优化版本,二者主要的不同在于感兴趣区域的生成方法,Fast RCNN使用的是选择性搜索,而Faster RCNN用的是Region Proposal网络(RPN)。RPN将图像特征映射作为输入,生成一系列object proposals,每个都带有相应的分数。
下面是Faster RCNN工作的大致过程:
- 输入图像到卷积网络中,生成该图像的特征映射。
- 在特征映射上应用Region Proposal Network,返回object proposals和相应分数。
- 应用Rol池化层,将所有proposals修正到同样尺寸。
- 最后,将proposals传递到完全连接层,生成目标物体的边界框。
那么Region Proposal Network具体是如何工作的呢?首先,将CNN中得来的特征映射输入到Faster RCNN中,然后将其传递到Region Proposal Network中。RPN会在这些特征映射上使用一个滑动窗口,每个窗口会生成具有不同形状和尺寸的k个anchor box:
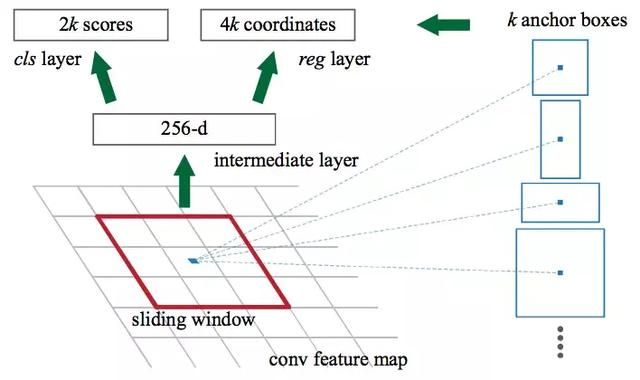
Anchor boxes是固定尺寸的边界框,它们有不同的形状和大小。对每个anchor,RPN都会预测两点:
- 首先是anchor就是目标物体的概率(不考虑类别)
- 第二个就是anchor经过调整能更合适目标物体的边界框回归量
现在我们有了不同形状、尺寸的边界框,将它们传递到Rol池化层中。经过RPN的处理,proposals可能没有所述的类别。我们可以对每个proposal进行切割,让它们都含有目标物体。这就是Rol池化层的作用。它为每个anchor提取固定尺寸的特征映射:
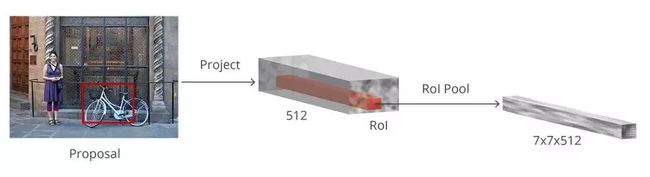
之后,这些特征映射会传递到完全连接层,对目标进行分类并预测边界框。
4.2 Faster RCNN的问题
目前为止,我们所讨论的所有目标检测算法都用区域来辨别目标物体。网络并非一次性浏览所有图像,而是关注图像的多个部分。这就会出现两个问题:
- 算法需要让图像经过多个步骤才能提取出所有目标
- 由于有多个步骤嵌套,系统的表现常常取决于前面步骤的表现水平
5. 上述算法总结
下表对本文中提到的算法做了总结:
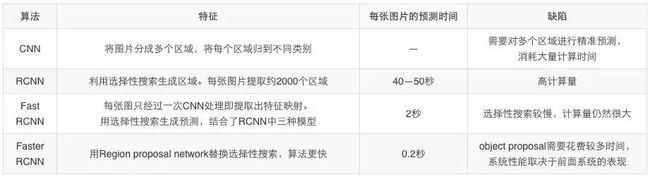
目标检测是很有趣的领域,在商业中也大有前景。得益于现代硬件和计算资源的发展,才能让这一技术有重要的突破。
本文只是目标检测算法的开门介绍,想了解更多的朋友可以直接私我。(关注主页)
如果你有不同见解也可直接在评论下方指教!