人脸识别:技术应用与商业实践
人脸识别,已成趋势。关于人脸识别各种碎片式的报道也层出不穷,但对于大多数人而言,依然是管中窥豹,雾里看花。本篇文章中,笔者将从技术应用与商业模式两个维度,系统性地说明人脸识别,力求让读者,尤其是在考虑AI+应用的从业者,看到全貌。

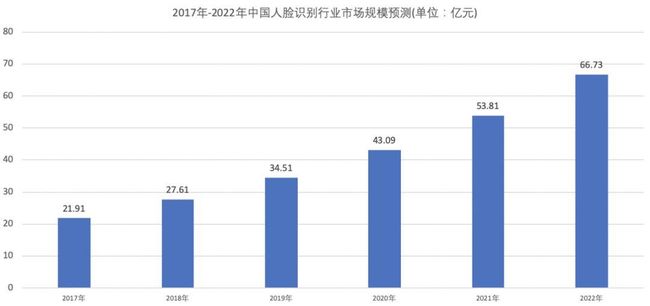
根据前瞻产业研究院对对人脸识别市场的预估,到2022年,中国人脸识别市场规模将超过66亿元。
本篇,我们先来讲人脸识别的技术应用。
基础能力决定上层应用——基础层算法
我们可能断断续续听说过人脸检测、人脸识别等算法,但这些算法之间是否有联系,是否有体系?答案的是“有的”。
我们可以将人脸识别算法分为基础层算法与应用层算法。

基础层算法,相当于人脸的预处理。一张人脸,首先要经过人脸检测、特征关键点处理,质量模型过滤之后,才能到应用层算法做处理,并应用到实际场景中。
基础层算法的优劣,很大程度上会影响最终的人脸识别准确率和效果。


应用落地,各取所需——应用层算法
目前,人脸识别在身份认证领域与互娱领域应用最为广泛;在智能交互,数据分析处理等方向上,人脸识别也在进行着积极探索。
身份认证/安防的核心功能在于确认“你是谁”,互娱领域的核心在于“人脸特效处理”;两个领域,两条赛道,分别拥有各自不同的产业链。
身份认证犹如一位思维严谨的工程师,狠抓识别准确率,防攻击等指标,并结合应用落地场景,串联业务流程,也是当下AI结合产业互联网的典型。
互娱领域就像一位钻研人性的产品经理,打造各种人脸特效,美颜、贴纸等都不在话下,并结合平台用户偏好,使用针对性的人脸特效策略,引领甚至塑造人们的审美潮流。

1. 你是谁?无介质证明身份
日常生活中,原来我们都是需要通过介质(身份证、工牌、驾驶证等)来证明身份,而以人脸识别为代表的生物识别,则无需介质。
身份认证/安防的核心技术在于活体检测、人脸比对、人脸搜索;主要用于:线上远程认证场景(金融开户、刷脸注册、刷脸登录等)、线下无人值守场景(智慧交通、人脸门禁、刷脸取款、刷脸支付等)。
(1)活体检测
是身份认证的第一步,因为首先我要确认这个人是真人,而不是视频、照片、面具等欺诈盗用行为。
活体检测的技术上,目前也主要有两大类:
- 对硬件依赖度比较低的,如动作活体,静默活体;
- 对硬件有一定要求,需要和硬件适配的,比如双目活体、3D结构光活体等。
虽然后者的成本比前者高,但是防攻击效果更好,而在线下场景中,天然的需要硬件,因而后者也成为线下场景的最好选择。
原理上,都是采集人脸照片,并将照片做上标记(真/假样本),并送到模型中训练从而得出算法。
不同的活体检测,因为样本源不一样,比如红外摄像头采集的照片,带有黑白特征;3D结构光采集的照片带有深度信息,导致识别效果也不同。
所以,活体检测的关键,除了算法、模型构造,还有一个就是图片样本本身所带有的信息量。
(2)人脸比对
是将两张人脸照片进行比对,得出相似度;第一张是现场采集的,第二张该如何得来?一般有两个来源:
- 能代表你身份的载体,比如身份证、行驶证、驾驶证等证件照,这类场景用来做金融开户、人脸注册、网约车司机认证等场景,通过现场采集照比对你的证件照信息,确认你就是本人;
- 账号下已经绑定的人脸:一般需要先输入账号,获取对应人脸。这类场景的典型应用是取代原来的密码功能,比如刷脸登录、刷脸支付等。
(3)人脸搜索
是将采集到的人脸,和底库中的人脸全部进行比对,得出相似度最高的几张人脸底库照,并得出相似度,超过一定阈值,则可以认为是同一人。
人脸搜索,无需事先得到底库人脸照,只需要刷脸即可,在线下门禁、安防、刷脸支付等领域应用广泛。当然,不同的业务领域中,根据误识的后果,对人脸搜索的容错性也不一样;比如在工地人脸识别中的容错率,就要比在刷脸支付中的容错率要低。
需要说明的是,人脸搜索的准确率,是要结合底库中人脸照片的数量来的,底库中人脸照片越多,识别准确率越低。
这个和人一样,在2~3个人中,找出你曾经认识的人,比较容易;但是上百万个人,则长相相似的人也越多,辨识更困难。目前业界做的好的一般是百万级别的人脸库,识别准确率在95%以上。
2. 从工具到社交,娱乐至上
互娱应用,也深深契合着行业发展。起初随着智能手机兴起,人们的自拍分享需求渐渐旺盛,美颜滤镜,作为与手机硬件深度结合的产品,见证着人们变美的时代,此时,算法主要由第三方算法公司提供。
随着4G时代带来,短视频社交成为人们生活热点,美颜滤镜、贴纸也应用于各大互娱平台中,并成为不可分割的一部分;对于短视频内容生产者来说,甚至已成为核心竞争力。
因此,诸如快手、抖音等平台,都以自研算法,并结合客户群画像,独自研发。
(1)滤镜美颜
滤镜是图像美化中必不可少的步骤, 所谓滤镜,最初是指安装在相机镜头前过滤自然光的附加镜头,用来实现调色和添加效果。2008年,美图一炮而红,人们发现,原来滤镜还可以这么玩,自此,美颜滤镜开始了从工具到美学定义者的转变。
早期的传统算法,主要是先使用人脸特征关键点算法,勾画有效区域,然后在不同的区域进行亮度提升、去噪声等算法,实现美颜滤镜。
随着深度学习的兴起,研究人员们开始更关注结果,设计师将原图P成美化完成后的结果图,并用于训练。人们美颜后,究竟想变成什么样?研究重心也开始偏移。
(2)人脸融合与贴纸
贴纸,人脸融合,则是更高阶的玩法。核心还是人脸特征关键点,对于贴纸和人脸融合来说,关键点的数量越多越好,对齐的越准确。人脸融合,则是将两张人脸的关键点进行融合。
3. 不断进取,跨越感知智能
人工智能承载了业界对于改造世界的期望,一定程度上说,属性识别、视线估计、GAN等,从感知智能往前更进了一步,但是因为技术不够成熟、商业应用领域狭窄等原因,至今未得到大规模商业应用。
可以说,视觉AI想跨越到认知智能,AI与AI之间相互融合,依然还有很漫长的路要走
(1)属性识别
年龄、性别,高兴、悲伤、愤怒等情绪,获取用户更多维的数据,丰富用户画像,用于个性化推荐、广告展示等场景,听着很美好,对不对?毕竟在数据为王的时代,数据就是价值。但是,商用化还是存在技术硬伤,识别准确率也就70%左右。
近日,美国等5名专家,耗时两年,查阅1000多项研究,在论文《再论人类情感表达:从人类面部表情辨别情绪的方法论面临的挑战》(论文原名为:《Emotional Expressions Reconsidered: Challenges to Inferring Emotion From Human Facial Movements》)中表示:人类情绪的表达方式及其丰富复杂,很难靠简单的面部表情识别,人们生气时,在平均不到30%的时间里他们会皱眉,故皱眉不等于愤怒,皱眉只是“愤怒”的众多表达方式之一。同时,表情和语言、情境的相关关系也非常大。
(2)视线估计
视线估计与人脸特征关键点比较像,检测完人脸之后,再检测人眼以及眼球,并锁定眼球中心等关键点位置,根据坐标来锁定视线方向。主要应用于课堂上,评估学生注意力;
AR VR等新型硬件交互,通过视线方向,自动切换视频中的位置等;广告投放,评估行人对广告的注意力;目前而言,市场体系还是比较小,未得到大规模应用。
(3)GAN
GAN全称为生成对抗网络,初衷是生成不存在于真实世界中的数据,使得AI具有创造力或者想象力,也是目前AI领域一个比较热门的研究方向。
GAN的核心网络分为生成器与判别器;生成器负责凭空捏造数据,判别器负责判断数据是否是真实数据;两个核心网络相互博弈,直至动态平衡,让生成的数据无限接近与真实数据。
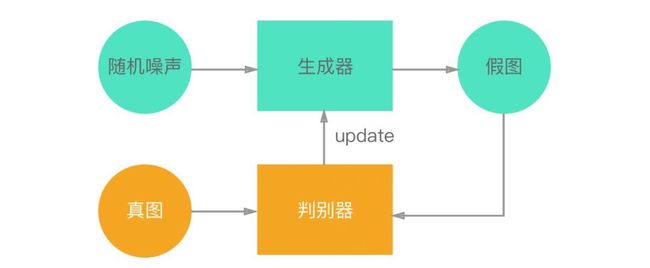
如图,随机噪声就是随机生成的一些数,也就是GAN生成图像的源头。
生成器根据一串随机数生成一个假图像,并用这些假图去欺骗判别器
而判别器通过真图和假图的数据(相当于天然的label),进行一个二分类神经网络训练,并判别输入的是真图还是假图,给出一个分值。
举个例子,真图是一系列的人脸照。起初,生成器生成的照片,肯定是乱七八糟的,但是判别器会去判断打分,告诉生成器,你生成的不是真图(人脸照),于是生成器根据深度学习,反向传播等,不断去修改自己的图片,然后,生成的图片会越来越趋近于真实人脸,直至动态平衡。
GAN受到关注,很多原因,比如:
- 本身是无监督的,目前人工智能的绝大部分能够商业应用算法都是监督算法,所谓监督算法,就是需要海量的样本,并进行人工标注,传播训练,所以行业也有“有多少人工,就有多少智能”的调侃;
- 让AI具备想象力,比如将模糊图变清晰(去雨、去雾、去抖动、去马赛克等),能脑补情节 很多paper都在研究gan的发展前景。
结语
任何技术,也都遵循着从技术发展—>技术成熟—>商业落地的发展规律。技术的池子不断创新,同时商业也从技术池中,探索合适的技术,改造世界;
人脸识别作为一项复合性技术,既拥有现在,同时也在不断开拓未来。虽然困难重重,但前景令人心动。