谷歌Nature论文alphaGo Zero: Mastering the game of Go without human knowledge论文详解
背景:谷歌的阿尔法围棋算法(AlphaGo)是第一个击败人类职业围棋选手、第一个战胜围棋世界冠军的人工智能机器人,由谷歌(Google)旗下DeepMind公司戴密斯·哈萨比斯领衔的团队开发。其主要工作原理是“深度学习(deep learning)”。2017年,谷歌推出了Alpha Zero,通过强化学习(reinforcement learning)的方法,在不依赖人类经验的基础和击败了AlphaGo。
目的:解析AlphaZero的论文。
目录
一、概览
1.1 动机
1.2 贡献点
强化学习的实现
仅用黑白子作为输入特征
单一网络
二、方法
2.1 围棋与AlphaZero的公式描述
2.2 训练方法
2.3 MCTS算法
2.4 训练过程
公式描述
MCTS得到的监督信息
监督信息与loss function
三、实验
3.1 训练平台与方法
谷歌的TPU
训练过程
3.2 与AlphaGO的对比
3.3 AlphaZero围棋棋力
四、结论与个人总结
一、概览
Nature上的论文结构与平时看的机器学习领域的会议论文的结构很不一样,我参照相关技术论文的结构来解析这篇文章。
1.1 动机
- 人工智能的一大挑战是机器是否可以在挑战性的领域,从白板状态学起,达到或者超过人类的状态。近期的AlphaGo就是通过树查找算法和深度学习网络击败的人类。
- 专家数据集非常昂贵,不易得到。
- 监督学习会达到一个天花板,这个天花板就是已有的训练集的能力的顶峰。
1.2 贡献点
强化学习的实现
- AlphaGo:通过监督学习(supervised learning),学习人类棋谱。
- AlphaZero:通过强化学习(Reinforcement learning)的方法, 只从游戏规则之中学习。完全不依靠人类知识。
仅用黑白子作为输入特征
AlphaGo需要输入一系列的特征作为特征给深度网络进行分类
而AlphaZero仅仅需要黑白子的位置作为特征进行输入。
单一网络
仅仅需要一个单一网络来实现相应的步数,而不用像AlphaGo一样用分开的policy Network和Value Network
二、方法
2.1 围棋与AlphaZero的公式描述
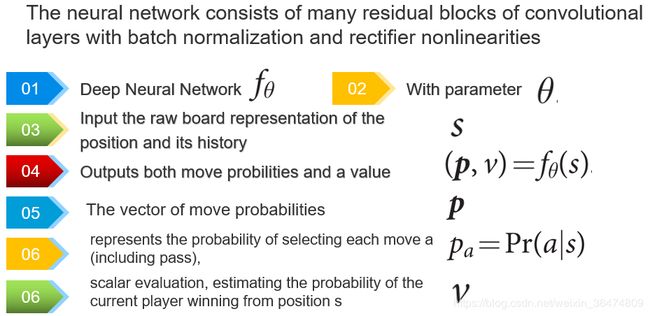
- 首先我们定义一个神经网络fθ
- 它的网络参数(权重)为θ
- 当前的棋盘状态(加上过去的棋盘状态)表示为s
- 所以网络根据棋盘状态得到的输出为(p,v)=fθ(s)
- 其中p表示采用每一个围棋动作a之后的概率Pa=Pr(a|s)
- 值v是一个估计值,用来估测当前状态s下的胜率
-
AlphaZero采用的强化学习的训练算法
所以alphaZero的神经网络结合了alphaGo的policy Netwrok和value Network这两个网络为一个网络。
alphaZero的神经网络可以视为一个 ResNet,因为其组成为residual block组成的卷积层和batch normalization,和rectifier nonlinerarties
2.2 训练方法
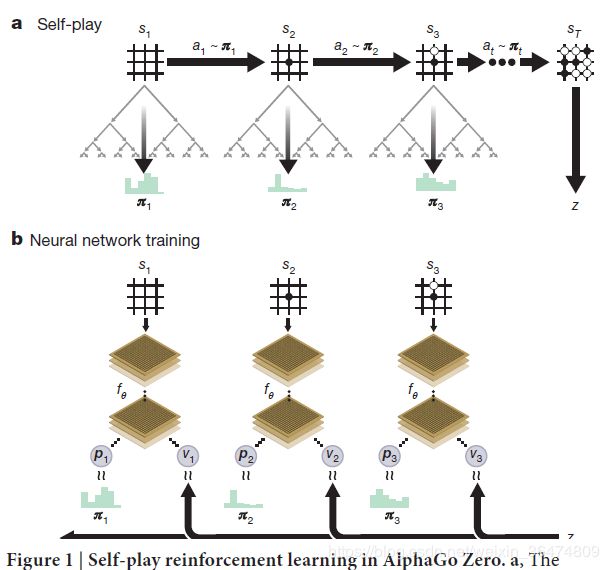
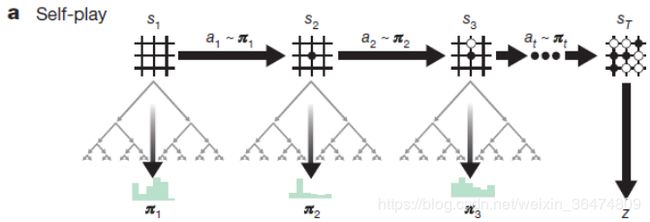
alphaZero通过自我博弈的方法,运用强化学习的算法实现相应的网络
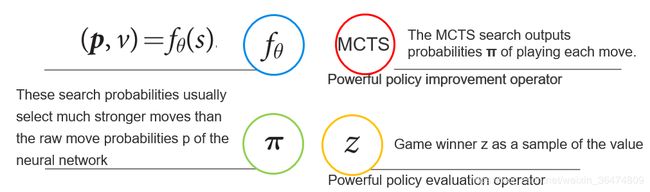
- 在棋盘状态s之下,MCTS(Monte Carlo Tree Search蒙特卡洛树搜索算法)会被执行,它的作用是输出一个当前的希望的棋盘动作的概率π
- π是一个比原始的神经网络的p=fθ(s)的输出更强的一个监督信息。
这里我们理一下思路,即运用强化学习的方法,运用MCTS算法得出了一个棋盘动作概率π,这个概率的可靠性比神经网络通过其参数自己预测的强。
通过自学习加上搜索的方法,MCTS来选择每一个动作,从而选出最后的游戏胜家z,z可以看作一个非常好的强化学习的policy evaluation operator。
![]()
我们希望网络的输出(p,v)=fθ(s)尽量的接近MCTS算法锁所得到的(π,z)
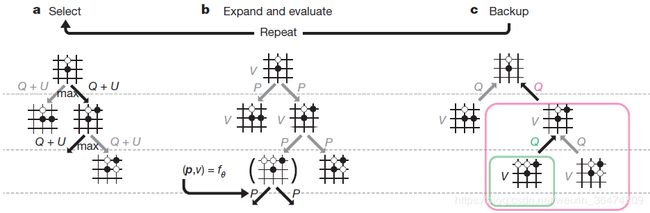
2.3 MCTS算法
MCTS(Monte Carlo Tree Search蒙特卡洛树搜索算法)在alphaGo与alphaZero之中非常重要,后面会给出详细的解析。
https://www.jianshu.com/p/d011baff6b64
https://blog.csdn.net/ljyt2/article/details/78332802
https://www.cnblogs.com/xmwd/p/python_game_based_on_MCTS_and_UCT_RAVE.html
蒙特卡洛树查找算法
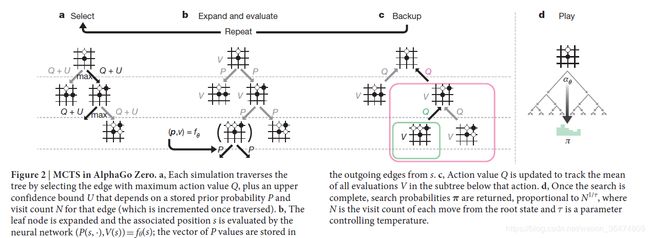
2.4 训练过程
公式描述
首先,网络会被初始化相应的参数θo,在每一次子迭代的过程中,迭代次数被认为 i >1, 通过自我下棋的棋盘动作就产生了。
在每一个棋盘时刻 t 的时候,MCTS算法都会被执行,![]()
MCTS运用的算法是 i-1 迭代时候的神经网络。![]()
从而获得该时刻的棋盘动作可能性 ![]()
MCTS得到的监督信息
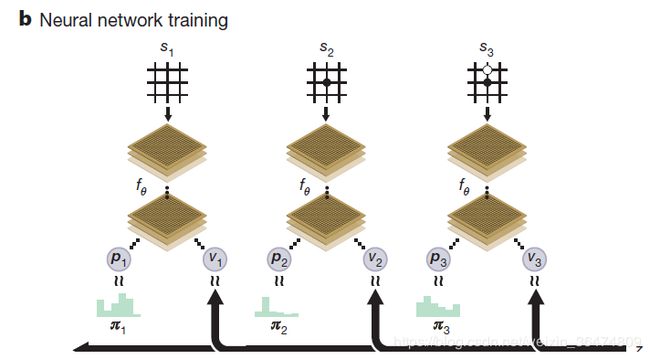
这里我们可以看出来,MCTS运用前一次迭代的神经网络来搜索步数,得到这一次迭代的神经网络的训练信息。所以,MCTS通过搜索相应的算法达到了神经网络棋力的提升,用提升后的信息作为新的训练信息给神经网络,从而保证神经网的棋力一直提升,从而达到网络的收敛。
当搜索的可执行步骤search value低于某个阈值的时候,或者棋局大于某一个长度的时候,该场对局会被给出一个最终的reward
![]()
此前每一个 t 时刻的步数都会被记录下来:![]()
注意这个变量是MCTS算法的出来的。
监督信息与loss function
网络的权重 θi 会被从上面MCTS得到的数据 ![]()
这个数据之中进行训练,然后神经网络的希望尽量的让p接近π,v接近z
用上面那个信息来作为监督信息更新网络的权重![]()
相应的loss值为最小均方值误差和交叉熵,如下面这样:
![]()
三、实验
3.1 训练平台与方法
谷歌的TPU
据Google称,每个云端TPU都由四个定制的ASIC构成,每个板卡可以提供高达180 teraflops(TFLOPS)的浮点性能和64 GB的高带宽内存。作为对比,目前市面上广泛试用的英伟达Tesla P100 GPU性能则为每秒21 teraflops(TFLOPS),即便是最新发布的V100也只是刚刚突破100 teraflops(TFLOPS)的大关。
训练过程
Over the course of training, 4.9 million games of self-play were generated,using 1,600 simulations for each MCTS, which corresponds to approximately 0.4 s thinking time per move. Parameters were updated from 700,000 mini-batches of 2,048 positions. The neural network contained 20 residual blocks (see Methods for further details).
训练过程之中,运行了4,900,000场自己跟自己下棋,MTCS算法运用了1600个simulations,基本相当于0.4秒想一步。参数运用700,000 个mini-batch来更新2048个棋盘位置。相应的网络具有20个残差单元。
3.2 与AlphaGO的对比
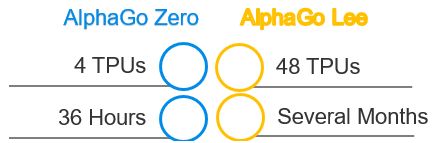
alphaZero仅用36小时就超过了alphaGo,并且占用平台很少,只需要4个TPU。然后以100:0战胜了之前的alphaGo。

首先解释下不同颜色的dual,sep,conv,res的作用。
- sep表示采用alphaGo的方法,两个policy network与value netwrok分开并行
- dual表示用同一个网络来预测相应的值
- res表示采用resnet的结构
- conv表示运用卷积神经网络的结构
从左往右三个图的表示:
a . Elo rating是一种棋力分析的算法,https://blog.csdn.net/houzhuoming1/article/details/50541415,
此算法用于预测相应软件或者人的棋力。
b .表示用于预测人类专业选手的步数的准确率(采用围棋的GoKifu数据集)
c. MSE最小均方值误差,用于确定人类专业的游戏输出。
从这些实验我们都可以看出采用zlphaZero采用的网络结构是最好的,即一个独立的resnet
3.3 AlphaZero围棋棋力
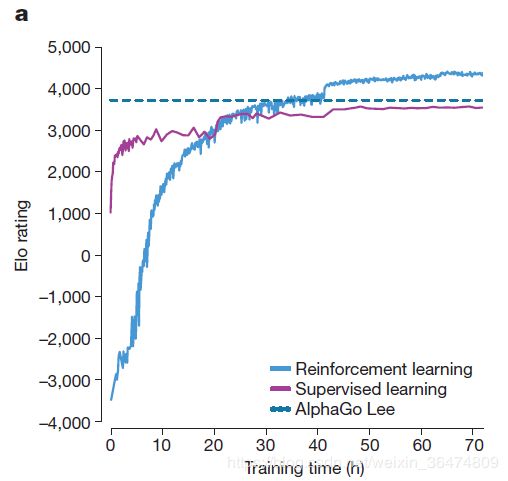
虚线可以看作现在人类水平的最高水平,也是数据集的最高水平。
从此实验可以看出监督学习的方法,只能收敛到人类的最高水平,而通过强化学习的方法可以突破数据集的极限。
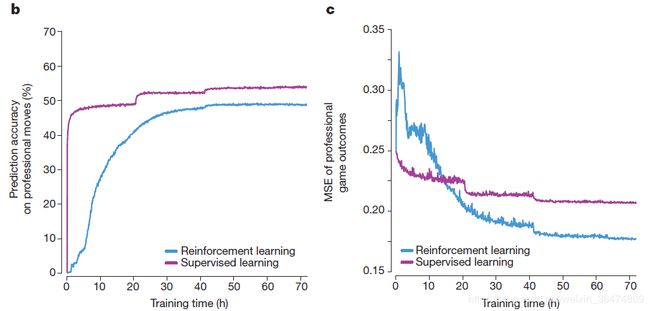
这张图显示了预测人类棋手的准确度。我们看到监督学习的方法能很好的学习人类棋手的行为,但是alphaZero的预测准确率就没有那么高。
第二张图是预测人类棋手行为的最小均方值误差(MSE)此处得到了看似矛盾的结果
为什么预测精度与MSE反而相反?暂时猜测为评测方法不同带来的不同,后续我们需要详细研究给出相应解释。
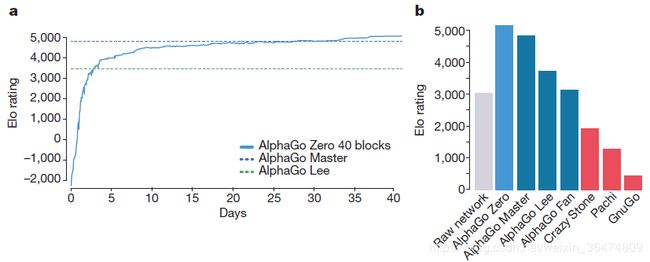
这张图显示着随着训练时间的增加,alphaZero的棋力与其他棋力的对比。
四、结论与个人总结
- 强化学习具有非常强大的能力,即使在很具有挑战性的围棋领域,没有人类的指引,alphaZero依然可以从白板学起很快达到很好的水平。
- 强化学习的方法需要的时间与运算消耗比监督学习更少并且达到了更好的效果。
- 人类从millions的博弈之中上千年积累起来的围棋知识,在几天之内被alphaZero超越。
- 最新的研究领域不难读懂,google依托强大的算法和算力支持,就能取取得非常好的效果。