数据分类算法之KNN算法
一、KNN算法介绍
在现实生活中我们会遇到要把大量的数据进行分类的问题,这个时候一些常见的分类算法就可以对数据进行分类了。一般有1.KNN算法 2.贝克斯算法 3.决策树 4.人工神经网络 5.支持向量机(SVM)等很多分类算法。我们这里讲解一下KNN算法的原理及其编程方法。

我们通过一个简单的物品销售数据分类来讲解KNN算法的原理,首先我们拿出三类数据:三种零食(a,b,c),三种金饰(d,e,f),三种跑车(g,h,i)。建立一个坐标轴,横轴是商品价格,纵轴是商品销量,我们可以发现零食一般价格低、销量高。金饰一般价格中等、销量低。跑车一般价格高、销量高。所以在上图可以将他们分为3类,这时候想知道一个数据m是什么,就可以通过KNN算法来实现:
- 假设m(xm,ym),a(xa,ya)…..
- 计算m点与a,b,c,d,e,f,g,h,i各点的距离,并按照从小到大顺序排列。
- KNN算法中的k便是取上面排列好的距离中的前k个距离,假设我们取k=3,最后就取出来3个离m点最近的点,假设为d,e,b。
- 我们发现d,e,b中金饰占了大部分,所以可以近似认为m是金饰,这样就可以对数据m进行分类了。.
使用KNN算法,先利用总数据的70%进行训练,再用30%进行测试,看看最后是否达到预期。
二、KNN算法编程
from numpy import * #导入numpy模块下的所有用法,用来计算矩阵
import operator #这个模块主要用来对距离进行排序
def knn(k,testdata,traindata,labels): #指定k值、测试数据、训练数据、类别名(零食,金饰...)
'''
因为要进行距离计算(x1-x2...xn-yn),所以测试集和训练集的列数要一样(就是说有30个测试集,70个训练集,
我们在做差值求距离时,训练集每个数据有xn个,我们就要把测试集数据也要扩展成xn个,这样两个向量才能相减)
测试集的个数就是它的行数 但是列数我们并不知道 要把列数扩展为训练集列数。
我们用tile()进行扩展,举一个小例子:
from numpy import *
a=array([1,5,6,4])
tile(a,2) #结果是:array=([1,5,6,4,1,5,6,4]) 从行方向扩展
tile(a,(2,1)) #结果是:array=( [1,5,6,4] 从列方向扩展
[1,5,6,4])
'''
traindatasize=traindata.shape[0] #得到训练集的列数
dif=tile(testdata,(traindatasize,1))-traindata #计算扩展之后的距离差值
sqdif=dif**2 #差值得平方 [(x1-y1)^2,(x2-y2)^2.....(xn-yn)^2]
sumsqdif=sqdif.sum(axis= 1) #每一行的各列求和,axis=0是每一列各行相加
distance=sumsqdif**0.5 #得到最终距离
#将距离排序,举个例子:
'''
c=[2,15,10,6]
c.argsort()
结果:[0,3,2,1] 把原来的下标进行了排序
'''
sort_distance=distance.argsort()
count={} #存数据
#选择距离最小的k个点
for i in range(0,k):
vote=labels[sort_distance[i]] #传进来的参数labels,把前k个数据的类别给vote
'''
统计哪个类别出现的多:
a={}
a[5]=a.get(5,0)+1 #结果:a{5:1}
a[5]=a.get(5,0)+1 #结果:a{5:2}
'''
count[vote]=count.get(vote,0)+1
#得到了count字典 {种类1:次数,种类2:次数.....} 得到次数最多的种类
sortcount=sorted(count.items(),key=operator.itemgetter(1),reverse=True) #key中的1是排序count中的次数 reverse=True是降序排列
#排序之后取第0个元素 (种类:次数) 中的第0个元素 (种类)
return sortcount[0][0] #这样就得到了排序之后出现数据最多的种类了三、实战分析:识别数字1-9
这里我们进行一个实战的简单讲解,让大家了解一下如何使用KNN算法:
(1)第一步我们建立训练集
from os import listdir
from numpy import *
def traindata(): #1_21.txt 要得到类别(1)和训练数据(21)
labels=[]
# import os listdir 得到文件夹下所有的文件名
trainfiles=listdir('C:/Users/dell/Desktop/python练习/data fenxi/data fenlei/trainingDigits')
n=len(trainfiles)
#先生成一个向量 列:32*32=1024
#用一个数组存储所有训练数据,行(文件数) 列(1024)
#通过numpy的zeros((m,n))
trainarr=zeros((n,1024))
for i in range(0,n): #每一个文件循环一次
thisfname=trainfiles[i] #第i个文件
#文件分割得到类别和数据
thislabel=seplabel(thisfname) #得到文件类别
labels.append(thislabel) #将类别传入labels中
trainarr[i,:]=datatoarray('trainingDigits/'+thisfname) #n行 trainarr[i,:]第三次时候只存在第三行后面
return trainarr,labels(2)第二步我们利用knn算法对数据进行测试
#用测试数据去测试
def datatest():
trainarr,labels=traindata() #拿到训练集
testlist=listdir('C:/Users/dell/Desktop/python练习/data fenxi/data fenlei/testDigits') #拿到测试集
n1=len(testlist)
for i in range(0,n1): #每个测试文件测试一次
thistestfile=testlist[i]
#加载为数组
testarr=datatoarray('testDigits/'+thistestfile)
#调用knn
result=knn(3,testarr,trainarr,labels)
print(result )
datatest()以上代码仅仅是主要代码,仅供参考,有需要源代码可以在下方评论。
结果:可以准确识别测试集中的数字。
随机抽取一个进行测试:

测试电脑是否可以识别出数字9
trainarr,labels=traindata()
thistestfile='9_80.txt'
testarr=datatoarray('testDigits/'+thistestfile)
result=knn(3,testarr,trainarr,labels)
print('我觉得数字是:',result)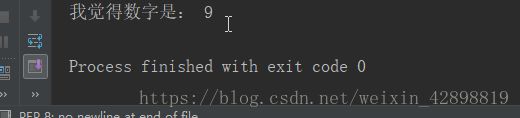
最后发现代码成功。