MySQL查询缓存详解(总结)
一、总结
一句话总结:
mysql查询缓存还是可以用用试一试,但是更推荐分布式,比如redis/memcache之流,将数据库中查询的数据和查询语句以键值对的方式存进分布式中
1、MySQL查询缓存 原理?
SELECT语句以及该语句的结果集组成的键值对
MySQL Query Cache是用来缓存我们所执行的SELECT语句以及该语句的结果集,MySql在实现Query Cache的具体技术细节上类似典型的KV存储,就是将SELECT语句和该查询语句的结果集做了一个HASH映射并保存在一定的内存区域中。当客户端发起SQL查询时,Query Cache的查找逻辑是,先对SQL进行相应的权限验证,接着就通过Query Cache来查找结果(注意必须是完全相同,即使多一个空格或者大小写不 同都认为不同,即使完全相同的SQL,如果使用不同的字符集、不同的协议等也会被认为是不同的查询而分别进行缓存)。它不需要经过Optimizer模块进行执行计划的分析优化,更不需要发生同任何存储引擎的交互,减少了大量的磁盘IO和CPU运 算,所以有时候效率非常高。
2、MySQL查询缓存 命中条件?
要完全一模一样:缓存存在一个hash表中,通过查询SQL,查询数据库,客户端协议等作为key.在判断是否命中前,MySQL不会解析SQL,而是直接使用SQL去查询缓存,SQL任何字符上的不同,如空格,注释,都会导致缓存不命中.
不确定数据不缓存:如果查询中有不确定数据,例如CURRENT_DATE()和NOW()函数,那么查询完毕后则不会被缓存.所以,包含不确定数据的查询是肯定不会找到可用缓存的
3、MySQL查询缓存 工作流程?
1. 服务器接收SQL,以SQL和一些其他条件为key查找缓存表(额外性能消耗)
2. 如果找到了缓存,则直接返回缓存(性能提升)
3. 如果没有找到缓存,则执行SQL查询,包括原来的SQL解析,优化等.
4. 执行完SQL查询结果以后,将SQL查询结果存入缓存表(额外性能消耗)
4、MySQL查询缓存 查看当前查询缓存相关参数状态?
SHOW VARIABLES LIKE '%query_cache%';
5、MySQL查询缓存 缓存数据失效时机?
表的结构或数据发生改变:在表的结构或数据发生改变时,查询缓存中的数据不再有效。有这些INSERT、UPDATE、 DELETE、TRUNCATE、ALTER TABLE、DROP TABLE或DROP DATABASE会导致缓存数据失效。所以查询缓存适合有大量相同查询的应用,不适合有大量数据更新的应用。
写入数据时缓存失效:当某个表正在写入数据,则这个表的缓存(命中检查,缓存写入等)将会处于失效状态.在Innodb中,如果某个事务修改了表,则这个表的缓存在事务提交前都会处于失效状态,在这个事务提交前,这个表的相关查询都无法被缓存.
6、mysql查询缓存的内存泄漏问题?
一个存储单元一个存储单元的占:MySQL需要设置单个小存储块的大小,在SQL查询开始(还未得到结果)时就去申请一块空间,所以即使你的缓存数据没有达到这个大小,也需要用这 个大小的数据块去存(这点跟Linux文件系统的Block一样).如果结果超出这个内存块的大小,则需要再去申请一个内存块.当查询完成发现申请的内存 块有富余,则会将富余的空间释放掉,这就会造成内存碎片问题
7、对于写频繁的系统,适合用mysql查询缓存么?
不适合:对于某些写频繁的系统,开启Query Cache功能可能并不能让系统性能有提升,有时反而会有下降。
原因是MySql为了保证Query Cache缓存的内容和实际数据绝对一致,当某个数据表发生了更新、删除及插入操作,MySql都会强制使所有引用到该表的查询SQL的Query Cache失效。对于密集写操作,启用查询缓存后很可能造成频繁的缓存失效,间接引发内存激增及CPU飙升,对已经非常忙碌的数据库系统这是一种极大的负 担。
二、MySQL查询缓存详解
转自或参考:MySQL查询缓存详解
https://www.cnblogs.com/Alight/p/3981999.html
一:缓存条件,原理
MySQL Query Cache是用来缓存我们所执行的SELECT语句以及该语句的结果集,MySql在实现Query Cache的具体技术细节上类似典型的KV存储,就是将SELECT语句和该查询语句的结果集做了一个HASH映射并保存在一定的内存区域中。当客户端发起SQL查询时,Query Cache的查找逻辑是,先对SQL进行相应的权限验证,接着就通过Query Cache来查找结果(注意必须是完全相同,即使多一个空格或者大小写不 同都认为不同,即使完全相同的SQL,如果使用不同的字符集、不同的协议等也会被认为是不同的查询而分别进行缓存)。它不需要经过Optimizer模块进行执行计划的分析优化,更不需要发生同任何存储引擎的交互,减少了大量的磁盘IO和CPU运 算,所以有时候效率非常高。
查询缓存的工作流程如下:
1:命中条件
缓存存在一个hash表中,通过查询SQL,查询数据库,客户端协议等作为key.在判断是否命中前,MySQL不会解析SQL,而是直接使用SQL去查询缓存,SQL任何字符上的不同,如空格,注释,都会导致缓存不命中.
如果查询中有不确定数据,例如CURRENT_DATE()和NOW()函数,那么查询完毕后则不会被缓存.所以,包含不确定数据的查询是肯定不会找到可用缓存的
2:工作流程
1. 服务器接收SQL,以SQL和一些其他条件为key查找缓存表(额外性能消耗)
2. 如果找到了缓存,则直接返回缓存(性能提升)
3. 如果没有找到缓存,则执行SQL查询,包括原来的SQL解析,优化等.
4. 执行完SQL查询结果以后,将SQL查询结果存入缓存表(额外性能消耗)
二:缓存参数
1:查看当前查询缓存相关参数状态:
SHOW VARIABLES LIKE '%query_cache%';

2:缓存配置参数解释
1. query_cache_type: 查询缓存类型,是否打开缓存
可选项
a、0(OFF):关闭 Query Cache 功能,任何情况下都不会使用 Query Cache;
b、1(ON):开启 Query Cache 功能,但是当SELECT语句中使用SQL_NO_CACHE提示后,将不使用Query Cache;
c、2(DEMAND):开启Query Cache 功能,但是只有当SELECT语句中使用了SQL_CACHE 提示后,才使用Query Cache。
备注1:
如果query_cache_type为on而又不想利用查询缓存中的数据,可以用下面的SQL:
SELECT SQL_NO_CACHE * FROM my_table WHERE condition;
如果值为2,要使用缓存的话,需要使用SQL_CACHE开关参数:
SELECT SQL_CACHE * FROM my_table WHERE condition;
2. query_cache_size: 缓存使用的总内存空间大小,单位是字节,这个值必须是1024的整数倍,否则MySQL 会自动调整降低最小量以达到1024的倍数;(感觉这个应该跟文件系统的blcok大小有关)
3. query_cache_min_res_unit: 分配内存块时的最小单位大小,设置查询缓存Query Cache每次分配内存的最小空间大小,即每个查询的缓存最小占用的内存空间大小;
4. query_cache_limit: 允许缓存的单条查询结果集的最大容量,默认是1MB,超过此参数设置的查询结果集将不会被缓存;
5. query_cache_wlock_invalidate: 如果某个数据表被锁住,是否仍然从缓存中返回数据,默认是OFF,表示仍然可以返回
控制当有写锁定发生在表上的时刻是否先失效该表相关的Query Cache,如果设置为 1(TRUE),则在写锁定的同时将失效该表相关的所有Query Cache,如果设置为0(FALSE)则在锁定时刻仍然允许读取该表相关的Query Cache。
GLOBAL STAUS 中 关于 缓存的参数解释:
Qcache_free_blocks: 缓存池中空闲块的个数
Qcache_free_memory: 缓存中空闲内存量
Qcache_hits: 缓存命中次数
Qcache_inserts: 缓存写入次数
Qcache_lowmen_prunes: 因内存不足删除缓存次数
Qcache_not_cached: 查询未被缓存次数,例如查询结果超出缓存块大小,查询中包含可变函数等
Qcache_queries_in_cache: 当前缓存中缓存的SQL数量
Qcache_total_blocks: 缓存总block数
3:设置配置参数:
SET GLOBAL query_cache_size = 134217728;
4:查看缓存命中次数(是个累加值):
SHOW STATUS LIKE 'Qcache_hits'
三:缓存数据失效时机
1:
在表的结构或数据发生改变时,查询缓存中的数据不再有效。有这些INSERT、UPDATE、 DELETE、TRUNCATE、ALTER TABLE、DROP TABLE或DROP DATABASE会导致缓存数据失效。所以查询缓存适合有大量相同查询的应用,不适合有大量数据更新的应用。
当某个表正在写入数据,则这个表的缓存(命中检查,缓存写入等)将会处于失效状态.在Innodb中,如果某个事务修改了表,则这个表的缓存在事务提交前都会处于失效状态,在这个事务提交前,这个表的相关查询都无法被缓存.
2:清理查询缓存 & 减少碎片策略
FLUSH QUERY_CACHE; 清理查询缓存内存碎片
RESET QUERY_CACHE; 从查询缓存中移出所有查询
FLUSH TABLES; 关闭所有打开的表,同时该操作将会清空查询缓存中的内容
1. 选择合适的block大小
2. 使用 FLUSH QUERY CACHE 命令整理碎片.这个命令在整理缓存期间,会导致其他连接无法使用查询缓存
PS: 清空缓存的命令式 RESET QUERY CACHE
四:缓存的内存管理
缓存会在内存中开辟一块内存(query_cache_size)来维护缓存数据,其中有大概40K的空间是用来维护缓存的元数据的(什么是元数据:http://www.cnblogs.com/Alight/p/3982086.html),例如空间内存,数据表和查询结果的映射,SQL和查询结果的映射等.
MySQL将这个大内存块分为小的内存块(query_cache_min_res_unit),每个小块中存储自身的类型,大小和查询结果数据,还有指向前后内存块的指针.
MySQL需要设置单个小存储块的大小,在SQL查询开始(还未得到结果)时就去申请一块空间,所以即使你的缓存数据没有达到这个大小,也需要用这 个大小的数据块去存(这点跟Linux文件系统的Block一样).如果结果超出这个内存块的大小,则需要再去申请一个内存块.当查询完成发现申请的内存 块有富余,则会将富余的空间释放掉,这就会造成内存碎片问题,见下图
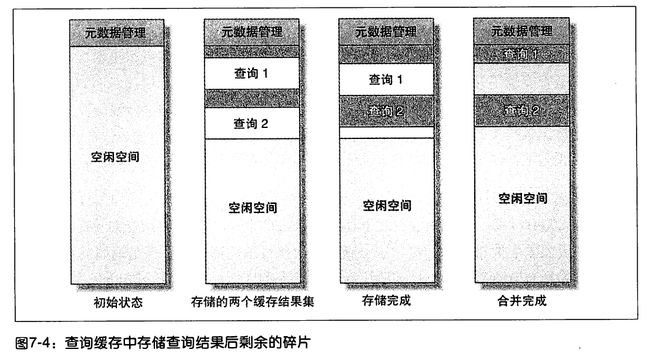
此处查询1和查询2之间的空白部分就是内存碎片,这部分空闲内存是有查询1查询完以后释放的,假设这个空间大小小于MySQL设定的内存块大小,则无法再被使用,造成碎片问题
在查询开始时申请分配内存Block需要锁住整个空闲内存区,所以分配内存块是非常消耗资源的.注意这里所说的分配内存是在MySQL初始化时就开辟的那块内存上分配的.
五:缓存的使用时机 & 性能
衡量打开缓存是否对系统有性能提升是一个很难的话题
1. 通过缓存命中率判断, 缓存命中率 = 缓存命中次数 (Qcache_hits) / 查询次数 (Com_select)
2. 通过缓存写入率, 写入率 = 缓存写入次数 (Qcache_inserts) / 查询次数 (Qcache_inserts)
3. 通过 命中-写入率 判断, 比率 = 命中次数 (Qcache_hits) / 写入次数 (Qcache_inserts), 高性能MySQL中称之为比较能反映性能提升的指数,一般来说达到3:1则算是查询缓存有效,而最好能够达到10:1
任何事情过犹不及,尤其对于某些写频繁的系统,开启Query Cache功能可能并不能让系统性能有提升,有时反而会有下降。原因是MySql为了保证Query Cache缓存的内容和实际数据绝对一致,当某个数据表发生了更新、删除及插入操作,MySql都会强制使所有引用到该表的查询SQL的Query Cache失效。对于密集写操作,启用查询缓存后很可能造成频繁的缓存失效,间接引发内存激增及CPU飙升,对已经非常忙碌的数据库系统这是一种极大的负 担。
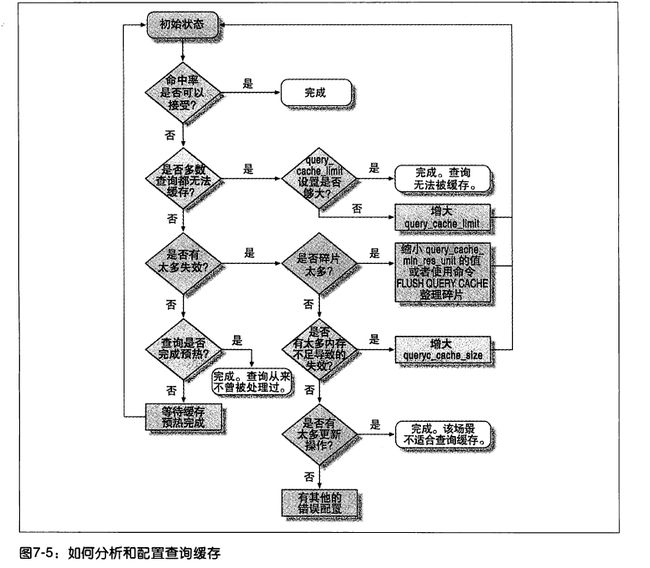
六:查询缓存问题分析
七:InnoDB与查询缓存
Innodb会对每个表设置一个事务计数器,里面存储当前最大的事务ID.当一个事务提交时,InnoDB会使用MVCC中系统事务ID最大的事务ID跟新当前表的计数器.
只有比这个最大ID大的事务能使用查询缓存,其他比这个ID小的事务则不能使用查询缓存.
另外,在InnoDB中,所有有加锁操作的事务都不使用任何查询缓存
八、其他
Query Cache因MySql的存储引擎不同而实现略有差异,比如MyISAM,缓存的结果集存储在OS Cache中,而最流行的InnoDB则放在Buffer Pool中。