目标检测向:You Only Look Once: Unified, Real-Time Object Detection
Abstract
作者将目标检测当作回归问题来处理,以此来解决目标检测中的bbox定位和相关类别概率预测问题。同SOTA的检测系统相比,YOLO在定位问题上出错概率更大,而在背景预测的问题上,fpr显著地更小。
1. Introduction

无论是在训练还是在测试的时候,YOLO处理的水平都是在整张图片上进行的,因此它很轻易地就可以对背景信息的类别和外表进行编码。YOLO的泛化性非常强,即,在natural images上训练,随后在art images上测试的表现,都超出了DPM和R-CNN。因此当运用到新的领域或者人类无法预估的某种输入图片上时,YOLO的稳定性很高。
2. Unified Detection
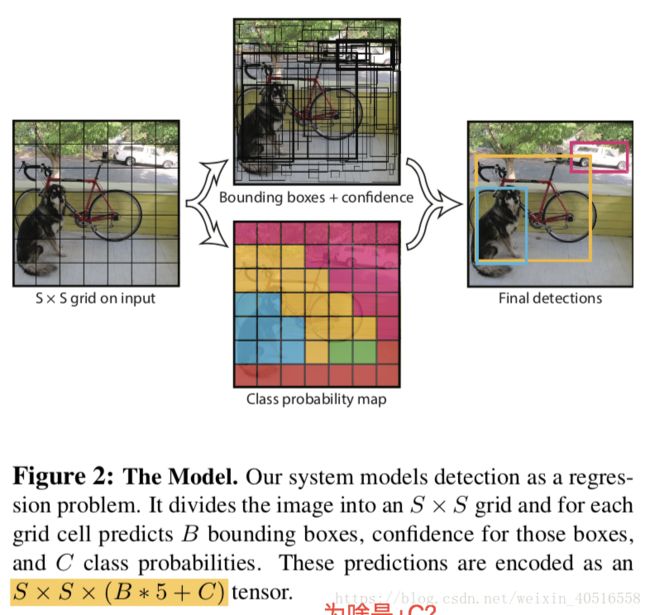
YOLO将一张图片分割成S x S个grid,如果一个目标的中心落在某个grid上,那么这个grid就负责检测这一个目标。每一个grid会预测出B个bbox,并且对每一个bbox生成置信得分。置信得分的定义如下:

每一个bbox包含五个预测,它们分别是x,y,w,h,以及置信得分。其中(x, y)代表box中心点相对于grid cell边界的坐标,w,h则是相对于整张图片的预测值。置信得分则是预测得到的bbox和gt box之间的IoU。
除此之外,每个grid cell还会预测出C个条件类别概率,Pr(Class_i|Object)。无论一个grid cell预测几个bbox,即无论B为多少,对于一个grid cell,我们都只预测一系列类别概率。
测试的时候,将条件类别概率同之前定义的置信得分做乘积,即:

这样我们就得到了每一个框属于任一特定类别的置信得分。这些得分不仅代表了某一类别出现在框里的概率,也代表了预测框和目标之间的一致性。
2.1 Network Design
YOLO网络结构的灵感来源于用于对图片进行分类的GoogLeNet。YOLO有24的conv layers,以及2个fc layers。

上图是GoogLeNet的inception module的结构,作者参考了以上结构,但只用了第二个支路,类似NiN(这也是个未填的坑)。完整的网络结构如下:
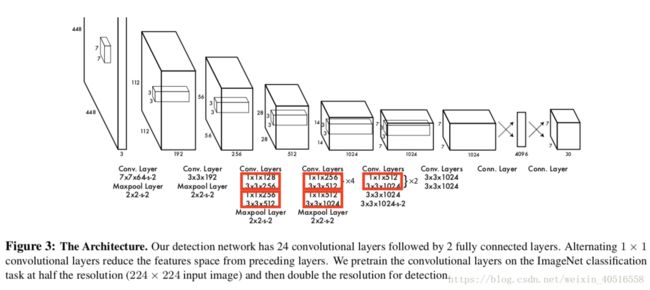
作者同时还训练了一个fast版本的YOLO。这个fast版本的YOLO只有9个conv layers,并且每个layer上的filter更少。
2.2 Training
卷积层的预训练是在ImageNet的1000分类比赛数据集上进行的。预训练用的是图3中的20个conv layers,随后紧接着一个Avg-pooling layer以及一个fc layer。
在检测问题上,作者参考了别人的work,在原网络的基础上添加了4个conv layers以及2个fc layers,并且用随机权重进行初始化。由于检测问题需要更为精细的视觉信息,作者将输入的resolution从224 x 224提高到了448 x 448。
在计算过程中,作者对bbox的宽和高用图片的宽和高进行标准化,因此bbox的宽和高介于[0,1]。类似地,将bbox的x,y坐标对应grid cell的位置,让x,y介于[0,1]。最后一层的activation function选择的是Leaky ReLU。
损失函数选择的是平方和损失函数。因为它易于优化。
当一个grid cell中不包含任何目标时,它的“confidence”得分接近于0,这通常会使得它的梯度超过那些包含目标的cell,即它对损失的影响会变大。这可能会导致模型不稳定,训练过早地收敛。
为了解决这个问题,作者在损失函数中,对包含目标的cell和不包含目标的cell设定了不同的\lambda值。\lambda_coord=5,\lambda_noobj=0.5。
除此之外,损失函数必须反应,小的deviations在大框中的影响不如在小框中的影响。因此预测的时候,我们不是直接预测宽和高,而是预测bbox的宽和高的平方根。
在测试的时候,我们希望对于每一个目标只有一个bbox predictor对其负责。因此每个bbox predictor都是specific的。
损失函数定义如下:

可以注意到损失函数只对grid中出现目标以及responsible的进行惩罚。
2.4 Limitations of YOLO
YOLO对于以组的形式出现的小目标检测效果不是很好,比如鸟群。
而且由于YOLO模型结构中存在很多下采样,因此YOLO对于bbox的预测用到的特征都相对比较coarse。
除此之外,损失函数对于小的bbox和大的bbox的误差处理方式都是一样的。
3. Comparison to Other Detection System
DPM用的是独立的pipeline来提取静态特征,对区域分类以及为高分区域预测bbox;而YOLO则将这些所有的独立部分都结合到了一个一阶段的卷积神经网络中去。
4. Experiments
4.4 VOC 2012 Results
R-CNN运用到artwork上的效果不太好。因为R-CNN使用的是SS来生成proposals,而SS是已经为了natural images进行了tuning过的。因此R-CNN重的分类器部分只寻找小的区域,并且需要好的proposal进行支撑。
DPM运用到artwork上的效果还不错,是因为它具有稳定的空间模型来捕捉目标的形状和分布。
而YOLO对目标的大小和形状、以及目标之间的关系和目标可能出现的位置进行建模。artwork和natural images在像素水平上相差较远但是在目标的大小和形状上是比较接近的,因此YOLO在artwork上同样可以预测好的bbox。

6. Conclusion
不同于那些基于分类器的方法,YOLO是在一个直接对应检测表现的损失函数上进行训练的,并且整个模型是同时训练的。除此之外,YOLO在新领域上的泛化能力是很好的,因此它可以进行快速的、稳健的目标检测。