面试总结(1)---7.28
Ajax关于readyState(状态值)和status(状态码)的研究
var getXmlHttpRequest = function () {
try{
//主流浏览器提供了XMLHttpRequest对象
return new XMLHttpRequest();
}catch(e){
//低版本的IE浏览器没有提供XMLHttpRequest对象,IE6以下
//所以必须使用IE浏览器的特定实现ActiveXObject
return new ActiveXObject("Microsoft.XMLHTTP");
}
};
var xhr = getXmlHttpRequest();
// readyState 0=>初始化 1=>载入 2=>载入完成 3=>解析 4=>完成
// console.log(xhr.readyState); 0
xhr.open("TYPE", "URL", true);
// console.log(xhr.readyState); 1
xhr.send();
// console.log(xhr.readyState); 1
xhr.onreadystatechange = function () {
// console.log(xhr.status); //HTTP状态吗
// console.log(xhr.readyState); 2 3 4
if(xhr.readyState === 4 && xhr.status === 200){
alert(xhr.responseText);
}
};
1.Ajax:readyState(状态值)和status(状态码)的区别
readyState,是指运行AJAX所经历过的几种状态,无论访问是否成功都将响应的步骤,可以理解成为AJAX运行步骤,使用“ajax.readyState”获得
status,是指无论AJAX访问是否成功,由HTTP协议根据所提交的信息,服务器所返回的HTTP头信息代码,使用“ajax.status”获得
总体理解:可以简单的理解为state代表一个整体的状态。而status是这个大的state下面具体的小的状态。
2.什么是readyState
readyState是XMLHttpRequest对象的一个属性,用来标识当前XMLHttpRequest对象处于什么状态。
readyState总共有5个状态值,分别为0~4,每个值代表了不同的含义
| 1 2 3 4 5 |
0:初始化,XMLHttpRequest对象还没有完成初始化 1:载入,XMLHttpRequest对象开始发送请求 2:载入完成,XMLHttpRequest对象的请求发送完成 3:解析,XMLHttpRequest对象开始读取服务器的响应 4:完成,XMLHttpRequest对象读取服务器响应结束 |
3.什么是status
status是XMLHttpRequest对象的一个属性,表示响应的HTTP状态码
在HTTP1.1协议下,HTTP状态码总共可分为5大类
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
1xx:信息响应类,表示接收到请求并且继续处理 2xx:处理成功响应类,表示动作被成功接收、理解和接受 3xx:重定向响应类,为了完成指定的动作,必须接受进一步处理 4xx:客户端错误,客户请求包含语法错误或者是不能正确执行 5xx:服务端错误,服务器不能正确执行一个正确的请求
100——客户必须继续发出请求 101——客户要求服务器根据请求转换HTTP协议版本 200——交易成功 201——提示知道新文件的URL 202——接受和处理、但处理未完成 203——返回信息不确定或不完整 204——请求收到,但返回信息为空 205——服务器完成了请求,用户代理必须复位当前已经浏览过的文件 206——服务器已经完成了部分用户的GET请求 300——请求的资源可在多处得到 301——删除请求数据 302——在其他地址发现了请求数据 303——建议客户访问其他URL或访问方式 304——客户端已经执行了GET,但文件未变化 305——请求的资源必须从服务器指定的地址得到 306——前一版本HTTP中使用的代码,现行版本中不再使用 307——申明请求的资源临时性删除 400——错误请求,如语法错误 401——请求授权失败 402——保留有效ChargeTo头响应 403——请求不允许 404——没有发现文件、查询或URl 405——用户在Request-Line字段定义的方法不允许 406——根据用户发送的Accept拖,请求资源不可访问 407——类似401,用户必须首先在代理服务器上得到授权 408——客户端没有在用户指定的饿时间内完成请求 409——对当前资源状态,请求不能完成 410——服务器上不再有此资源且无进一步的参考地址 411——服务器拒绝用户定义的Content-Length属性请求 412——一个或多个请求头字段在当前请求中错误 413——请求的资源大于服务器允许的大小 414——请求的资源URL长于服务器允许的长度 415——请求资源不支持请求项目格式 416——请求中包含Range请求头字段,在当前请求资源范围内没有range指示值,请求也不包含If-Range请求头字段 417——服务器不满足请求Expect头字段指定的期望值,如果是代理服务器,可能是下一级服务器不能满足请求 500——服务器产生内部错误 501——服务器不支持请求的函数 502——服务器暂时不可用,有时是为了防止发生系统过载 503——服务器过载或暂停维修 504——关口过载,服务器使用另一个关口或服务来响应用户,等待时间设定值较长 505——服务器不支持或拒绝支请求头中指定的HTTP版本 |
4.思考问题:为什么onreadystatechange的函数实现要同时判断readyState和status呢?
第一种思考方式:只使用readyState
var getXmlHttpRequest = function () {
if (window.XMLHttpRequest) {
return new XMLHttpRequest();
}
else if (window.ActiveXObject) {
return new ActiveXObject("Microsoft.XMLHTTP");
}
};
var xhr = getXmlHttpRequest();
xhr.open("get", "1.txt", true);
xhr.send();
xhr.onreadystatechange = function () {
if (xhr.readyState === 4) {
alert(xhr.responseText);
}
};
服务响应出错了,但还是返回了信息,这并不是我们想要的结果
如果返回不是200,而是404或者500,由于只使用readystate做判断,它不理会放回的结果是200、404还是500,只要响应成功返回了,就执行接下来的javascript代码,结果将造成各种不可预料的错误。所以只使用readyState判断是行不通的。
第二种思考方式:只使用status判断
var getXmlHttpRequest = function () {
try{
return new XMLHttpRequest();
}catch(e){
return new ActiveXObject("Microsoft.XMLHTTP");
}
};
var xhr = getXmlHttpRequest();
xhr.open("get", "1.txt", true);
xhr.send();
xhr.onreadystatechange = function () {
if (xhr.status === 200) {
alert("readyState=" + xhr.readyState + xhr.responseText);
}
};
事实上,结果却不像预期那样。响应码确实是返回了200,但是总共弹出了3次窗口!第一次是“readyState=2”的窗口,第二次是“readyState=3”的窗口,第三次是“readyState=4”的窗口。由此,可见onreadystatechange函数的执行不是只在readyState变为4的时候触发的,而是readyState(2、3、4)的每次变化都会触发,所以就出现了前面说的那种情况。可见,单独使用status判断也是行不通的。
5.由上面的试验,我们可以知道判断的时候readyState和status缺一不可。那么readyState和status的先后判断顺序会不会有影响呢?我们可以将status调到前面先判断,代码如 xhr.status === 200 && xhr.readyState === 4
事实上,这对于最终的结果是没有影响的,但是中间的性能就不同了。由试验我们知道,readyState的每次变化都会触发onreadystatechange函数,假如先判断status,那么每次都会多判断一次status的状态。虽然性能上影响甚微,不过还是应该抱着追求极致代码的想法,把readyState的判断放在前面。
xhr.readyState === 4 && xhr.status === 200
CSS3的 transform属性,怎么才能让他同时执行多个不同动画(属性)效果
div{width: 100px; height: 100px; transition: all 1s; background: red;}
div:hover{transform: rotate(360deg) scale(2,2) skew(10deg,5deg);} 中间用空格隔开 旋转 缩放 扭曲 等同时执行多个效果!
定义和用法
transform 属性向元素应用 2D 或 3D 转换。该属性允许我们对元素进行旋转、缩放、移动或倾斜。
为了更好地理解 transform 属性,请查看这个演示。
| 默认值: |
none |
| 继承性: |
no |
| 版本: |
CSS3 |
| JavaScript 语法: |
object.style.transform="rotate(7deg)" |
语法
transform: none|transform-functions;
| 值 |
描述 |
测试 |
| none |
定义不进行转换。 |
测试 |
| matrix(n,n,n,n,n,n) |
定义 2D 转换,使用六个值的矩阵。 |
测试 |
| matrix3d(n,n,n,n,n,n,n,n,n,n,n,n,n,n,n,n) |
定义 3D 转换,使用 16 个值的 4x4 矩阵。 |
|
| translate(x,y) |
定义 2D 转换。 |
测试 |
| translate3d(x,y,z) |
定义 3D 转换。 |
|
| translateX(x) |
定义转换,只是用 X 轴的值。 |
测试 |
| translateY(y) |
定义转换,只是用 Y 轴的值。 |
测试 |
| translateZ(z) |
定义 3D 转换,只是用 Z 轴的值。 |
|
| scale(x,y) |
定义 2D 缩放转换。 |
测试 |
| scale3d(x,y,z) |
定义 3D 缩放转换。 |
|
| scaleX(x) |
通过设置 X 轴的值来定义缩放转换。 |
测试 |
| scaleY(y) |
通过设置 Y 轴的值来定义缩放转换。 |
测试 |
| scaleZ(z) |
通过设置 Z 轴的值来定义 3D 缩放转换。 |
|
| rotate(angle) |
定义 2D 旋转,在参数中规定角度。 |
测试 |
| rotate3d(x,y,z,angle) |
定义 3D 旋转。 |
|
| rotateX(angle) |
定义沿着 X 轴的 3D 旋转。 |
测试 |
| rotateY(angle) |
定义沿着 Y 轴的 3D 旋转。 |
测试 |
| rotateZ(angle) |
定义沿着 Z 轴的 3D 旋转。 |
测试 |
| skew(x-angle,y-angle) |
定义沿着 X 和 Y 轴的 2D 倾斜转换。 |
测试 |
| skewX(angle) |
定义沿着 X 轴的 2D 倾斜转换。 |
测试 |
| skewY(angle) |
定义沿着 Y 轴的 2D 倾斜转换。 |
测试 |
| perspective(n) |
为 3D 转换元素定义透视视图。 |
测试 |
CSS3 @keyframes 规则
如需在 CSS3 中创建动画,您需要学习 @keyframes 规则。
@keyframes 规则用于创建动画。在 @keyframes 中规定某项 CSS 样式,就能创建由当前样式逐渐改为新样式的动画效果。
浏览器支持
| 属性 |
浏览器支持 |
||||
| @keyframes |
|||||
| animation |
|||||
Internet Explorer 10、Firefox 以及 Opera 支持 @keyframes 规则和 animation 属性。
Chrome 和 Safari 需要前缀 -webkit-。
注释:Internet Explorer 9,以及更早的版本,不支持 @keyframe 规则或 animation 属性。
实例
@keyframes myfirst
{
from {background: red;}
to {background: yellow;}
}
@-moz-keyframes myfirst /* Firefox */
{
from {background: red;}
to {background: yellow;}
}
@-webkit-keyframes myfirst /* Safari 和 Chrome */
{
from {background: red;}
to {background: yellow;}
}
@-o-keyframes myfirst /* Opera */
{
from {background: red;}
to {background: yellow;}
}
CSS3 动画
当您在 @keyframes 中创建动画时,请把它捆绑到某个选择器,否则不会产生动画效果。
通过规定至少以下两项 CSS3 动画属性,即可将动画绑定到选择器:
- 规定动画的名称
- 规定动画的时长
实例
把 "myfirst" 动画捆绑到 div 元素,时长:5 秒:
div
{
animation: myfirst 5s;
-moz-animation: myfirst 5s; /* Firefox */
-webkit-animation: myfirst 5s; /* Safari 和 Chrome */
-o-animation: myfirst 5s; /* Opera */
}
亲自试一试
注释:您必须定义动画的名称和时长。如果忽略时长,则动画不会允许,因为默认值是 0。
什么是 CSS3 中的动画?
动画是使元素从一种样式逐渐变化为另一种样式的效果。
您可以改变任意多的样式任意多的次数。
请用百分比来规定变化发生的时间,或用关键词 "from" 和 "to",等同于 0% 和 100%。
0% 是动画的开始,100% 是动画的完成。
为了得到最佳的浏览器支持,您应该始终定义 0% 和 100% 选择器。
实例
当动画为 25% 及 50% 时改变背景色,然后当动画 100% 完成时再次改变:
@keyframes myfirst
{
0% {background: red;}
25% {background: yellow;}
50% {background: blue;}
100% {background: green;}
}
@-moz-keyframes myfirst /* Firefox */
{
0% {background: red;}
25% {background: yellow;}
50% {background: blue;}
100% {background: green;}
}
@-webkit-keyframes myfirst /* Safari 和 Chrome */
{
0% {background: red;}
25% {background: yellow;}
50% {background: blue;}
100% {background: green;}
}
@-o-keyframes myfirst /* Opera */
{
0% {background: red;}
25% {background: yellow;}
50% {background: blue;}
100% {background: green;}
}
亲自试一试
实例
改变背景色和位置:
@keyframes myfirst
{
0% {background: red; left:0px; top:0px;}
25% {background: yellow; left:200px; top:0px;}
50% {background: blue; left:200px; top:200px;}
75% {background: green; left:0px; top:200px;}
100% {background: red; left:0px; top:0px;}
}
@-moz-keyframes myfirst /* Firefox */
{
0% {background: red; left:0px; top:0px;}
25% {background: yellow; left:200px; top:0px;}
50% {background: blue; left:200px; top:200px;}
75% {background: green; left:0px; top:200px;}
100% {background: red; left:0px; top:0px;}
}
@-webkit-keyframes myfirst /* Safari 和 Chrome */
{
0% {background: red; left:0px; top:0px;}
25% {background: yellow; left:200px; top:0px;}
50% {background: blue; left:200px; top:200px;}
75% {background: green; left:0px; top:200px;}
100% {background: red; left:0px; top:0px;}
}
@-o-keyframes myfirst /* Opera */
{
0% {background: red; left:0px; top:0px;}
25% {background: yellow; left:200px; top:0px;}
50% {background: blue; left:200px; top:200px;}
75% {background: green; left:0px; top:200px;}
100% {background: red; left:0px; top:0px;}
}
亲自试一试
CSS3 动画属性
下面的表格列出了 @keyframes 规则和所有动画属性:
| 属性 |
描述 |
CSS |
| @keyframes |
规定动画。 |
3 |
| animation |
所有动画属性的简写属性,除了 animation-play-state 属性。 |
3 |
| animation-name |
规定 @keyframes 动画的名称。 |
3 |
| animation-duration |
规定动画完成一个周期所花费的秒或毫秒。默认是 0。 |
3 |
| animation-timing-function |
规定动画的速度曲线。默认是 "ease"。 |
3 |
| animation-delay |
规定动画何时开始。默认是 0。 |
3 |
| animation-iteration-count |
规定动画被播放的次数。默认是 1。 |
3 |
| animation-direction |
规定动画是否在下一周期逆向地播放。默认是 "normal"。 |
3 |
| animation-play-state |
规定动画是否正在运行或暂停。默认是 "running"。 |
3 |
| animation-fill-mode |
规定对象动画时间之外的状态。 |
3 |
下面的两个例子设置了所有动画属性:
实例
运行名为 myfirst 的动画,其中设置了所有动画属性:
div
{
animation-name: myfirst;
animation-duration: 5s;
animation-timing-function: linear;
animation-delay: 2s;
animation-iteration-count: infinite;
animation-direction: alternate;
animation-play-state: running;
/* Firefox: */
-moz-animation-name: myfirst;
-moz-animation-duration: 5s;
-moz-animation-timing-function: linear;
-moz-animation-delay: 2s;
-moz-animation-iteration-count: infinite;
-moz-animation-direction: alternate;
-moz-animation-play-state: running;
/* Safari 和 Chrome: */
-webkit-animation-name: myfirst;
-webkit-animation-duration: 5s;
-webkit-animation-timing-function: linear;
-webkit-animation-delay: 2s;
-webkit-animation-iteration-count: infinite;
-webkit-animation-direction: alternate;
-webkit-animation-play-state: running;
/* Opera: */
-o-animation-name: myfirst;
-o-animation-duration: 5s;
-o-animation-timing-function: linear;
-o-animation-delay: 2s;
-o-animation-iteration-count: infinite;
-o-animation-direction: alternate;
-o-animation-play-state: running;
}
亲自试一试
实例
与上面的动画相同,但是使用了简写的动画 animation 属性:
div
{
animation: myfirst 5s linear 2s infinite alternate;
/* Firefox: */
-moz-animation: myfirst 5s linear 2s infinite alternate;
/* Safari 和 Chrome: */
-webkit-animation: myfirst 5s linear 2s infinite alternate;
/* Opera: */
-o-animation: myfirst 5s linear 2s infinite alternate;
}
HTML5的canvas绘图和CSS3的绘图哪个更有优越性
如题,最好能从多个方面比较,能说下区别,二者的原理。
 iGO2dU
iGO2dU
2013-09-27
简单解释一下:
- CSS更像是把多个“矩形”(div)裁剪后,然后拼接成一个图案,然后给图案上色。
- Canvas由点开始,延长无数个点,得到线,延长线之后得到一个面(三角形,圆形,矩形等等的图案面),然后给线或者面描边,上色。
- CSS目前更像是小朋友的手工课,Canvas更像是用一支笔画图,不过画出来的图更加像能够控制大小的矢量图片。
下图简单说明
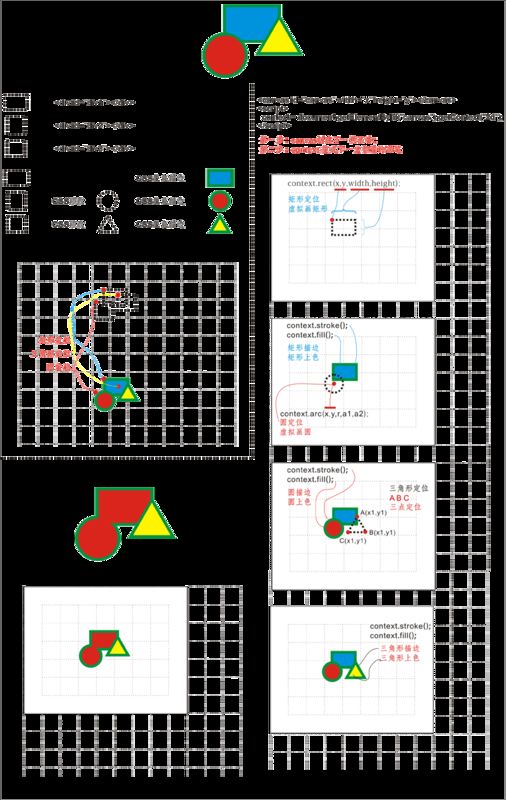
在面对曲线和更复杂图形的时候,Canvas比CSS更有办法。另外Canvas确定坐标位置的时候更加贴近我们常用到的数学思维方法。
只能显浅说说。
为什么canvas绘制的线条会模糊、有锯齿?
2017年05月30日 22:24:51
阅读数:5385
有如下的代码:
<style type="text/css">
canvas {
position:absolute;
height : 100%;
width : 100%;
}
style>
<canvas id="canvas" width="100%" height="100%">
canvas>
<script type="text/javascript">
var canvas = document.getElementById('canvas'),
context = canvas.getContext('2d')
context.translate(70, 70);
context.moveTo(0, 0)
context.lineTo(70, -70)
context.stroke();
script>
结果实际的效果虚化非常严重,清晰度非常差,锯齿非常严重,如下所示:
为什么会出现这样的情况呢?原因是canvas的宽度与高度必须作为属性明确指定(也不能通过CSS设置),并且只能是数字,不支持百分比。基于以上的规则,所以很容易找到症结,canvas绘制的图片本来较小,但经过CSS强行放大拉伸,所以就会出现模糊、锯齿严重的效果。
解决的办法很简单,在绘制之前,首先设置canvas的宽度,代码如下:
varcanvas = document.getElementById('canvas'),
// 计算画布的宽度 width = canvas.offsetWidth, // 计算画布的高度 height = canvas.offsetHeight,context = canvas.getContext('2d')
// 设置宽高 canvas.width = width; canvas.height = height;再次刷新浏览器,终于一切正常了。
结论
HTML中很多元素的宽高必须通过属性设定,而不是CSS,比如canvas,比如SVG
html5 canvas 画图移动端出现锯齿毛边的解决方法
Posted on 2017-05-19 11:01 人生梦想起飞 阅读(2748) 评论(0) 编辑 收藏
使用HTML5的canvas元素画出来的.在移动端手机上测试都发现画图有一点锯齿问题
出现这个问题的原因应该是手机的宽是720像素的, 而这个canvas是按照小于720像素画出来的, 所以在720像素的手机上显示时, 这个canvas的内容其实是经过拉伸的, 所以会出现模糊和锯齿.
解决方案一:就是在canvas标签中设置了width="200",height="200"之外, 还在外部的CSS样式表中设置了该canvas的宽度为100%,然后在画图时把canvas的的宽度设为手机端的最大像素值, 因为现在的手机端宽度的最大的只有1080像素宽, 所以就把canvas的宽度和高度设为200的6倍也就是1200像素, 按照这个像素画完之后, width:100%又会把canvas的宽度和高度缩小至父元素的宽和宽那么大, 因此整个canvas被缩小了, 大尺寸的canvas内容被缩小了之后肯定不会产生锯齿现象,解决的原理其实就是画图时候将canvas的宽和高放大一定的倍数,按照放大后的canvas宽和高画图,然后画完之后再将canvas缩小为目标宽和高,这样解决的方法存在的问题是,在PC端反而锯齿会更明白,只是移动端的效果很好,所以在pc端不需要放大倍数,实例如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
|