U-GAT-IT 论文翻译
U-GAT-IT 论文翻译
摘要:我们提出了一种新的无监督图像到图像转换方法,它以端到端的方式结合了新的注意力模块和新的可学习的归一化功能。注意模块引导我们的模型基于辅助分类器获得的关注图来关注区分源域和目标域的更重要区域。与先前基于注意力的方法[29,24]不同,这些方法无法处理域之间的几何变化,我们的模型可以翻译影像,需要大量的变化和需要大幅度变化的图像。此外,我们新的AdaLIN(自适应图层实例标准化)功能可帮助我们的注意力引导模型根据数据集通过学习参数灵活地控制形状和纹理的变化量。实验结果表明,与现有的具有固定网络架构和超参数的现有模型相比,该方法具有优越性。代码可在https://github.com/taki0112/UGATIT或https://github.com/znxlwm/UGATIT-pytorch获得。
1.简介
图像到图像转换旨在学习在两个不同域内映射图像的功能。 该主题得到了机器学习和计算机视觉领域研究人员的广泛关注,因为它具有广泛的应用,包括图像修复[32,14],超分辨率[7,17],着色[40,41]和 风格转移[9,12]。 当给出配对样本时,可以使用条件生成模型[15,22,36]或简单回归模型[20,26,40]以监督方式训练映射模型。 Inunsupervisedsettings没有配对数据,多个作品[1,6,13,18,25,33,35,39,44]使用共享潜在空间[25]和循环一致性假设[18,44]成功地翻译了图像。 这些工作已经进一步发展,以处理任务的多模态[13]。
尽管取得了这些进步,但先前的方法显示出性能差异,这取决于域之间形状和纹理的变化量。例如,它们对于映射局部纹理(例如,photo2vangogh和photo2portrait)的样式转移任务是成功的,但是对于野外图像中具有较大形状改变(例如,sel fi e2anime和cat2dog)的图像转换任务通常是不成功的。因此,通常需要诸如图像裁剪和对齐的预处理步骤来通过限制数据分布的复杂性来避免这些问题[13,25]。此外,诸如DRIT [21]之类的现有方法无法获得保留形状(例如,horse2zebra)的图像翻译所需的结果以及利用固定网络架构和超参数改变形状(例如,cat2dog)的图像翻译。需要针对特定数据集调整网络结构或超参数设置。在这项工作中,我们提出了一种新的无监督图像到图像翻译方法,它以端到端的方式结合了新的注意模块和新的可学习的标准化功能。以前的注意事项[29,24]不允许变换对象的形状,因为得将背景附加到(已翻译的)裁剪对象。与这些作品不同,我们的模型通过基于辅助分类器(CAM)获得的注意力图来区分源域和目标域,引导翻译聚焦于更重要的区域并忽略次要区域。这些注意力图嵌入到生成器和鉴别器中以聚焦于语义上重要的区域,从而促进模型变换。虽然生成器中的注意力图引起了对特定区分两个域的区域的关注,但是鉴别器中的注意力图通过关注目标域中的真实图像和伪图像之间的差异来帮助进行微调。
除了注意力机制之外,我们发现归一化函数的选择对于具有不同形状和纹理变化量的各种数据集的变换结果的质量具有显着影响。受批处理实例标准化(BIN)[31]的启发,我们提出了自适应层实例标准化(AdaLIN),通过自适应地选择实例标准化(IN)和层标准化(LN)之间的适当比率,在训练期间从数据集中学习其参数。 )。 AdaLIN功能帮助我们的注意力引导模型灵活控制形状和纹理的变化量。因此,我们的模型在不修改模型体系结构或超参数的情况下,可以执行图像转换任务,不仅需要整体更改,还需要进行大的形状更改。在实验中,所提出的方法的优越性与现有的最先进模型相比,不仅在风格转移上,而且在物体转换上。拟议工作的主要贡献可归纳如下:
1)我们提出了一种新的无监督图像到图像转换方法,它具有新的注意模块和新的归一化函数AdaLIN。
2)我们的注意模块通过基于辅助分类器获得的关注图来区分源域和目标域,从而帮助模型知道在何处进行密集转换。
3)AdaLIN功能帮助我们的注意力引导模型在不修改模型架构或超参数的情况下灵活地控制更改形状和纹理的数量。
2.相关工作
2.1 GAN
生成性对抗网络(GAN)[10]已经取得了令人印象深刻的成像,包括图像修复[2,4,16,42],图像修复[6,13,15,25,36,44]任务。 在训练中,生成器旨在生成逼真的图像以欺骗鉴别器,同时最终区分出来自图像的生成图像。 已经提出了各种多阶段生成模型[16,36]和最佳目标[2,4,28,42]来生成实际的图像。 在本报中,我们的模型使用GAN来学习从源域到显着不同的目标域的转换,给出不成对的训练数据。
2.2 图与图转换
Isolaet al[15]已经提出了基于GAN的单一框架,用于图像到图像的转换。 Wang等人提出了pix2pix的高分辨率版本。最近,已经进行了各种尝试[13,18,25,35,44]以从未配对的数据集学习图像转换。CycleGAN [44]首次提出了循环一致性损失来强制执行一对一映射。 UNIT [25]假设一个共享潜在空间来处理无监督的图像翻译。但是,只有当两个域具有相似的模式时,此方法才能很好地执行。 MUNIT [13]通过将图像分解为域不变的内容代码和捕获域特定属性的样式代码,可以扩展到多对多映射。 MUNIT合成分离的内容和样式以生成最终图像,其中通过使用自适应实例标准化来改善图像质量[12]。与MUNIaao’shT具有相同的目的,DRIT [21]将图像分解为内容和样式,因此可以进行多对多映射。唯一的区别是内容空间使用权重共享和内容鉴别器在辅助分类器之间共享。然而,这些方法[13,25,21]的性能仅限于包含源和目标域之间的井对齐图像的数据集。
2.3类激活图
周教授等人 [43]已经提出了使用CNN中的全局平均池的类激活图(CAM)。特定类的CAM通过CNN显示判别图像区域以确定该类。 在这项工作中,我们的模型导致通过使用CAM方法区分两个域提供的集中改变判别图像区域。 但是,不仅使用全局平均池化层,而且还使用全局最大池化来使结果更好。
2.4正则化
最近的神经样式转移研究表明,CNN特征统计(例如,Gram矩阵[9],均值和方差[12])可以用作图像样式的直接描述符。特别地,实例标准化(IN)具有通过直接标准化图像的特征统计来消除样式变化的效果,并且在样式转移中比批量标准化(BN)或层标准化(LN)更频繁地使用。 但是,在对图像进行标准化时,最近的研究使用自适应实例标准化(AdaIN)[12],条件实例标准化(CIN)[8]和批处理实例标准化(BIN)[31],而不是单独使用IN。 在我们的工作中,我们提出了自适应层实例标准化(AdaLIN)功能,以自适应地选择IN和LN之间的适当比例。通过AdaLIN,我们的注意力引导模型可以灵活地控制形状和纹理的变化量。
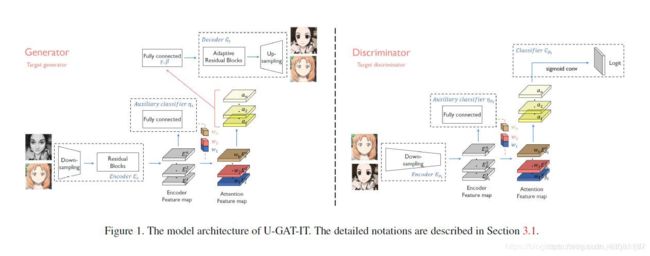
我们的目标是训练函数Gs→t,其仅使用从每个域绘制的未配对样本将图像从源域Xs映射到目标域Xt。 我们的框架由两个发生器Gs t和Gt ts以及两个鉴别器Ds和Dt组成。 我们将注意模块集成到发生器和鉴别器中。 鉴别器中的注意模块引导发生器聚焦于对生成逼真图像至关重要的区域。 生成器中的注意模块关注区域与其他域的区别。 在这里,我们只解释Gs→t和Dt(见图1),反之亦然,应该是直截了当的。
3.1model
3.1.1生成器
令x∈{Xs,Xt}表示来自源域和目标域的样本。我们的翻译模型Gs→t由编码器Es,解码器Gt和辅助分类器ηs组成,其中ηs(x)表示x来自Xs的概率。令Ek s(x)为编码器的第k个激活图,并且Ekij s(x)为(i,j)处的值。受CAM [43]的启发,辅助分类器通过使用全局平均合并和全局最大合并,即ηs(x)=σ(ΣkwksΣijEkij)进行训练,以学习第k个特征图的重要性权重wks。s(x)。通过利用重要性权重,我们可以计算一组域特定的注意特征图,如(x)= ws * Es(x)= {wk sEk s(x)|1≤k≤n},其中n是数字编码的特征映射。然后,我们的翻译模型Gs→t变为等于Gt(as(x))。受近期工作的启发,转换参数非标准化层沙结合归一化函数[12,31],我们将残差块与AdaLIN装配在一起,这些参数通过动态连接层从距离图中动态计算。

其中μI,μL和σI,σL分别为通道,分层和标准差,γ和β是由连接层生成的参数,τ是学习率Δρ表示由优化器确定的参数更新矢量(例如,梯度)。仅仅通过在参数更新步骤中施加界限,将值限制在[0,1]的范围内。生成器调整该值,以便在LN重要的任务中,实例标准化很重要,并且ρ的值接近0。 ρ的值在解码器的残余块中初始化为1,在解码器的上采样块中初始化为0。将内容特征转移到样式特征sistoapply白化和着色变换(WCT)[23]的最佳方法,但由于协方差矩阵和矩阵逆的计算,计算成本很高。尽管AdaIN [12]比WCT快得多,但它对WCT来说是次优的,因为它假定了特征通道之间的不相关。因此,转移的特征包含了更多内容。另一方面,LN [3]不会在通道之间进行相关关系,但有时它不能很好地保持原始域的内容结构,因为它只考虑了特征映射的全局统计。为了克服这个问题,我们提出的归一化技术AdaLIN通过选择性地保留或更改内容信息,结合了AdaIN和LN的优点,这有助于解决各种图像到图像的转换问题。
3.1.2 判别器
令x∈{Xt,Gs→t(Xs)}表示来自目标域和翻译的源域的样本。 与其他转换模型类似,鉴别器Dt由编码器EDt,分类器CDt和辅助分类器ηDt组成。 与其他翻译模型不同,现在训练ηDt(x)和Dt(x)来区分x是来自Xt还是Gs→t(Xs)。 给定样本x,Dt(x)利用由ηDt(x)训练的编码特征图EDt(x)上的重要性权重wDt来利用注意特征图aDt(x)= wDt * EDt(x)。 然后,我们的鉴别器Dt(x)变得等于CDt(aDt(x))。
3.2 损失函数
我们模型的完整目标包括四个损失函数。 在这里,我们使用最小二乘GAN [27]目标来进行稳定训练,而不是使用香草GAN目标。 对抗性损失使用对抗性损失来匹配翻译图像与目标图像分布的分布:

循环损失为了缓解模式崩溃问题,我们对发电机应用循环一致性约束。 给定图像x∈Xs,在从Xs到Xt以及从Xt到Xs的后续转换后,图像应该成功转换回原始域:
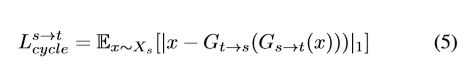
身份丢失为了确保输入图像和输出图像的颜色分布相似,我们将身份一致性约束应用于生成器。 给定图像x∈Xt,在使用Gs→t平移x之后,图像不应该改变。

CAM损失通过利用辅助类i信息ηs和ηDt中的信息,给定图像x∈{Xs,Xt}。 Gs→t和Dt知道他们需要改进的地方或者当前状态下两个域之间的差异最大的是:

完全体目标 最后,我们联合训练编码器,解码器,鉴别器和辅助分类器,以优化最终目标:


4.实现
4.1网络结构
发生器的编码器由两个卷积层组成,其中步幅大小为2,用于下采样和四个残余块。生成器的解码器由四个残余块和两个上采样卷积层组成,步长大小为1。请注意,我们分别使用编码器的实例规范化和解码器的AdaLIN。通常,LN在分类问题中的表现不如批量标准化[37]。由于辅助分类器是从发生器中的编码器连接的,为了提高辅助分类器的准确性,我们使用实例归一化(批量归一化,小批量大小为1)而不是AdaLIN。频谱归一化[30]用于鉴别器。我们为鉴别器网络使用两种不同的PatchGAN [15],它分类是本地(70 x 70)和全局(286 x 286)图像补丁是真实的还是假的。对于激活功能,我们在发生器中使用ReLU,在鉴别器中使用泄漏-ReLU,斜率为0.2。
4.2训练
使用Adam [19]训练所有模型,其中β1= 0.5且β2= 0.999。 对于数据增强,我们将图像水平地融合到0.5的可能性,将其重新调整为286x 286,并随机剪切到256x256。 对于所有实验,Thebatchsize设置为1。 我们训练所有模型的固定学习率为0.0001,直到500,000次迭代,并线性衰减到1,000,000次迭代。 我们还使用0.0001的重量衰减。 权重从零中心正态分布初始化,标准偏差为0.02。
5.实验
5.1基准模型
我们将我们的方法与各种模型进行了比较,包括Cycle GAN [44],UNIT [25],MUNIT [13]和DRIT [21]。所有的baseline方法都是使用作者的代码实现的。 CycleGAN使用对抗性损失来学习两个不同域X和Y之间的映射。该方法通过循环一致性损失来规范映射。它使用两个下采样卷积块,九个残余块,两个采样反卷积块和四个鉴别器层。 UNIT由两个具有共享潜在空间的VAE-GAN组成。 UNIT的结构类似于CycleGAN,但UNIT与CycleGAN的不同之处在于它使用多尺度鉴别器并共享编码器和解码器的高级层级的权重。 MUNIT可以为单个输入图像生成各种输出。 MUNIT假设图像表示可以分解为内容代码和样式代码。 MUNIT的网络结构与其他网络的区别在于MUNIT在解码器中使用AdaIN和多尺度鉴别器。 DRIT是与无监督的图像到图像转换相关的最新工作。 DRIT还可以为单个输入图像生成各种输出,如MUNIT。与MUNIT类似,它将图像分解为内容代码和样式代码,并使用多尺度鉴别器。区别在于内容代码像UNIT一样共享。
5.2 数据集
我们已经用五个不成对的图像数据集评估了每种方法的性能,包括四个代表性图像翻译数据集和一个由真实照片和动画作品组成的新创建的数据集,即自定义图像数据集。所有图像都调整为256 x 256进行训练。
selfie2anime自定义数据集包含46,836个用36种不同属性注释的自定义图像。但是,我们只使用女性照片作为训练数据和测试数据。训练数据集的大小为3400,测试数据集的大小为100,图像大小为256 x 256.对于动画数据集,我们首先从Anime-Planet1中检索到69,926个动画角色图像。在这些图像中,通过使用animefacedetector2提取27,023个面部图像。我们已经收集了两个女性动漫人脸图像的数据集,其中大小分别为3400和100,并且分别是与自然数据集相同的数字,我们已经收集了两个手动删除单色图像的数据集。

通过应用基于CNN的图像超分辨率算法3将动画人脸图像的大小调整为256×256。
horse2zebra和photo2vangogh这些数据集用于Cycle GAN [44]。 每个班级的训练数据集大小:1,067(马),1,334(斑马),6,287(照片)和400(vangogh)。测试数据集包括120(马),140(斑马),751(照片)和400(vangogh)。请注意,vangogh类的训练数据和测试数据是相同的。cat2dog和photo2portrait这些数据集用于DRIT [21]。 foreachclass的数据数量为871(猫),1,364(斑马),6,452(照片)和1,811(vangogh)。 我们分别使用120(马),140(斑马),751(照片)和400(vangogh)随机选择的图像作为测试数据。
5.3 实验结果
我们首先分析了注意模块和AdaLIN在所提出的模型中的影响。 然后,我们将模型的性能与上一节中列出的其他无监督图像转换模型进行比较。 为了评估翻译图像的视觉质量,我们进行了用户研究。 要求用户在从五种不同方法生成的图像中选择最佳图像。 我们模型的结果的更多示例包含在补充材料中。

5.3.1采用CAM 后的相关分析
首先,我们进行消融研究,以确定生成器和辨别器中使用的注意模块的好处。如图2(b)所示,关注特征图帮助生成器聚焦于与目标域(suchaseyesandmouth)更具辨别力的源图像区域。同时,我们可以分别通过可视化鉴别器的局部和全局注意力图来看到鉴别器集中注意力的区域以确定目标图像是真实的还是伪造的,如图2(c)和(d)所示。发生器可以用这些注意力图调整鉴别器所关注的区域。请注意,我们结合了两个具有不同接收场大小的鉴别器的全局和局部注意力图。这些地图可以帮助发生器捕获全球结构(例如,面部区域和近处眼睛)作为周围区域。
有了这些信息,一些区域的解析会更加谨慎。利用图2(e)所示的关注模块的结果验证了在图像翻译任务中利用关注特征图的有利效果。另一方面,可以看到眼睛未对准,或者在没有使用注意模块的情况下根本没有完成平移,如图2(f)所示。其他数据集的注意图如图3所示。
5.3.2 AdaLIN 结构使用分析

如第4.1节所述,我们仅将AdaLIN应用于生成器的解码器。残差块在解码器中的作用是嵌入特征,并且上采样卷积块在解码器中的作用是从嵌入特征生成目标域图像。如果门参数ρ的学习值更接近1,则意味着相应的层更多地依赖于IN而不是LN。同样,如果ρ的学习值更接近于0,则意味着相应的层更多地依赖于LN而不是IN。如图4(c)所示,在解码器中仅使用IN的情况下,源域的特征(例如,耳环和颧骨周围的阴影)在残余块中使用得很好地保留了二十三通道 - 一般规范化特征统计。但是,目标域样式的转换量有些不足,因为上采样卷积块的IN不能捕获全局样式。另一方面,如图4(d)所示,如果我们在解码器中仅使用LN,则可以通过在上采样卷积中使用的分层归一化特征统计来充分地转移目标域样式。但是通过在残差块中使用LN,源域图像的特征保留较少。对两个极端情况的分析告诉我们,在特征表示层中依靠IN而不是LN来保持源域的语义特征是有益的,而对于实际从特征嵌入生成图像的上采样层则相反。

在调整图像资源和目标分配中调整IN和LN的比率的AdaLIN更适用于在图像到图像的翻译任务中。 另外,图4(e),(f)分别是使用AdaIN和组标准化(GN)[38]的结果,并且我们的方法显示出与这些相比更好的结果。 此外,如表1所示,我们通过使用核启动距离(KID)[5]的消融研究,证明了注意模块和AdaLIN在自我数据集中的性能。 我们的模型实现了最低的KID值。 即使注意模块和AdaLIN是分开使用的,我们也可以认为模型比其他模型要好。 但是,当一起使用时,性能甚至更好。 如图5所示,ρ的学习值根据数据集而变化。 此外,对于像photo2vangogh,photo2portrait这样的风格转移任务,INI已知表现良好。 TheAdaLINcanals假设ρ值接近1。
5.3.3 定性评估
对于定性评估,我们还进行了感知研究。135个参与者显示来自不同方法方法的翻译结果,包括提出的源图像方法,并要求选择最佳翻译图像到目标域。我们只向参与者通知目标域名,即动画,狗和斑马。但是,为肖像和VanGogh数据集提供了目标域的一些示例图像作为最小信息以确保适当的判断。表2显示,与其他方法相比,所提出的方法可以显着提高对photo2vangogh的影响,但在人类知觉研究中具有可比性。在图6和图7中,我们呈现了教学方法中用于性能比较的图像翻译。 U-GAT-ITcan通过利用注意力模块,更多地关注源域和目标域之间的不同区域,从而生成图像。请注意,在CycleGAN的结果中,两只斑马头或狗眼周围的区域会扭曲。此外,使用U-GAT-IT的翻译结果在视觉上优于其他方法,同时保留了源域的语义特征,如图6和7的第四行所示。值得注意的是,MUNIT和DRIT的结果是由于具有随机样式代码的生成图像的多样性而产生的模拟图像。此外,应该强调的是,U-GAT-IT已经为所有五个不同的数据集应用了相同的网络架构和超参数,而其他算法则使用预设网络或超参数进行训练。通过用户研究的结果,我们表明我们的注意模块和AdaLIN的组合使我们的模型数据不可知。


6.结论
在本文中,我们提出了无监督的图像到图像转换(U-GAT-IT),其中注意模块和AdaLIN可以在具有定制网络架构和超参数的各种数据集中产生更加视觉上令人愉悦的结果。 对各种实验结果的详细分析支持了我们的假设,即由辅助分类器获得的关注图可以指导生成器更多地关注源域和目标域之间的不同区域。 此外,我们发现AdaptiveLayer-InstanceNormalization(AdaLIN)对于翻译包含不同数量的几何和样式更改的各种数据集非常重要。 通过实验,我们已经表明,与现有的基于GAN的无监督图像到图像转换任务的模型相比,所提出的方法的优越性。
正文到此翻译完毕。参考条目即附录的成品效果图请阅读论文原文。