2019.04.22-2019.04.28论文阅读笔记
2017_CVPR_Zhu_Semantic Amodal Segmentation
由FaceAI公司提出的一个新的任务(和数据集),侧重在任务的提出和数据的标注工作。
至于为什么会看到这篇文章,因为Kaiming He在2018 arXiv的Panoptic Segmentation中引用了这篇文章,目前本文引用量为20。
Motivation:
人在进行场景感知和理解的时候,如果碰到某个物体被遮挡了一部分,人会自动脑补出该物体的整个边缘,而不是像分割任务那样仅仅只能感知到可见的部分,这个已经在心理学被广泛研究,最有名的如Kanizsa的三角形,如下图:

这些空间分离的碎片给人一种明亮的白色三角形的印象,由一个尖锐的虚幻轮廓定义,遮挡三个黑色圆圈和一个黑色三角形。
人类可以感知到由空间碎片而形成的物体的形状,也就是说针对遮挡有一定的鲁棒性,那么如何让计算机同样具备这样一个能力,就是一个需要去解决的问题。
于是提出了amodal segmentation的任务,任务的目标是:针对图像中每个区域的完整部分进行标注,而不仅仅是标注可见部分。如图:

图中的狐狸,树干等物体,不仅仅是标注了可见区域,同样有一部分不可见区域也是通过脑补标注出来了。同时,还有物体之间的前后关系,比如哪个实例在最前面,哪个在中间,哪个在后面。
这样一来引出了一个非常关键的问题,如果多个标注者来标注同一张图片,他们针对看不见的部分的脑补会是一样的吗?文章中回答了这个问题,他们要求标注者标注BSD里面的500张图片,而且鼓励他们尽量去考虑物体之间的关系和场景与物体之间的几何关系。他们得出的结论是每个标注者之间的标注一致性非常强,同时,这样标注出来的数据有着更强的区域和边缘一致性,标注者也更愿意标注这样的数据。
这样一来amodal segmentation的任务就很明确了,通过以上数据,输入一张RGB图像,生成场景中每个实例的mask,并给出mask之间的前后顺序。另外,这个mask是针对整个物体而言的,而非仅仅只是将可见的区域标记出来。
Dataset:
一开始标注了BSD的500张图像,后来以COCO为原型,标注了500张图像。
2500/1250/1250用于训练/评估/测试。
并同时在一些Object Segmentation上进行了实验。
感觉本文关键之处在于提出了这个amodal segmentation的问题,并为此标注了一个5000张的数据集。
2018_arXiv_Learning to Fuse Things and Stuff
是TOYOTA(丰田)公司的一篇文章,用来做全景分割的。
本篇文章看下来非常难受,感觉这是一篇工程报告,在第二页就开始说具体的细节,具体参数怎么设置,而通篇没怎么看到motivation。不过鉴于Hengshuang Zhao他们引用了这一篇文献所以还是看看。
提出了TASCNet,其中TASC代表things and stuff consistency,整体网络结构如下图所示:
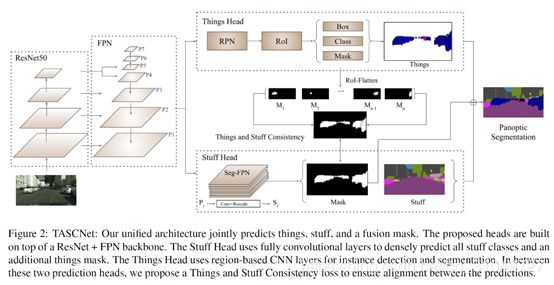
输入图片之后,用一个ResNet50来提取特征,然后输入FPN网络中,然后分别输入语义分割网络头和实例分割网络头。TASC是指从实例分割网络头中输出的结果,用所有的instance的mask合并生成一个包含instance的二值图(用ROI-Flatten,其实就是每个instance用一个阈值来确定区域,然后在整个区域里面取了一个并集),同时,语义分割网络也会给出一个针对于前景目标的二值图。两个二值图中间会有一个对齐的过程(其实就是二范数),使得两个图趋近于对齐。最终,将语义分割图,二值图,实例分割图一起用于做全景分割图的生成。
总结一下,这篇文章写得非常的“报告”。没有说motivation,没有insight,只是单纯说了用了什么方法,得到了什么结果。前面的related works也总结的没什么逻辑性。感觉看这个格式和挂在arXiv的时间是投2019CVPR之后被拒掉了。真是非常印证了大牛们说的“How to get paper rejected”里面的话。他们用的结构和Hengshuang Zhao用的结构几乎一样,所以从另一个层面说明文章包装的重要性。
2018_arXiv_Panoptic segmentation with a joint semantic and instance segmentation network
同样是一篇全景分割的文章,是荷兰的艾因霍恩大学的。同样是挂在了arXiv上,第一版2018.09挂出,第二版2019.02。感觉很明显是投了2019CVPR被拒之后重新修改投了2019ICCV。看摘要跟上篇文章挺像的,写作风格也很像,在摘要里面就说细节了,写作姿势不对(甚至把related work的内容放到了introduction里面,introduction没有insight),看完之后要赶紧看两篇好文章,不然都快忘了本来应该写什么了。
不过既然UPSNet引用了这个,还是稍微看一下。

网络结构没什么好说的,文章的重点在后期得到语义分割图和instance分割图之后使用一个启发式方法进行融合,也就是上图的Merging using Heuristics。
针对stuff类别,针对instance map的融合,采用非极大值抑制。这样的话会丢失一些真实区域,所以利用每个instance的置信度图来缓解两者(语义分割和实例分割)之间的冲突。实际上感觉就是跟目标检测一致,那个目标的置信度高就保留哪个。
针对things类别,直接在语义分割图中将things的类别去掉,然后将那些区域用置信度最高的stuff类别代替。然后再用instance 的类别在图上进行替换。
读到这里,我感觉这个文章以后估计都不会中了。真的是一点novelty都没有,写的也挺差的,就当踩了个雷。
2018_CVPR_Jo_Deep Video Super-Resolution Network Using Dynamic Upsampling Filters Without Explicit Motion Compensation
延世大学的一篇视频超分文章,被引9次。
Motivation:
基于视频的超分方法一般来说有两种思路,一种是将基于单帧图像的超分方法对视频中的每一帧进行操作,但是这样的话会因为缺少了视频中每一帧之间的相关性,导致会在某一帧突然出现artifacts。另一种是纯做视频的超分方法,传统视频超分算法使用多张LR图像作为输入,将超像素之间的运动作为因素考虑在内,然后输出HR图像,基于深度学习的方法也大体分为两步:①运动估计②运动补偿,将多帧图像作为输入,估计运动状态,然后进行运动补偿。但是这样也会有问题:太依赖于精确的运动估计,同时由于混合了多帧的运动补偿作为CNN输入,输出通常都是带有模糊的。
所以本文中希望能够将运动信息不再显示建模,而是隐式用于生成一个动态的上采样滤波器。因为没有多帧的动态补偿作为输入,所以生成图像会更加锐利。
同时,采用了一种新的数据增强的手段,用以更好的训练网络。
Architecture:
网络结构如下:

将多帧同时作为输入,然后经过卷积,分别输入到两个子网络,一个用于生成动态滤波器,另一个用于生成高精度的残差(Residual)。然后生成的动态滤波器对于图像进行卷积,生成高分辨率图像,并最终和残差相加用以找回细节。

其中动态滤波器相关操作如上,超分4倍则生成16个channel,并针对16个channel用CNN生成动态滤波器,然后卷积并按顺序插入到高分辨率的对应位置上。
针对于数据增强的方法,好像没看到?不过他们想在VSR领域做一个类似ImageNet的数据集,于是从网上收集了351个视频,然后做了160000张144*144的实测数据。然后留了4个视频用作validation,1个视频用作test。
总结一下,提出了一个新的数据集,分析了以前视频超像素的两种方法的优缺点,然后基于上面的优缺点来提出动态滤波器超分的方法。
个人觉得这个motivation还是很足,每一步骤为什么这么做都说明了。因为本身超分的文章看得少所以不太能对方法本身做评价,但是这篇文章我觉得的确是标准的顶会文章,该有的都有了,包括motivation、related works、architecture、Implementation Detials、Experiment、Ablation Analysis等。
- 2019_IJCV_The Devil is in the Decoder Classification, Regression and GANs
从Deeplab的一作Liang-Chieh Chen的主页上找到的文章,2019年3月19号第一次被IJCV上传。目前暂时没有引用。
文章分析了当前大部分算法设计趋势,并且指出了当前算法过于倾向于设计更优质的特征提取器。
下图来自https://www.jianshu.com/p/2750e8cfb08e:

2014_ECCV_Zeiler_Visualizing and Understanding Convolutional Networks
2014年ECCV的一篇CNN的经典文章。第一次将网络中间的特征图进行可视化,然后分析网络每一层都在干些什么。作者是Hinton的得意门生,目前引用次数5884次。
Motivation:
当时神经网络已经取得了非常好的效果,在ImageNet上的表现为16.4%的错误率,大大超越了第二名的成绩(26.1%)。但是,到当时为止,没有一个对于网络为何这么做以及为什么效果这么好的一个解释,这对于科学研究是很不好的。
所以这篇文章提出了一个可视化的操作用于卷积神经网络,让我们有能力将网络中的每一层的特征图拿出来进行分析。
当时可视化特征图是一个常见的办法,但是仅限于第一层(像素之间的投影关系确定),中间层的可视化是没有人做的。
方法:
从2011年Zeiler的反卷积网络文章中获取灵感,在每一层后面加上了一个专门用于做反卷积操作的层,如图:
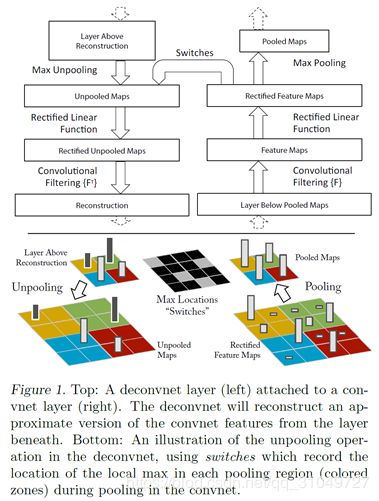
右边是正常的卷积,左边是反卷积。正常卷积网络中是卷积—激活函数—池化,在反卷积里面就是反过来的操作,反池化—激活函数(因为都是激活所以不变)—反卷积。
其中反卷积操作是用正常卷积卷积核进行转置然后再进行卷积的。至于池化,由于池化过程本身是不可逆的,所以只能采取近似方法。在正常池化的时候记录下最大值的位置,然后将值填入最大值的位置中,其他部分置0。不是完全恢复到池化之前的样子,只是做一个近似。
可视化结果:

该图不仅仅是展示了每一层最强的响应,而是展示了top9的响应。
可以看到,第二层主要响应了边和颜色信息;第三层响应更为复杂,捕捉了其中的相似纹理;第四层的响应比第三层还要复杂,针对每个类别有明显不同;第五层针对目标的显著姿态变化有相应。进一步说明神经网络是分层进行学习的,有简单逐渐到难的过程。
从左到右分别为训练 个epoch的特征图。

可以看到前面几层很快就收敛了,但是后面的层需要更多的epoch才能够收敛

测试了一下再有遮挡的情况下的响应图,比如第一列,当狗的脸是相应最强的,当狗的脸被遮住的的时候,分类的性能会急剧下降,即神经网络的最强响应区域的确是跟最具判别性的区域。
2015_CVPR_Hariharan_Hypercolumns for Object Segmentation and Fine-grained Localization
目标检测RBG大神的文章,2015CVPR,目前引用量859。
至于为什么会读到这篇文章,也是因为它里面讨论了SDS,即simultaneous detection and segmentation的问题。有点后面实例分割的意思。
Motivation:
识别任务一般是拿CNN的最后一层输出作为提取出来的特征,但是最后一层的信息太coarse,在预测位置的时候不能准确预测,前面的层在位置上比较准确,但是不能捕捉到语义信息。
当然,当这个任务是图像分类的时候,用最后一层的输出是非常make sense的,因为最后一层一般都是最具有语义信息的。但是,一旦涉及到更为精细化的任务(如检测和分割),只用这一层的效果就不会特别好了。
比如,在条状检测时,一开始的几层里面条状物体是能够明确被定位的,但是没办法区分这个条状物体究竟是什么,可能是护栏,马腿,树干,而后面的几层中,是没有非常明确的位置信息。
这个观察就表明了使用多层的特征是非常重要的。那么就把前后的特征都利用起来吧。提出了hypercolumn的东西,借鉴神经学的一个概念,如下图:

在本文中,将卷积神经网络当作一个金字塔形状的图像的一系列副本。然后从这个金字塔形状的一系列特征中间抽取,组成hypercolumn。
实际上网络结构如下:

在中间层抽出特征,然后上采样到一样的大小,然后concat起来之后在经过激活,最后输入到分类器中,这样既能保证语义信息,也能够保证了位置信息。
2015_CVPR_Szegedy_Going Deeper with Convolutions
大名鼎鼎的GoogleNet,目前12840次引用。
首先介绍了目前神经网络的发展,总结了两个特点:
- 更多的成果并不是靠多厉害的硬件、更大的数据集和模型的,而是主要靠新的idea、算法和网络结构。
- 现在网络也更加注重计算的有效性。顺便说GoogleNet在inference的乘加操作基本上实在1.5billion上,即1.5GFLOPS,所以不仅仅可以用在学术用途上。
目前的高层任务中,想要提升性能,最直接的办法就是加深加大网络模型,但是这样会带来两个缺点:
- 更大的模型意味着更大的参数量
- 更大的模型也就意味着更大的计算消耗
所以基于神经学中的一个叫赫布理论的东西,把神经元们互相联系到一起,计算能力会增加几倍(Hebbian principle – neurons that fire together, wire together)。所以提出要充分利用了网络内部的计算资源,在增加网络内部深度和宽度的同时,使得计算负载不变。
一开始的基本思路是想用多个网络模块的堆叠来完成近似局部稀疏的网络结构。所以构建了以下模块:

接下来的第二个想法就是在一些计算需求会显著增加的部分果断降维。(我觉得在这里就是指的1*1的卷积的作用了)
Inception Network是一系列的上述Inception模块构成的,偶尔会有2倍降采样的最大池化层。
最后就是提出了GoogleNet,利用线性激活,1*1、3*3和5*5的卷积,224*224的输入来构成网络。

2018_CVPR_Zamir_Taskonomy Disentangling Task Transfer Learning
2018年CVPR的bestpaper,工作量非常巨大,感觉可以说那年CVPR估计没有任何一篇文章工作量比这个更大了。是做迁移学习方面的文章,目前引用次数66。
Motivation:
视觉任务是高度相关的,那么,视觉任务在处理的时候为什么需要每种网络都独立设计独立训练呢?为什么不能用一个相对统一的网络来完成多个事情呢?
还有一点,比如分割问题是直接将ImageNet上训练好的网络模型直接拿过来作为backbone,这样做到底好不好?
基于以上观察,希望能够完成一件事情,即在迁移学习的过程中,通过少量的训练样本和其他任务已经训练好的网络模型来直接完成迁移学习任务。
所以他们提出了一个可以完全通过计算得到的空间视觉任务之间的度量准则。一共是衡量了26个视觉任务,包括2D、2.5D、3D等领域的视觉任务,通过计算,产生一个分类的map,用于迁移学习。
给出示意图如下:

发现如果能够得到一个已经训练好了的surface normal的网络,和一个封闭边界检测网络,通过两者结合,可以用很少的数据来训练reshading网络和点匹配网络。
这样一来,证明了这个想法的可行性,进而针对26个视觉任务都做了任务之间的相关性度量。
任务的整理流程如下:
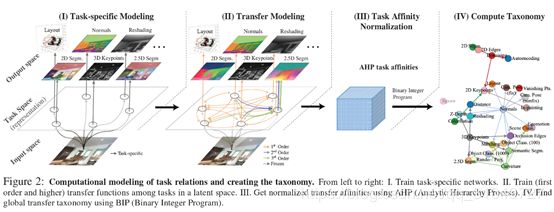
分为四个步骤:
- 针对每个任务进行单独的训练,获得每个任务独立的模型。其中特征提取的部分基本上保持一致,提取了特征之后,再通过任务独立的网络头来得到对应任务的结果。
- 在特征层面将不同任务之间进行迁移,比如1st order既代表了某一个任务对另一个任务的迁移,2nd order代表了同时用两个任务的模型来迁移到某个任务上去,同理,3rd order 的模型代表了同时有三个任务迁移到了同一个任务上去。其中,迁移的过程就是将两个特征进行concat。
- 然后计算一个任务之间的相似性。通过将不同人物的组合迁移到某个特定的任务,那个特定任务的性能优劣肯定是不一样的,这样一来就可以得到一个向量,向量的每个值都代表的是和其他人物之间的关联性。最终所有的任务之间的关联可以构成一个矩阵/张量。针对于每个向量来说,还使用了AHP算法进行归一化操作。
- 最后根据上面的关联性矩阵可以计算出任务之间的相关性(可迁移性)。最终得到一个任务之间的可迁移性的表。
后面具体计算过于复杂,没怎么看懂,就略过去了。
作者给出了一些示例(26个任务中的24个结果):

2016_NIPS_Jia_Dynamic filter networks
动态滤波器,在上面延世大学的视频超分文章中提到的,目前引用次数162次。
Motivation:
在经典CNN中,一旦训练完成之后,卷积层中的滤波器就确定下来了,无论输入是多少,都是用的同一个卷积核来进行卷积操作,这一点是有违常理的。尤其是在图像生成等需要输出特异性的领域,也是所有卷积操作的卷积核都是固定下来的。
于是想有一个输入自适应(即以输入作为condition,动态生成的)卷积核。即Dynamic Filter Networks(动态滤波网络),也就是说针对特定输入会选择特定的卷积核来进行卷积,并由于动态滤波的自适应性获得了很好的效果。这样学习出来的不仅仅可以是传统意义上滤波操作,还能学习到包括局部空间转换、模糊以及去模糊、自适应特征提取等操作
该网络重点在于动态滤波的部分,该部分分为两个块,一个是动态滤波器生成模块、一个是动态滤波层,如下图:
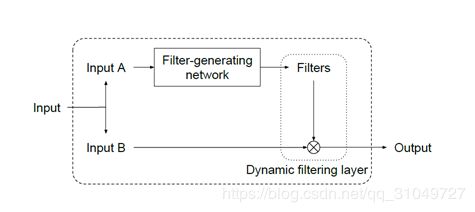
由输入生成动态滤波器,然后动态滤波器输入到动态滤波层来对网络输入进行卷积,整体架构非常简单。
但是我看了这篇文章之后,有一个疑问在文章中没有解答。就算用了动态滤波器网络生成了针对特定输入的滤波器,但是这个生成网络的参数也是固定的,也就是说,实际上整个网络里面的参数固定下来的,给定输入,输出就不会变,那么他之前说的那部分动态滤波的motivation就感觉不成立了。怎么去保证动态滤波器学到的就是与输入相关的而不是因为其他原因而改变?我觉得这些问题还是需要去回答的。
最后文章还比较了和ResNet的差别,感觉就是在ResNet的skip上添加了一个动态滤波器生成的模块,然后连接回来的时候改变卷积核。
2018_CVPR_Urooj_Analysis of Hand Segmentation in the Wild
自然场景中手的分割相关文章,主要做手在第一人称自然场景中的分割,目前引用10。
这篇文章的模型没有什么特别的,重点在于做了大量的实验和一个大样本的数据集标注。然后利用这个数据集做了一些实验。
Motivation:
以前第一人称的视频中的视觉任务,大都是做目标检测和运动检测。对于第一人称的手的检测和分割这方面的工作还很少。所以他们希望做这方面的事情。
接下来分析了一下第一人称和第三人称视频中手部检测(分割)的区别。第一人称的视频相比于第三人称一般包含更迅速的光照变化,相机的高速不确定性运动,不正常的视点变化,明显的运动模糊,和复杂的手部形状的改变。另外,摄影设备穿戴者是不会被捕捉到影片中,所以从其它方法来确定手部位置会变得更为困难(比如通过人体的姿态检测等方法确定手部位置)。因此,正因为第一人称视频和第三人称视频之间的gap,导致第一人称手部检测是不能够直接套用第三人称手部检测的方法的。
在这篇文章之前,只有一个第一人称的手部检测数据集——Ego-Hands和GTEA,其中包含手部的像素级分割。
但是其实没有自己提出新的方法,主要在Ego-Hands上对RefineNet进行了fineturn,然后发现结果比当时最好的手部分割效果都要好。说明了用语义分割来解决第一人称手部检测分割的问题的有效性。此外,还通过实验验证了CRF能够改善手部分割的效果(这个也是在语义分割领域很早就有这样做的,比如DeepLabv1)。此外,修改了AlexNet来对动作进行预测。
从上面可以看出,在模型上面没有什么可以说的,全都是直接套用了别人的模型或者简单修改了一下,其实重点还是在于数据集。
他们提出了两个数据集,一个是EgoYouTubeHands(EYTH)dataset,从YouTube上获取的非受控情况下的第一人称手部视频。他们每五帧标注一张,共标注了约1290张。2600个手部实例,1800个第一人称手部实例。
另一个是HandOverFace,从网上找了300张图像,其中手部是封闭的(为了研究皮肤相似性?)?这句话没太看懂。这个数据集中除了像素级别标签之外还有左手和右手的标签。
下图b和d是他们自己的标签。

2016_ECCV_Newell_Stacked hourglass networks for human pose estimation
800次引用,是比较早做深度学习姿态检测问题的文章(并不是最早)。不过提出的沙漏形式的网络倒是经常会被用于各种网络之中。上次paper reading师兄提到了这个就拿过来看一下。
它主要的中心思想在于,既然需要不断地降采样,上采样,那么在降采样的时候信息丢失了怎么办,那就用一个不降采样的通路来将信息给过去。也就是说实际上是类似Unet的结构,但是与Unet不一样,在skip上加上了卷积,使得网络可以学习这条支路上的参数。
单一的hourglass的结构如下:

如同一个沙漏,所以叫hourglass,这个模块之中就和我们刚才讲的是一样的,在对应大小的feature之间添加了一个带卷积的skip。
多个hourglass堆叠起来就是一个大的网络,示意图如下:
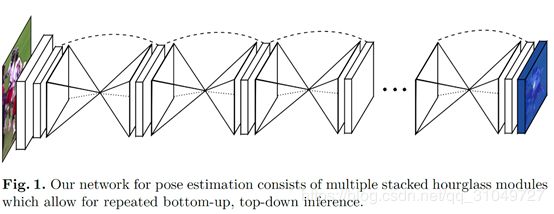
总的来说,以前好像也见到过这种不断上下采样的网络,不过这好像是我见过最早的这种不断上下采样的网络结构。还需要注意到,每个hourglass中间是有residual block存在的,正好是那年Kaiming He发表ResNet之后。
- 2013_CVPR_Tighe_Finding Things Image Parsing with Regions and Per-Exemplar Detectors
比较早有了语义分割和全景分割的雏形的工作了,目前共201次引用。
Motivation:
这篇文章重新说了一下图像理解的系统,定义了自己的图像理解是标注图像中每个像素一个带有语义的类别标签,并且这样一套系统需要有很广的涵盖范围,具体来说就是能够识别并标记成百上千个我们在生活中经常会出现的类别。
同时,定义了一下stuff和其他的countable的类别(things)。
Stuff是组成一个image的主要成分,主要有路、天空、树、建筑等组成,他们类别少,但是是image的主要组成成分,也就是说一般来说image中都会有这些东西。
Thing的代表例如人、车、狗、邮箱、花瓶、停车告示牌等一些可以计数的物体,他们的类别非常多,但是每张图片中一般只会出现较少的instance,类别也不会出现的非常全面。
此外对stuff和thing两个类别进行分析,stuff类别是没有一致性的形状的,但是他们一般会有一致的纹理特征,所以一般可以使用基于像素级别或者区域级别特征的场景理解系统来对其进行很好的建模。但是针对thing这个类别,现有的一般是先用类似HOG、DPMs来提取特征,然后在特征上进行滑窗检测。但是这样的方法一般只能获得bounding box,而从bounding box获取像素级别分割是很难的而且容易出错,所以很多复杂的监测系统会使用隐式模型来建模形状信息。
基于上述的观察和分析,他们认为要完成image parsing这件事情,是需要将stuff和thing分别对待的。
针对stuff,直接使用基于区域的场景理解手段来给出分割图,针对things,他们提出用per-exemplar detector来代替sliding window的检测器。这样不仅比sliding window更为高效,同时可以直接通过该方法给出的置信度图来直接获取目标的mask,解决了从bounding box到mask的问题。
具体流程如下图:

相当于两路,一路用基于区域的检测来给出stuff的检测结果,然后另一路用per-exemplar detectors来检测之后给出每个类别的置信度图并声称mask,最后将两者合并。
2013_ICCV_Eigen_Restoring An Image Taken Through a Window Covered with Dirt or Rain
较早的一片神经网络去rain drop的文章,在看FCN的时候发现的。Rob Fergus组的文章,目前183次引用。
本篇文章可能是第一篇将CNN用于去rain drop的文章?(存疑,目前没看到更早的)
在室内往室外拍摄或者透过玻璃/窗户拍到的图片,由于下雨或者其他原因,经常会有着一些artifacts,导致成像质量变差,图像退化。进而,他们提出了一个图像处理解决方法,可以去除单幅图像局部的雨和脏污造成的artifacts。此外,还收集了一个数据集,其中正常图像和退化图像匹配,用以训练CNN
虽然说了这些rain drops和传统图像复原领域的噪声有很多相似的地方,同时去噪问题在图像复原领域已经被广泛研究,但是这篇文章不把雨滴作为一个结构性的噪声来对待,方法仅仅依赖于这些artifacets是对焦对好的,因此这些图片不需要在窗户附近去拍摄。
所以去rain drop的问题和传统意义上的去噪问题还是有很大的区别的,因为一般噪声还是假设为高斯噪声。这个问题其实更像散粒噪声,但是和散粒噪声有不一样,因为rain drop是多像素的且是有结构性的,所以导致一般的双边滤波无法生效。
所以,提出了用一个CNN来完成所有的事情,使用一个CNN来预测clean patch,输入为一个干净的或者脏的patch。这个方法不需要图像里面的退化等级(跟噪声的退化等级对应),同时,如果需要的话可能还要对rain drop里面的区域进行inpainting。同时将多任务和快速的inference结合起来,直接一次完成所有任务。
最后还提到了,虽然训练起来的时候很麻烦,需要收集成对的训练数据,但是在测试的时候直接就可以很简单的进行下去。也是说明之前那个观点,CNN训练麻烦但是inference很简单。
文章里面没有像现在的深度学习里面摆好整个网络的结构示意图,用了很多公式来说明每个步骤是怎么做的。网络算是非常简单,但是效果看起来还比较不错。也估计是因为是第一篇,所以能做到这样很不容易。
2014_CVPR_Girshick_Rich feature hierarchies for accurate object detection and semantic segmentation
RCNN的原始文献,8100此引用。虽然早就听很多人说过,大致模型和思路都很熟悉,但是在语义分割和全景分割的文章中引用了这个,而且这篇本身还做了语义分割,所以还是拿来再看一下。
Motivation:
上个十年的目标检测方法基本上是基于SIFT和HOG特征的,但是,从2011到2012年以来,这个领域的进展就比较缓慢。
基于学习的方法现在还相对较少,但是,目图像分类问题已经相对成熟很多,研究的比较透彻。他们是基于ImageNet上进行训练的,这些方法的成功之处在于有120万的标记训练样本用于训练深度神经网络。
所以这样就引来一个问题:相比于ImageNet来说,PASCAL的数据是非常稀少的,是无法从头训练一个深层神经网络的。同时,ImageNet上神经网络的训练已经比较成熟。那么就引出了这样的想法:怎样能够将基于ImageNet的CNN的分类问题迁移到基于PASCAL的目标检测问题中。
他们使用ImageNet上的与训练模型来训练网络,然后在PASCAL上进行fineturn,发现效果比传统的基于HOG特征的检测器要好非常多。
下面是RCNN的步骤示意图:

分为四个步骤:
- 输入图像
- 提取2000个区域候选框
- 针对每个区域候选框进行warp出来,然后通过CNN来提取特征
- 然后再经过一个线性的SVM分类器进行分类。
之前还在奇怪为什么一定要每个区域单独作用,现在看了这个就非常的清楚了。因为他们的思路是基于图像分类的,实际上他们把每个region proposal都作为了一张图像来对待,然后针对这个图象来进行图像分类。这样就和他们的想法非常一致了,也很清晰地让人能够明白就应该这么做(虽然现在看来计算非常冗余,但是当时已经能够相当程度上减少计算时间)。
然后看了一下他们做语义分割,但是他们是基于一篇Semantic segmentation with second-order pooling的文章来做的,文章中基本上没介绍怎么做,貌似是一个传统方法目前还没看过,等看完之后来一起写。
2014_ECCV_Hariharan_Simultaneous Detection and Segmentation
2014年ECCV上,RCNN的同样一批人提出来的将检测与分割一起完成的一个工作,主要定义了一个SDS任务(Simultaneous Detection and Segmentation)。
没看到什么令人惊艳的点,主要是说明了这个同时检测与分割的这个任务,感觉这就是后来的instance segmentation的前身(其他的条件全部都具备了,只是没有提出instance segmentation的名词而已)。
针对这个任务,他们设计的流程共分为四步骤。
- 区域候选生成
- 特征提取
- 特征分类
- 区域边界的调整
每一个检测结果包含了一个预测出来的分割图和一个置信度,如果这个结果和GT的分割重叠的阈值在50%以上则认为正确。并依照目标检测中AP的计算指标,定义了APr这个指标,r指region,与此对应的目标检测的AP为APb,b代表bounding box。
同时考虑到了上述提到的阈值的问题,阈值设为50%是一个认为的工作,但是这个是可以进行选择的。他们认为这个和任务是相关联的,比如说在做人的counting的时候,是可以放低阈值,因为此时并不需要那么准确的位置信息,但实在有些工作中必须要非常精确的目标位置信息,这个时候阈值就应该往上调。
网络结构如下图:
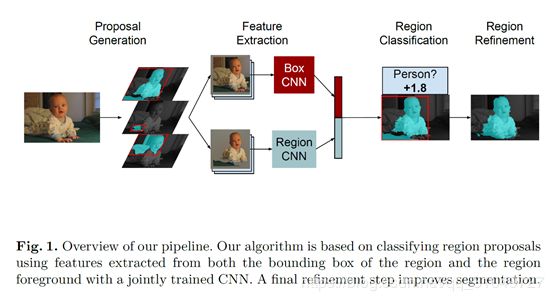
其实和RCNN的流程基本上是一致的,没有什么特别的。(他们的特征提取网络是联合优化的,但是也只是提到了一下,说两个网络在特征提取部分共享权重,但是在后面完成特定任务的网络头的时候是独立fineturn的)。
这篇文章重点还是挖了一个现在看来是instance segmentation的坑,然后定义了一些评价指标。