Tesseract-OCR中文语言包缺失的解决办法
介绍
Tesseract-OCR 5.0的win安装包即使选中中文也会出现无法安装中文的状况,官方文档给出的解释是自己下载语言包即可,但是github下载整个仓库实在是太庞大了,因此这里单独git中文语言包。
后来git Github的时候发现还是很慢,于是转站码云。
如果你懒的操作,我也做好了压缩包,直接拿走不谢
https://download.csdn.net/download/weixin_43031092/12331633
但是有一个问题就是码云上的数据是就的怎么办?
很简单,把下图中的网址换成官方的:
https://github.com/tesseract-ocr/tessdata.git
缺点就是github网速慢!!!
git单文件拉取
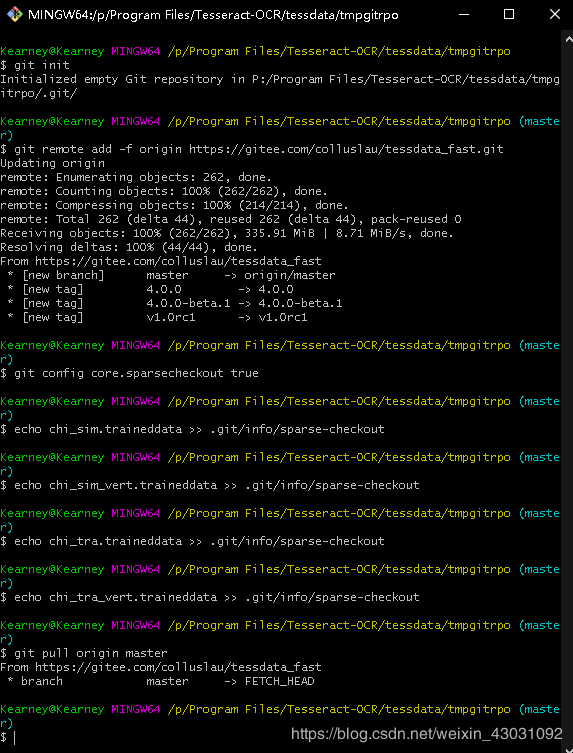
我是在tessdata下新建了一个文件夹tmpgitrpo用来拉取文件。按如下代码操作即可拉取四个中文语言包。
Kearney@Kearney MINGW64 /p/Program Files/Tesseract-OCR/tessdata/tmpgitrpo
$ git init
$ git remote add -f origin https://gitee.com/colluslau/tessdata_fast.git
$ git config core.sparsecheckout true
//四个echo用来添加要单独拉取的语言包
$ echo chi_sim.traineddata >> .git/info/sparse-checkout
$ echo chi_sim_vert.traineddata >> .git/info/sparse-checkout
$ echo chi_tra.traineddata >> .git/info/sparse-checkout
$ echo chi_tra_vert.traineddata >> .git/info/sparse-checkout
$ git pull origin master
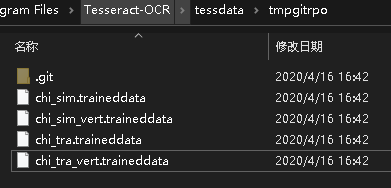
拉取完四个文件后将四个语言包剪切到tessdata下即可。然后把临时文件夹tmpgitrpo删掉即可
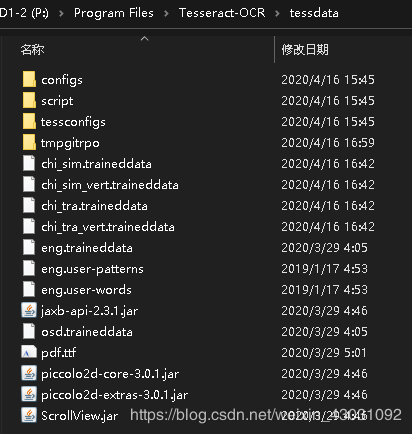
测试
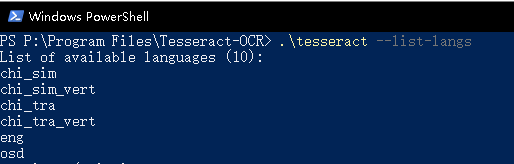
进入:\Program Files\Tesseract-OCR目录按住shift鼠标右键进入powershell
输入如下命令
.\tesseract --list-langs
参考
- https://gitee.com/colluslau/tessdata_fast?_from=gitee_search
- https://www.jianshu.com/p/74a0441ed9b7
- https://github.com/tesseract-ocr/tessdoc/blob/master/Data-Files.md
- https://github.com/UB-Mannheim/tesseract/wiki/Install-additional-language-and-script-models