python-scrapy框架实例1--爬取腾讯社招的职位信息
爬去腾讯社招的职位信息
一、.第一步创建Scrapy项目,在cmd 输入scrapy startproject Tencent
二、.Scrapy文件介绍
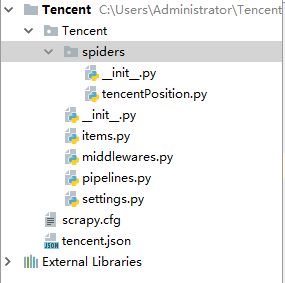
首先最顶层的Tencent文件夹就是项目名
在第二层中是一个与项目同名的文件夹Tencent和一个文件scrapy.cfg。todayMovie是模块,所有的项目代码都在这个模块内添加。
第三层有6个文件和一个文件夹(实际上这也是个模块)。实际上用的也就三个文件
分别是items.py pipelines.py settings.py
items.py文件的作用是定义爬虫最终需要哪些项
pipelines.py文件的作用是,Scrapy爬虫爬去了网页中的内容后,这些内容如何存取就取决于pipelines.py的设置了
setting.py决定由谁去处理爬去的内容
.在cmd中输入 scrapy genspider tencentPosition tencent.com
在该文件里写爬虫
三、目标任务:爬取腾讯社招信息,需要爬取的内容为:职位名称,职位的详情链接,职位类别,招聘人数,工作地点,发布时间
首先爬去第一页的职位信息
1.首先写items
将希望获取的信息名称填入items中
position=scrapy.Field() #职位名称 kind=scrapy.Field() #职位类别 person=scrapy.Field() #人数 location=scrapy.Field() #地点 publishtime=scrapy.Field() #发布时间
2.写tencentPosition
import scrapy from Tencent.items import TencentItem class TencentpositionSpider(scrapy.Spider): name = 'tencentPosition' allowed_domains = ['tencent.com'] start_urls = ['https://hr.tencent.com/position.php?&start=0#a'] def parse(self, response): subSelector=response.xpath('//tr[@class="even"]| //tr[@class="odd"]') items=[] for sub in subSelector: item = TencentItem() item['position']=sub.xpath('./td[1]/a/text()').extract()[0] item['kind']=sub.xpath('./td[2]/text()').extract()[0] item['person']=sub.xpath('./td[3]/text()').extract()[0] item['location']=sub.xpath('./td[4]/text()').extract()[0] item['publishtime']=sub.xpath('./td[5]/text()').extract()[0] items.append(item) return items
3.写pipelines.py 保存为json格式
import json
class TencentPipeline(object):
def __init__(self):
self.filename = open("tencent.json", "wb")
def process_item(self, item, spider):
text = json.dumps(dict(item),indent=2, ensure_ascii=False) + ",\n"
self.filename.write(text.encode("utf-8"))
return item
def close_spider(self, spider):
self.filename.close()
4.写settings.py
ITEM_PIPELINES = {
'Tencent.pipelines.TencentPipeline': 300,
}
5.运行文件 在Tencent文件下输入 scrapy crawl tencentPosition
爬取所有页数的信息
import scrapy from Tencent.items import TencentItem class TencentpositionSpider(scrapy.Spider): name = 'tencentPosition' allowed_domains = ['tencent.com'] url = "http://hr.tencent.com/position.php?&start=" offset = 0 # 起始url start_urls = [url + str(offset)] def parse(self, response): subSelector=response.xpath('//tr[@class="even"]| //tr[@class="odd"]') items=[] for sub in subSelector: item = TencentItem() item['position']=sub.xpath('./td[1]/a/text()').extract()[0] item['kind']=sub.xpath('./td[2]/text()').extract()[0] item['person']=sub.xpath('./td[3]/text()').extract()[0] item['location']=sub.xpath('./td[4]/text()').extract()[0] item['publishtime']=sub.xpath('./td[5]/text()').extract()[0] items.append(item) yield item if self.offset < 1680: self.offset += 10 # 每次处理完一页的数据之后,重新发送下一页页面请求 # self.offset自增10,同时拼接为新的url,并调用回调函数self.parse处理Response yield scrapy.Request(self.url + str(self.offset), callback=self.parse)
6.将爬取到的数据保存到MYSQL 中
import MySQLdb class TencentPipeline(object): def process_item(self, item, spider): position=item['position'].encode('utf8') kind = item['kind'].encode('utf8') person = item['person'].encode('utf8') location = item['location'].encode('utf8') publishtime = item['publishtime'].encode('utf8') db=MySQLdb.connect('localhost','root','19950423','test',charset='utf8') cursor=db.cursor() cursor.execute('use test') '''cursor.execute('DROP TABLE IF EXISTS position_store') cursor.execute('CREATE TABLE position_store(position char(45) NOT NULL,kind char(45),person char(45),location char(45),publishtime char(45),PRIMARY KEY(position))')''' cursor.execute("INSERT INTO position_store(position,kind,person,location,publishtime) VALUES (%s,%s,%s,%s,%s)",(position,kind,person,location,publishtime)) db.commit() cursor.close() cursor.close() return item