spark代码 spark-submit提交yarn-cluster模式
worldcount yarn-cluster集群作业运行
之前写的是一个windows本地的worldcount的代码,当然这种功能简单 代码量少的 也可以直接在spark-shell中直接输scala指令。
但是在项目开发 企业运用中,因为本地的资源有限 使得无法发挥出spark的真正优势。因此 在这里 我就spark代码在集群中运行 做一些补充讲述。
我使用的环境是: idea编译器 jdk1.7 scala 2.10 spark 1.6.0(因为公司服务器普遍搭建的还是cdh5.15集群,上面的spark版本是旧时的1.6.0版本 2.x上面的一些功能不能使用 例如SparkSession Spark.ml包 这里还需要注意一点的是在maven打包时 如果编译打包的环境是jdk1.8有可能会出现打包不成功 这是因为jdk与scala二者版本不兼容导致 建议读者将jdk换成1.7 或者提高scala版本)
1. 首先搭建idea maven环境 添加相应依赖
关于idea中配置maven环境之类的,还有什么jdk之类的搭建,南国在这里就不做篇幅说明了。 这些属于基本操作,不熟悉操作的网上有许多资料,比较简单。
这里我主要给出项目所需要的pom.xml配置
4.0.0
Huawei
Spark
1.0-SNAPSHOT
1.7
1.7
UTF-8
1.6.0-cdh5.15.0
2.10
org.apache.spark
spark-core_${scala.version}
${spark.version}
org.apache.spark
spark-streaming_${scala.version}
${spark.version}
org.apache.spark
spark-sql_${scala.version}
${spark.version}
org.apache.spark
spark-hive_${scala.version}
${spark.version}
org.apache.spark
spark-mllib_${scala.version}
${spark.version}
net.alchim31.maven
scala-maven-plugin
3.2.2
org.apache.maven.plugins
maven-compiler-plugin
3.5.1
net.alchim31.maven
scala-maven-plugin
scala-compile-first
process-resources
add-source
compile
scala-test-compile
process-test-resources
testCompile
org.apache.maven.plugins
maven-compiler-plugin
compile
compile
org.apache.maven.plugins
maven-shade-plugin
2.4.3
package
shade
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
这里 我强调在pom.xml中比较重要的地方:
properities:重要的属性 我们可以将所添加依赖所属的版本添加进去
dependency: 依赖 也就是项目具体所要调用的库文件 包等
plugins: 插件 这里我主要配置的是打包scala java程序所需要的Maven插件
2. scala程序编写并打包到集群中运行
源代码:
package com.xjh
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by xjh on 2019/7/15.
*/
object wc {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("wc")
val sc=new SparkContext(conf)
val wc=sc.textFile(args(0)).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
// wc.foreach(print)
wc.saveAsTextFile(args(1))
sc.stop() //释放资源
}
}
注意:写提交到集群中的程序代码最好在放在指定的包中,idea和eclipse不同 程序默认编写在Main下面,程序代码前是没有包名的,这种情况下 当你打包提交到spark-submit中运行时,程序难以正确都找到你想要运行代码的类名,而且 当你项目中的代码越写越多时,就越难以分清。 所以,何不将你的代码放在某个特定包名下了。
Maven打包:
如果你代码所在的项目工程之前 已经打包过,首先进行clean
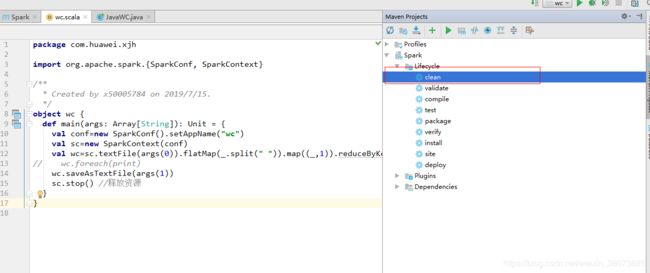
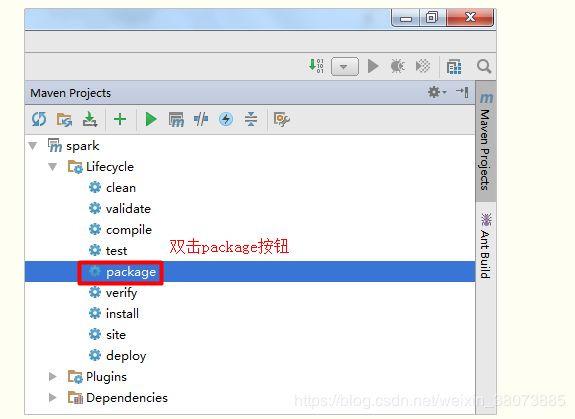
然后点击package进行打包,网上对于在idea中打包的方法有几种,但其他方法过程太过繁琐 啰嗦,直接双击package进行打包
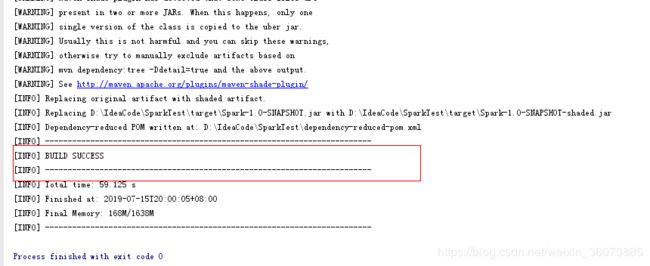
在console中显示BUILD SUCCESS表示打包成功,我们在项目工程的路径中target即可找到你刚才打包成功的jar。 如果显示的BUILDFAILURE则说明打包中出现了报错,努力找原因去把他解决,你一定没问题的!!

上传到yarn集群运行
首先我们查看一下集=集群上的Spark版本及其配置的环境,如下图所示:
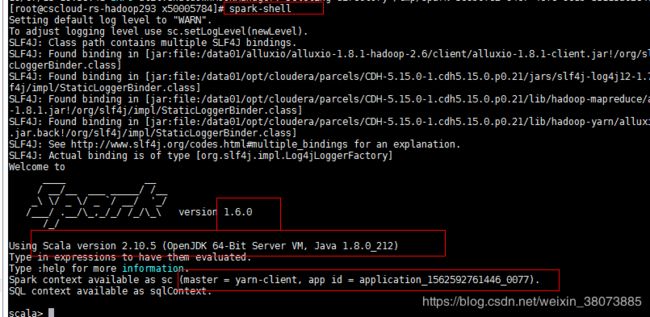
我在上图标红的几处 读者细看,关于集群中的配置 可借鉴。
yarn-client模式主要用于本地测试,client在本地 运行日志可直接在本地看到;
yarn-cluster真正的集群模式,这也是我们在日常应用中最常用的集群模式。聪明的你可能说 spark不是还有standalone集群模式,是的,但是standalone是spark自身的集群模式,他和其他mapreduce hive zookeeper等常用的大数据服务是分开的。在应用中,我们一般使用yarn作为大数据集群的资源管理,毕竟yarn模式是现在最常用的。
具体的操作:
- 首先将jar传输到linux系统上,这个根据你自己所用的shell远程登录的工具相关搜索一下 就行。传输的原理 就是ftp协议。这里我使用的MobaXterm, 他直接将所传输的文件 直接拖到linux中

- 确保你的集群正常启动,提前设置好输入 输出路径 在spark-submit中提交作业
这里 确保你的hadoop saprk服务正常启动
然后在spark-submit中提交作业
spark-submit --master yarn --deploy-mode cluster --driver-memory 500m --executor-memory 500m --executor-cores 1 --class com.huawei.xjh.wc /home/x50005784/Spark-1.0-SNAPSHOT.jar hdfs://cscloud-rs-hadoop293.com:8020/user/x50005784/test.txt hdfs://cscloud-rs-hadoop293.com:8020/user/x50005784/output
这里简要说明指令的含义:
–master 运行模式
–driver-memory 内存大小
–executor-memory –executor-cores 执行器设置
–class 代码所在的类
后面两个为代码中的两个输入路径
![]()
系统运行直到提示SUCCEEDED
我们还可以在yarn管理资源的8088看到我们在运行的spark作业
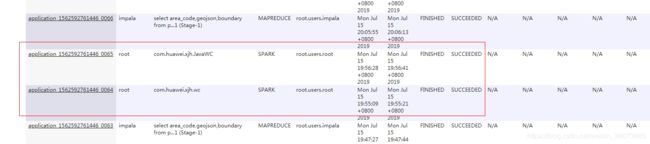
3. 登录HDFS查看结果文件

Java程序编写并打包到集群中运行
scala代码在集群中成功运行之后,实现Java代码的集群运行运行 就变得简单多了。相比较于scala代码而言,Java代码看上去就显得有些累赘 但是现在的企业运用中 前端 后台使用Java的居多,在日常应用中 Java也是必须要掌握的。
我们在同一项目中新建Java类
编写Java代码:
package com.huawei.xjh;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
/**
* Created by xjh on 2019/7/15.
*/
public class JavaWC {
public static void main(String[] args) {
SparkConf conf=new SparkConf().setAppName("JavaWC");
JavaSparkContext jsc=new JavaSparkContext(conf);
final JavaRDD lines=jsc.textFile(args[0]);
JavaRDD wc=lines.flatMap(new FlatMapFunction() {
@Override
public Iterable call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
JavaPairRDD ones=wc.mapToPair(new PairFunction() {
@Override
public Tuple2 call(String s) throws Exception {
return new Tuple2(s,1);
}
});
JavaPairRDD counts=ones.reduceByKey(new Function2() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
});
counts.saveAsTextFile(args[1]);
jsc.stop(); //释放资源
}
}
Java代码的逻辑 和上述的scala意义一样,只是代码实现有些不同。所以 我在这里没有写什么注释
后续的打包过程和上述scala一样,只不过 在spark-submit中记得修改成为Java所在的类和包名。