- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 理解Gunicorn:Python WSGI服务器的基石
范范0825
ipythonlinux运维
理解Gunicorn:PythonWSGI服务器的基石介绍Gunicorn,全称GreenUnicorn,是一个为PythonWSGI(WebServerGatewayInterface)应用设计的高效、轻量级HTTP服务器。作为PythonWeb应用部署的常用工具,Gunicorn以其高性能和易用性著称。本文将介绍Gunicorn的基本概念、安装和配置,帮助初学者快速上手。1.什么是Gunico
- Python数据分析与可视化实战指南
William数据分析
pythonpython数据
在数据驱动的时代,Python因其简洁的语法、强大的库生态系统以及活跃的社区,成为了数据分析与可视化的首选语言。本文将通过一个详细的案例,带领大家学习如何使用Python进行数据分析,并通过可视化来直观呈现分析结果。一、环境准备1.1安装必要库在开始数据分析和可视化之前,我们需要安装一些常用的库。主要包括pandas、numpy、matplotlib和seaborn等。这些库分别用于数据处理、数学
- python os.environ
江湖偌大
python深度学习
os.environ['TF_CPP_MIN_LOG_LEVEL']='0'#默认值,输出所有信息os.environ['TF_CPP_MIN_LOG_LEVEL']='1'#屏蔽通知信息(INFO)os.environ['TF_CPP_MIN_LOG_LEVEL']='2'#屏蔽通知信息和警告信息(INFO\WARNING)os.environ['TF_CPP_MIN_LOG_LEVEL']='
- Python中os.environ基本介绍及使用方法
鹤冲天Pro
#Pythonpython服务器开发语言
文章目录python中os.environos.environ简介os.environ进行环境变量的增删改查python中os.environ的使用详解1.简介2.key字段详解2.1常见key字段3.os.environ.get()用法4.环境变量的增删改查和判断是否存在4.1新增环境变量4.2更新环境变量4.3获取环境变量4.4删除环境变量4.5判断环境变量是否存在python中os.envi
- Pyecharts数据可视化大屏:打造沉浸式数据分析体验
我的运维人生
信息可视化数据分析数据挖掘运维开发技术共享
Pyecharts数据可视化大屏:打造沉浸式数据分析体验在当今这个数据驱动的时代,如何将海量数据以直观、生动的方式展现出来,成为了数据分析师和企业决策者关注的焦点。Pyecharts,作为一款基于Python的开源数据可视化库,凭借其丰富的图表类型、灵活的配置选项以及高度的定制化能力,成为了构建数据可视化大屏的理想选择。本文将深入探讨如何利用Pyecharts打造数据可视化大屏,并通过实际代码案例
- Python教程:一文了解使用Python处理XPath
旦莫
Python进阶python开发语言
目录1.环境准备1.1安装lxml1.2验证安装2.XPath基础2.1什么是XPath?2.2XPath语法2.3示例XML文档3.使用lxml解析XML3.1解析XML文档3.2查看解析结果4.XPath查询4.1基本路径查询4.2使用属性查询4.3查询多个节点5.XPath的高级用法5.1使用逻辑运算符5.2使用函数6.实战案例6.1从网页抓取数据6.1.1安装Requests库6.1.2代
- python os.environ_python os.environ 读取和设置环境变量
weixin_39605414
pythonos.environ
>>>importos>>>os.environ.keys()['LC_NUMERIC','GOPATH','GOROOT','GOBIN','LESSOPEN','SSH_CLIENT','LOGNAME','USER','HOME','LC_PAPER','PATH','DISPLAY','LANG','TERM','SHELL','J2REDIR','LC_MONETARY','QT_QPA
- 使用Faiss进行高效相似度搜索
llzwxh888
faisspython
在现代AI应用中,快速和高效的相似度搜索是至关重要的。Faiss(FacebookAISimilaritySearch)是一个专门用于快速相似度搜索和聚类的库,特别适用于高维向量。本文将介绍如何使用Faiss来进行相似度搜索,并结合Python代码演示其基本用法。什么是Faiss?Faiss是一个由FacebookAIResearch团队开发的开源库,主要用于高维向量的相似性搜索和聚类。Faiss
- python是什么意思中文-在python中%是什么意思
编程大乐趣
Python中%有两种:1、数值运算:%代表取模,返回除法的余数。如:>>>7%212、%操作符(字符串格式化,stringformatting),说明如下:%[(name)][flags][width].[precision]typecode(name)为命名flags可以有+,-,''或0。+表示右对齐。-表示左对齐。''为一个空格,表示在正数的左侧填充一个空格,从而与负数对齐。0表示使用0填
- Day1笔记-Python简介&标识符和关键字&输入输出
~在杰难逃~
Pythonpython开发语言大数据数据分析数据挖掘
大家好,从今天开始呢,杰哥开展一个新的专栏,当然,数据分析部分也会不定时更新的,这个新的专栏主要是讲解一些Python的基础语法和知识,帮助0基础的小伙伴入门和学习Python,感兴趣的小伙伴可以开始认真学习啦!一、Python简介【了解】1.计算机工作原理编程语言就是用来定义计算机程序的形式语言。我们通过编程语言来编写程序代码,再通过语言处理程序执行向计算机发送指令,让计算机完成对应的工作,编程
- python八股文面试题分享及解析(1)
Shawn________
python
#1.'''a=1b=2不用中间变量交换a和b'''#1.a=1b=2a,b=b,aprint(a)print(b)结果:21#2.ll=[]foriinrange(3):ll.append({'num':i})print(11)结果:#[{'num':0},{'num':1},{'num':2}]#3.kk=[]a={'num':0}foriinrange(3):#0,12#可变类型,不仅仅改变
- 每日算法&面试题,大厂特训二十八天——第二十天(树)
肥学
⚡算法题⚡面试题每日精进java算法数据结构
目录标题导读算法特训二十八天面试题点击直接资料领取导读肥友们为了更好的去帮助新同学适应算法和面试题,最近我们开始进行专项突击一步一步来。上一期我们完成了动态规划二十一天现在我们进行下一项对各类算法进行二十八天的一个小总结。还在等什么快来一起肥学进行二十八天挑战吧!!特别介绍小白练手专栏,适合刚入手的新人欢迎订阅编程小白进阶python有趣练手项目里面包括了像《机器人尬聊》《恶搞程序》这样的有趣文章
- Python快速入门 —— 第三节:类与对象
孤华暗香
Python快速入门python开发语言
第三节:类与对象目标:了解面向对象编程的基础概念,并学会如何定义类和创建对象。内容:类与对象:定义类:class关键字。类的构造函数:__init__()。类的属性和方法。对象的创建与使用。示例:classStudent:def__init__(self,name,age,major):self.name&#
- pyecharts——绘制柱形图折线图
2224070247
信息可视化pythonjava数据可视化
一、pyecharts概述自2013年6月百度EFE(ExcellentFrontEnd)数据可视化团队研发的ECharts1.0发布到GitHub网站以来,ECharts一直备受业界权威的关注并获得广泛好评,成为目前成熟且流行的数据可视化图表工具,被应用到诸多数据可视化的开发领域。Python作为数据分析领域最受欢迎的语言,也加入ECharts的使用行列,并研发出方便Python开发者使用的数据
- Python 实现图片裁剪(附代码) | Python工具
剑客阿良_ALiang
前言本文提供将图片按照自定义尺寸进行裁剪的工具方法,一如既往的实用主义。环境依赖ffmpeg环境安装,可以参考我的另一篇文章:windowsffmpeg安装部署_阿良的博客-CSDN博客本文主要使用到的不是ffmpeg,而是ffprobe也在上面这篇文章中的zip包中。ffmpy安装:pipinstallffmpy-ihttps://pypi.douban.com/simple代码不废话了,上代码
- 【华为OD技术面试真题 - 技术面】- python八股文真题题库(4)
算法大师
华为od面试python
华为OD面试真题精选专栏:华为OD面试真题精选目录:2024华为OD面试手撕代码真题目录以及八股文真题目录文章目录华为OD面试真题精选**1.Python中的`with`**用途和功能自动资源管理示例:文件操作上下文管理协议示例代码工作流程解析优点2.\_\_new\_\_和**\_\_init\_\_**区别__new____init__区别总结3.**切片(Slicing)操作**基本切片语法
- python os 环境变量
CV矿工
python开发语言numpy
环境变量:环境变量是程序和操作系统之间的通信方式。有些字符不宜明文写进代码里,比如数据库密码,个人账户密码,如果写进自己本机的环境变量里,程序用的时候通过os.environ.get()取出来就行了。os.environ是一个环境变量的字典。环境变量的相关操作importos"""设置/修改环境变量:os.environ[‘环境变量名称’]=‘环境变量值’#其中key和value均为string类
- Python爬虫解析工具之xpath使用详解
eqa11
python爬虫开发语言
文章目录Python爬虫解析工具之xpath使用详解一、引言二、环境准备1、插件安装2、依赖库安装三、xpath语法详解1、路径表达式2、通配符3、谓语4、常用函数四、xpath在Python代码中的使用1、文档树的创建2、使用xpath表达式3、获取元素内容和属性五、总结Python爬虫解析工具之xpath使用详解一、引言在Python爬虫开发中,数据提取是一个至关重要的环节。xpath作为一门
- 【华为OD技术面试真题 - 技术面】- python八股文真题题库(1)
算法大师
华为od面试python
华为OD面试真题精选专栏:华为OD面试真题精选目录:2024华为OD面试手撕代码真题目录以及八股文真题目录文章目录华为OD面试真题精选1.数据预处理流程数据预处理的主要步骤工具和库2.介绍线性回归、逻辑回归模型线性回归(LinearRegression)模型形式:关键点:逻辑回归(LogisticRegression)模型形式:关键点:参数估计与评估:3.python浅拷贝及深拷贝浅拷贝(Shal
- 数字里的世界17期:2021年全球10大顶级数据中心,中国移动榜首
张三叨
你知道吗?2016年,全球的数据中心共计用电4160亿千瓦时,比整个英国的发电量还多40%!前言每天,我们都会创造超过250万TB的数据。并且随着物联网(IOT)的不断普及,这一数据将持续增长。如此庞大的数据被存储在被称为“数据中心”的专用设施中。虽然最早的数据中心建于20世纪40年代,但直到1997-2000年的互联网泡沫期间才逐渐成为主流。当前人类的技术,比如人工智能和机器学习,已经将我们推向
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- 《Python数据分析实战终极指南》
xjt921122
python数据分析开发语言
对于分析师来说,大家在学习Python数据分析的路上,多多少少都遇到过很多大坑**,有关于技能和思维的**:Excel已经没办法处理现有的数据量了,应该学Python吗?找了一大堆Python和Pandas的资料来学习,为什么自己动手就懵了?跟着比赛类公开数据分析案例练了很久,为什么当自己面对数据需求还是只会数据处理而没有分析思路?学了对比、细分、聚类分析,也会用PEST、波特五力这类分析法,为啥
- Python中深拷贝与浅拷贝的区别
yuxiaoyu.
转自:http://blog.csdn.net/u014745194/article/details/70271868定义:在Python中对象的赋值其实就是对象的引用。当创建一个对象,把它赋值给另一个变量的时候,python并没有拷贝这个对象,只是拷贝了这个对象的引用而已。浅拷贝:拷贝了最外围的对象本身,内部的元素都只是拷贝了一个引用而已。也就是,把对象复制一遍,但是该对象中引用的其他对象我不复
- Python开发常用的三方模块如下:
换个网名有点难
python开发语言
Python是一门功能强大的编程语言,拥有丰富的第三方库,这些库为开发者提供了极大的便利。以下是100个常用的Python库,涵盖了多个领域:1、NumPy,用于科学计算的基础库。2、Pandas,提供数据结构和数据分析工具。3、Matplotlib,一个绘图库。4、Scikit-learn,机器学习库。5、SciPy,用于数学、科学和工程的库。6、TensorFlow,由Google开发的开源机
- Python编译器
鹿鹿~
Python编译器Pythonpython开发语言后端
嘿嘿嘿我又来了啊有些小盆友可能不知道Python其实是有编译器的,也就是PyCharm。你们可能会问到这个是干嘛的又不可以吃也不可以穿好像没有什么用,其实你还说对了这个还真的不可以吃也不可以穿,但是它用来干嘛的呢。用来编译你所打出的代码进行运行(可能这里说的有点不对但是只是个人认为)现在我们来说说PyCharm是用来干嘛的。PyCharm是一种PythonIDE,带有一整套可以帮助用户在使用Pyt
- 一文掌握python面向对象魔术方法(二)
程序员neil
pythonpython开发语言
接上篇:一文掌握python面向对象魔术方法(一)-CSDN博客目录六、迭代和序列化:1、__iter__(self):定义迭代器,使得类可以被for循环迭代。2、__getitem__(self,key):定义索引操作,如obj[key]。3、__setitem__(self,key,value):定义赋值操作,如obj[key]=value。4、__delitem__(self,key):定义
- 一文掌握python常用的list(列表)操作
程序员neil
pythonpython开发语言
目录一、创建列表1.直接创建列表:2.使用list()构造器3.使用列表推导式4.创建空列表二、访问列表元素1.列表支持通过索引访问元素,索引从0开始:2.还可以使用切片操作访问列表的一部分:三、修改列表元素四、添加元素1.append():在末尾添加元素2.insert():在指定位置插入元素五、删除元素1.del:删除指定位置的元素2.remove():删除指定值的第一个匹配项3.pop():
- Python实现简单的机器学习算法
master_chenchengg
pythonpython办公效率python开发IT
Python实现简单的机器学习算法开篇:初探机器学习的奇妙之旅搭建环境:一切从安装开始必备工具箱第一步:安装Anaconda和JupyterNotebook小贴士:如何配置Python环境变量算法初体验:从零开始的Python机器学习线性回归:让数据说话数据准备:从哪里找数据编码实战:Python实现线性回归模型评估:如何判断模型好坏逻辑回归:从分类开始理论入门:什么是逻辑回归代码实现:使用skl
- python中的深拷贝与浅拷贝
anshejd70787
python
深拷贝和浅拷贝浅拷贝的时候,修改原来的对象,浅拷贝的对象不会发生改变。1、对象的赋值对象的赋值实际上是对象之间的引用:当创建一个对象,然后将这个对象赋值给另外一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用。当对对象做赋值或者是参数传递或者作为返回值的时候,总是传递原始对象的引用,而不是一个副本。如下所示:>>>aList=["kel","abc",123]>>>bLis
- ASM系列五 利用TreeApi 解析生成Class
lijingyao8206
ASM字节码动态生成ClassNodeTreeAPI
前面CoreApi的介绍部分基本涵盖了ASMCore包下面的主要API及功能,其中还有一部分关于MetaData的解析和生成就不再赘述。这篇开始介绍ASM另一部分主要的Api。TreeApi。这一部分源码是关联的asm-tree-5.0.4的版本。
在介绍前,先要知道一点, Tree工程的接口基本可以完
- 链表树——复合数据结构应用实例
bardo
数据结构树型结构表结构设计链表菜单排序
我们清楚:数据库设计中,表结构设计的好坏,直接影响程序的复杂度。所以,本文就无限级分类(目录)树与链表的复合在表设计中的应用进行探讨。当然,什么是树,什么是链表,这里不作介绍。有兴趣可以去看相关的教材。
需求简介:
经常遇到这样的需求,我们希望能将保存在数据库中的树结构能够按确定的顺序读出来。比如,多级菜单、组织结构、商品分类。更具体的,我们希望某个二级菜单在这一级别中就是第一个。虽然它是最后
- 为啥要用位运算代替取模呢
chenchao051
位运算哈希汇编
在hash中查找key的时候,经常会发现用&取代%,先看两段代码吧,
JDK6中的HashMap中的indexFor方法:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
- 最近的情况
麦田的设计者
生活感悟计划软考想
今天是2015年4月27号
整理一下最近的思绪以及要完成的任务
1、最近在驾校科目二练车,每周四天,练三周。其实做什么都要用心,追求合理的途径解决。为
- PHP去掉字符串中最后一个字符的方法
IT独行者
PHP字符串
今天在PHP项目开发中遇到一个需求,去掉字符串中的最后一个字符 原字符串1,2,3,4,5,6, 去掉最后一个字符",",最终结果为1,2,3,4,5,6 代码如下:
$str = "1,2,3,4,5,6,";
$newstr = substr($str,0,strlen($str)-1);
echo $newstr;
- hadoop在linux上单机安装过程
_wy_
linuxhadoop
1、安装JDK
jdk版本最好是1.6以上,可以使用执行命令java -version查看当前JAVA版本号,如果报命令不存在或版本比较低,则需要安装一个高版本的JDK,并在/etc/profile的文件末尾,根据本机JDK实际的安装位置加上以下几行:
export JAVA_HOME=/usr/java/jdk1.7.0_25
- JAVA进阶----分布式事务的一种简单处理方法
无量
多系统交互分布式事务
每个方法都是原子操作:
提供第三方服务的系统,要同时提供执行方法和对应的回滚方法
A系统调用B,C,D系统完成分布式事务
=========执行开始========
A.aa();
try {
B.bb();
} catch(Exception e) {
A.rollbackAa();
}
try {
C.cc();
} catch(Excep
- 安墨移动广 告:移动DSP厚积薄发 引领未来广 告业发展命脉
矮蛋蛋
hadoop互联网
“谁掌握了强大的DSP技术,谁将引领未来的广 告行业发展命脉。”2014年,移动广 告行业的热点非移动DSP莫属。各个圈子都在纷纷谈论,认为移动DSP是行业突破点,一时间许多移动广 告联盟风起云涌,竞相推出专属移动DSP产品。
到底什么是移动DSP呢?
DSP(Demand-SidePlatform),就是需求方平台,为解决广 告主投放的各种需求,真正实现人群定位的精准广
- myelipse设置
alafqq
IP
在一个项目的完整的生命周期中,其维护费用,往往是其开发费用的数倍。因此项目的可维护性、可复用性是衡量一个项目好坏的关键。而注释则是可维护性中必不可少的一环。
注释模板导入步骤
安装方法:
打开eclipse/myeclipse
选择 window-->Preferences-->JAVA-->Code-->Code
- java数组
百合不是茶
java数组
java数组的 声明 创建 初始化; java支持C语言
数组中的每个数都有唯一的一个下标
一维数组的定义 声明: int[] a = new int[3];声明数组中有三个数int[3]
int[] a 中有三个数,下标从0开始,可以同过for来遍历数组中的数
- javascript读取表单数据
bijian1013
JavaScript
利用javascript读取表单数据,可以利用以下三种方法获取:
1、通过表单ID属性:var a = document.getElementByIdx_x_x("id");
2、通过表单名称属性:var b = document.getElementsByName("name");
3、直接通过表单名字获取:var c = form.content.
- 探索JUnit4扩展:使用Theory
bijian1013
javaJUnitTheory
理论机制(Theory)
一.为什么要引用理论机制(Theory)
当今软件开发中,测试驱动开发(TDD — Test-driven development)越发流行。为什么 TDD 会如此流行呢?因为它确实拥有很多优点,它允许开发人员通过简单的例子来指定和表明他们代码的行为意图。
TDD 的优点:
&nb
- [Spring Data Mongo一]Spring Mongo Template操作MongoDB
bit1129
template
什么是Spring Data Mongo
Spring Data MongoDB项目对访问MongoDB的Java客户端API进行了封装,这种封装类似于Spring封装Hibernate和JDBC而提供的HibernateTemplate和JDBCTemplate,主要能力包括
1. 封装客户端跟MongoDB的链接管理
2. 文档-对象映射,通过注解:@Document(collectio
- 【Kafka八】Zookeeper上关于Kafka的配置信息
bit1129
zookeeper
问题:
1. Kafka的哪些信息记录在Zookeeper中 2. Consumer Group消费的每个Partition的Offset信息存放在什么位置
3. Topic的每个Partition存放在哪个Broker上的信息存放在哪里
4. Producer跟Zookeeper究竟有没有关系?没有关系!!!
//consumers、config、brokers、cont
- java OOM内存异常的四种类型及异常与解决方案
ronin47
java OOM 内存异常
OOM异常的四种类型:
一: StackOverflowError :通常因为递归函数引起(死递归,递归太深)。-Xss 128k 一般够用。
二: out Of memory: PermGen Space:通常是动态类大多,比如web 服务器自动更新部署时引起。-Xmx
- java-实现链表反转-递归和非递归实现
bylijinnan
java
20120422更新:
对链表中部分节点进行反转操作,这些节点相隔k个:
0->1->2->3->4->5->6->7->8->9
k=2
8->1->6->3->4->5->2->7->0->9
注意1 3 5 7 9 位置是不变的。
解法:
将链表拆成两部分:
a.0-&
- Netty源码学习-DelimiterBasedFrameDecoder
bylijinnan
javanetty
看DelimiterBasedFrameDecoder的API,有举例:
接收到的ChannelBuffer如下:
+--------------+
| ABC\nDEF\r\n |
+--------------+
经过DelimiterBasedFrameDecoder(Delimiters.lineDelimiter())之后,得到:
+-----+----
- linux的一些命令 -查看cc攻击-网口ip统计等
hotsunshine
linux
Linux判断CC攻击命令详解
2011年12月23日 ⁄ 安全 ⁄ 暂无评论
查看所有80端口的连接数
netstat -nat|grep -i '80'|wc -l
对连接的IP按连接数量进行排序
netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n
查看TCP连接状态
n
- Spring获取SessionFactory
ctrain
sessionFactory
String sql = "select sysdate from dual";
WebApplicationContext wac = ContextLoader.getCurrentWebApplicationContext();
String[] names = wac.getBeanDefinitionNames();
for(int i=0; i&
- Hive几种导出数据方式
daizj
hive数据导出
Hive几种导出数据方式
1.拷贝文件
如果数据文件恰好是用户需要的格式,那么只需要拷贝文件或文件夹就可以。
hadoop fs –cp source_path target_path
2.导出到本地文件系统
--不能使用insert into local directory来导出数据,会报错
--只能使用
- 编程之美
dcj3sjt126com
编程PHP重构
我个人的 PHP 编程经验中,递归调用常常与静态变量使用。静态变量的含义可以参考 PHP 手册。希望下面的代码,会更有利于对递归以及静态变量的理解
header("Content-type: text/plain");
function static_function () {
static $i = 0;
if ($i++ < 1
- Android保存用户名和密码
dcj3sjt126com
android
转自:http://www.2cto.com/kf/201401/272336.html
我们不管在开发一个项目或者使用别人的项目,都有用户登录功能,为了让用户的体验效果更好,我们通常会做一个功能,叫做保存用户,这样做的目地就是为了让用户下一次再使用该程序不会重新输入用户名和密码,这里我使用3种方式来存储用户名和密码
1、通过普通 的txt文本存储
2、通过properties属性文件进行存
- Oracle 复习笔记之同义词
eksliang
Oracle 同义词Oracle synonym
转载请出自出处:http://eksliang.iteye.com/blog/2098861
1.什么是同义词
同义词是现有模式对象的一个别名。
概念性的东西,什么是模式呢?创建一个用户,就相应的创建了 一个模式。模式是指数据库对象,是对用户所创建的数据对象的总称。模式对象包括表、视图、索引、同义词、序列、过
- Ajax案例
gongmeitao
Ajaxjsp
数据库采用Sql Server2005
项目名称为:Ajax_Demo
1.com.demo.conn包
package com.demo.conn;
import java.sql.Connection;import java.sql.DriverManager;import java.sql.SQLException;
//获取数据库连接的类public class DBConnec
- ASP.NET中Request.RawUrl、Request.Url的区别
hvt
.netWebC#asp.nethovertree
如果访问的地址是:http://h.keleyi.com/guestbook/addmessage.aspx?key=hovertree%3C&n=myslider#zonemenu那么Request.Url.ToString() 的值是:http://h.keleyi.com/guestbook/addmessage.aspx?key=hovertree<&
- SVG 教程 (七)SVG 实例,SVG 参考手册
天梯梦
svg
SVG 实例 在线实例
下面的例子是把SVG代码直接嵌入到HTML代码中。
谷歌Chrome,火狐,Internet Explorer9,和Safari都支持。
注意:下面的例子将不会在Opera运行,即使Opera支持SVG - 它也不支持SVG在HTML代码中直接使用。 SVG 实例
SVG基本形状
一个圆
矩形
不透明矩形
一个矩形不透明2
一个带圆角矩
- 事务管理
luyulong
javaspring编程事务
事物管理
spring事物的好处
为不同的事物API提供了一致的编程模型
支持声明式事务管理
提供比大多数事务API更简单更易于使用的编程式事务管理API
整合spring的各种数据访问抽象
TransactionDefinition
定义了事务策略
int getIsolationLevel()得到当前事务的隔离级别
READ_COMMITTED
- 基础数据结构和算法十一:Red-black binary search tree
sunwinner
AlgorithmRed-black
The insertion algorithm for 2-3 trees just described is not difficult to understand; now, we will see that it is also not difficult to implement. We will consider a simple representation known
- centos同步时间
stunizhengjia
linux集群同步时间
做了集群,时间的同步就显得非常必要了。 以下是查到的如何做时间同步。 在CentOS 5不再区分客户端和服务器,只要配置了NTP,它就会提供NTP服务。 1)确认已经ntp程序包: # yum install ntp 2)配置时间源(默认就行,不需要修改) # vi /etc/ntp.conf server pool.ntp.o
- ITeye 9月技术图书有奖试读获奖名单公布
ITeye管理员
ITeye
ITeye携手博文视点举办的9月技术图书有奖试读活动已圆满结束,非常感谢广大用户对本次活动的关注与参与。 9月试读活动回顾:http://webmaster.iteye.com/blog/2118112本次技术图书试读活动的优秀奖获奖名单及相应作品如下(优秀文章有很多,但名额有限,没获奖并不代表不优秀):
《NFC:Arduino、Andro
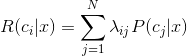
 的极大似然估计为
的极大似然估计为
 可以用样本频率来估计,
可以用样本频率来估计, 可以估计为标记为c的样本中在第i个属性上取值为xi的集合与标记为c的样本的比值,如果是连续属性的话可以考虑概率密度函数(书里整理了西瓜的案例,非常简单易懂)
可以估计为标记为c的样本中在第i个属性上取值为xi的集合与标记为c的样本的比值,如果是连续属性的话可以考虑概率密度函数(书里整理了西瓜的案例,非常简单易懂) 贝叶斯网
贝叶斯网