J.P. Morgan首发川普指数:效果如何?量化看看!

标星★公众号 爱你们♥
作者:Nick Cochrane、JPMorgan、CNBC
编译:1+1=6 | 公众号海外部
近期原创文章:
♥ 5种机器学习算法在预测股价的应用(代码+数据)
♥ Two Sigma用新闻来预测股价走势,带你吊打Kaggle
♥ 2万字干货:利用深度学习最新前沿预测股价走势
♥ 机器学习在量化金融领域的误用!
♥ 基于RNN和LSTM的股市预测方法
♥ 如何鉴别那些用深度学习预测股价的花哨模型?
♥ 优化强化学习Q-learning算法进行股市
♥ WorldQuant 101 Alpha、国泰君安 191 Alpha
♥ 基于回声状态网络预测股票价格(附代码)
♥ 计量经济学应用投资失败的7个原因
♥ 配对交易千千万,强化学习最NB!(文档+代码)
♥ 关于高盛在Github开源背后的真相!
♥ 新一代量化带货王诞生!Oh My God!
♥ 独家!关于定量/交易求职分享(附真实试题)
♥ Quant们的身份危机!
♥ AQR最新研究 | 机器能“学习”金融吗?
CP(川普)在Tw(Twitter)真的是:
一顿分析猛如虎,涨跌全看特朗普。
夜里挑灯看线,开盘一看白练。
这也诞生了一个新词:
一推就倒
▍形容一条Tw就吓得屁滚尿流,崩溃倒下的东西,多用于股市。
必看!
2017年5月30日,CP在Tw上创造了一个新词“Covfefe”,引发了推特上三千万粉丝的关注。正常人的反应是,“我怀疑他的的手滑了一下。
就在Covfefe一词在Tw上被炒得沸沸扬扬的时候,CP悄悄把那条推文给删除了。取而代之的是一条新的推文。
2017年5月31日凌晨,CP在社交平台推特上写道:“尽管持续的负面媒体Covfefe”(Despite the constant negative press Covfefe)。
2017年5月31日上午6时左右,CP发现自己一不小心成了全民话题之后,再次发声:“谁能猜到covfefe的真实含义???玩得开心!”
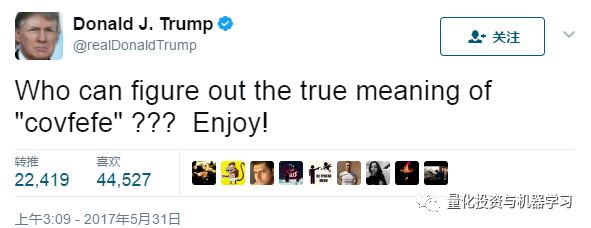


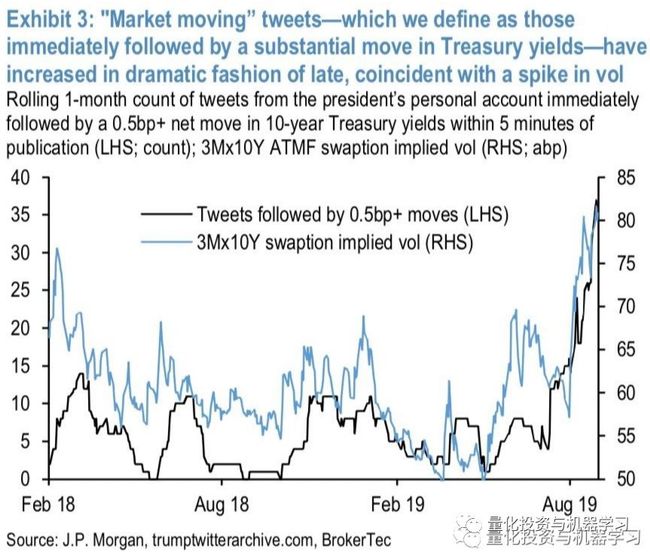
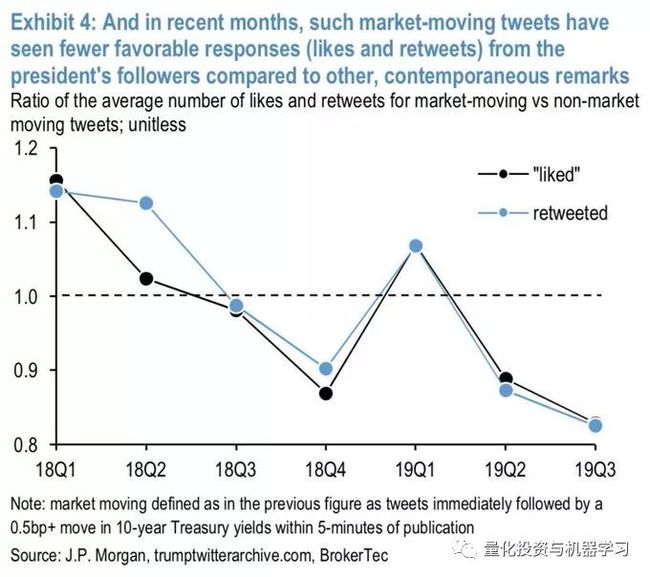
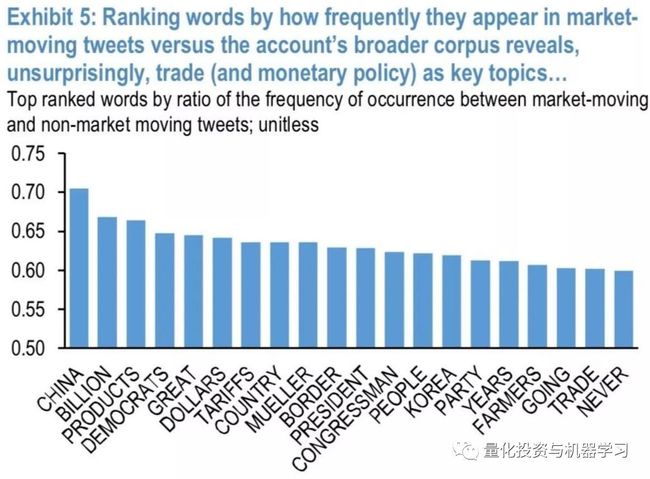
然而,从2018年末开始,活动大幅增加。事实上,过去四年来推特的最高数量出现在最近几个月。

此外,CP的推文大多在中午到下午2点之间发布,下午1点发布的推文大约是下午或晚上其他时间发布的推文的3倍。
研究发现:CP凌晨3:00的推文比下午3:00的推文更多,这对MG利率市场来说是个麻烦,因为隔夜市场的流动性令人担忧。
根据Bank of America Merrill Lynch在9月初编制的数据显示:
在过去3年里,CP每天发布超过35条Tw的日子里,市场平均下跌了9个基点。 在CP每天发布Tw不到5条的日子里,市场平均上涨了5个基点。

当CP在Tw上更加活跃的时候,市场通常会下跌。 当CP推文减少时,市场往往会上涨!
还有一个有趣的发现:CP大概是从早上5:00睡到上午10:00,因为在这段时间里他的Twter没有什么动静。
5、尽管CP的Tw活跃度有很大的上升,但很多来自于转发他人Tw。尽管如此,摩根大通的结论任然表示,CP的Tw对市场的波动性有很大的统计意义。
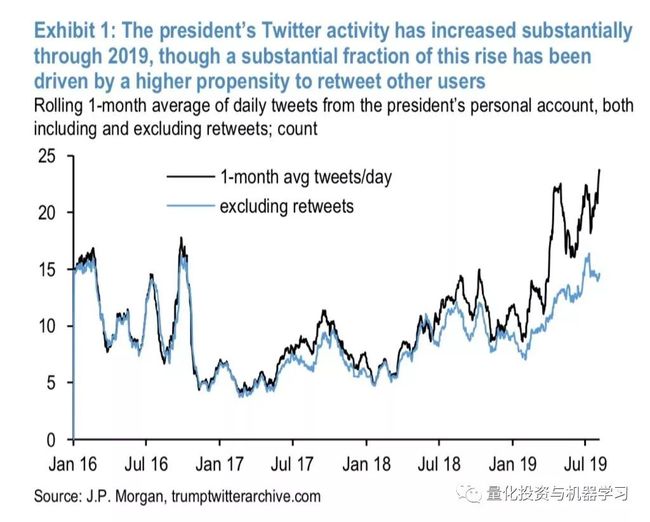
下面我们来做一个简单的策略:
标普500指数交易策略能否利用CP的推文来预测市场的短期波动呢?我们今天就从主题模型和情感分析来寻找答案。
时间:2017年1月21日上任第一天到2019年8月14日。
共收集了7779条CP的推文。
使用 Gensim 和 nltk Python库执行了以下预处理步骤:
1、少于20个字符(总共375条推文)的推文被视为噪音数据,进行删除操作。
2、推文被标记化,句子被分割成单个的单词,单词全部小写,标点符号被删除。
3、使用 nltk 的默认Stop Words(停用词),及自定义停用词。确定自定义停用词的过程是可以反复进行的,包括诸如“fake, news, James Comey, Puerto Rico等”的词语。这些词主导着与主题无关的推文。
4、词被进行简化,将每个单词缩减到它最基本的形式。
5、后来为主题建模制作了Bigrams。选择Bigrams来捕捉围绕单个词组的上下文。
Bigrams是为了自动探测出文本中的新词,基于词汇之间的共现关系—如果两个词经常一起毗邻出现,那么这两个词可以结合成一个新词,比如“数据”、“产品经理”经常一起出现在不同的段落里,那么,“数据_产品经理”则是二者合成出来的新词,只不过二者之间包含着下划线。
6、最后,为了使数据更友好,创建了一个单词字典包,其中详细描述了一个单词在所有Tw中出现的次数。Gensim还需要一个语料库:为每条Tw创建一个词典,其中包含在Tw中出现的单词数量和每个单词在Tw中出现的次数。
预处理Tw的例子,经过 lemmmization 和 bigram 阶段:

经过预处理后,将语料库和词包字典传递给一个LDA模型。简单地说,LDA 可以用来为给定的推文主题建立概率分布模型。
例如,考虑这样一个例子:LDA 认为一条Tw有50%的可能与trade有关,25%的可能与移民有关,25% 的可能与医疗保健有关。考虑到这条推文的主题概率分布,以及与trade话题的相关性最大,这条推文可以被归类为与trade有关的。
为 LDA 模型指定的主要超参数是主题的数量。经过多次测试和一些对主题适当分离的主观判断,30个主题产生了最好的结果。
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus,id2word=id2word,
num_topics=30, passes = 10)
我们使用pyLDAvis来可视化模型分离主题的能力。下面的主题间距离图显示了一些主题之间的轻微重叠,但总的来说,该模型表现出了令人满意的分离程度。

一旦我们找到了与主题9对应的先关Tw,最后只剩下590条。上面的例子和推文的子集表明,LDA 模型在识别与MY有关的推文方面是十分准确的。下面我们进行情感分析的建模。
我们使用 Valence Aware Dictionary 和 Sentiment Reasoner (VADER)分析来生成情绪的交易信号。 Vader是一个预先训练好的情感模型,在社交媒体文本上特别有效。 建立Vader模型并下载现有的词典简直就是小菜一碟。
Vader是一种基于词库和语法规则来进行文本情感识别的方法,发表于2014年的AAAI会议。
Github地址:
https://github.com/cjhutto/vaderSentiment
from nltk.sentiment.vader import SentimentIntensityAnalyzer
analyser = SentimentIntensityAnalyzer()
nltk.download('vader_lexicon')
sia = SentimentIntensityAnalyzer()
Vader接受一个文本字符串作为输入,并返回正、中性、负和复合的情感得分。重点放在检查复合得分上,它很好地包装了文档的总体情绪。复合分数范围从 -1(极度负值)到1(极度正值)。在下面的例子中,Vader给出了0.8439的综合得分。
收集了所有与MY有关推文的综合得分。为了识别那些在短期内对市场有最大影响力的推文,我们将具有大量证明或消负面情绪的推文拎出来。
正面:复合得分0.7
负面:复合得分-0.7
没有达到情绪分界线的推文会被删除,因此最终的数据子集只有194条推文,这些推文的情绪得分都很高。
我们开发了一个简单的自定义交易情绪策略,用于对标普500指数进行回测。在深入研究交易逻辑的细节之前,我们首先做出一些假设:
回测仅限于在市场开盘或收盘时进行。理想的情况是,一旦CP的推特账号进行分析后触发买卖信号,则立马进行交易。
如果一天内产生多个信号,信号的平均值决定交易的方向。
手续费没有考虑。
比较基准是一个简单的买入并持有SPY策略。
在实际中,我们一定是要考虑交易成本的(手续费等)。
每日交易策略逻辑的基本情况如下:
基本情况:
没有交易信号
正面情绪信号:
信号出现在开盘前:开盘时买进,收盘时卖出
信号出现在交易时段:收盘时买进,明天收盘时卖出
信号出现在收盘后:明天开盘时买进,明天收盘时卖出
负面情绪信号:
信号出现在开盘前:开盘时卖出
信号出现在交易时段:收盘时卖出
信号出现在收盘后:明天开盘时卖出
让我们看看交易策略在2017年1月21日至2019年8月14日的回测表现。在下图中,策略用蓝线表示,基准用灰线表示。此外,绿色箭头表示触发买入信号的日期,红色箭头表示触发卖出信号的日期。

在回测期间,该策略的收益率为85.3% ,而在同一时期,基准为56.7% !虽然回测的结果是OK的,但让我们花点时间来考虑为什么该策略优于其基准,并讨论回测的局限性。
大多数买入信号是在市场上涨趋势中产生的,而卖出信号则是在小幅抛售时产生的,然而,这种策略也有可能只是运气好。
CP的情绪是否真的导致了市场的波动?或者这些推文只是与其他市场变动事件如经济数据发布或Federal Reserve的讲话有关? 我们刚才的策略是为了看看利用CP的情绪是否有可以在二级市场进行一些有效的投资。目前,我们只能说,CP的情绪很有可能与市场收益正相关。
回测的一个更明显的局限性是,它只是对过去的一个验证。找到一个有利可图的回测是一项很辛苦的工作,任何交易策略的真正成功在于它未来在实时数据上的表现。
总的来说,使用 LDA 和 VADER 情绪分析进行主题建模是可行的解决方案,利用回测期间产生的情绪信号进行交易是有利可图的,“买入并持有”策略的优异表现足以说明这一点。在未来的研究中,我们可以加入格兰杰因果关系检验和事件研究,以分离出CP Tw中的实际市场效应,可能会有更好的表现!
—End—
量化投资与机器学习微信公众号,是业内垂直于Quant、MFE、CST、AI等专业的主流量化自媒体。公众号拥有来自公募、私募、券商、银行、海外等众多圈内18W+关注者。每日发布行业前沿研究成果和最新量化资讯。
