kaggle泰坦尼克数据——stacking
前言
网上有很多关于泰坦尼克数据的描述、如何数据清洗以及特征工程,这里不再赘述。处理代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import Imputer,LabelBinarizer,LabelEncoder,StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score,GridSearchCV
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier,AdaBoostClassifier,BaggingClassifier,ExtraTreesClassifier,GradientBoostingClassifier
from sklearn.model_selection import cross_val_score, KFold
from xgboost import XGBClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
'''
加载数据
'''
data_train_raw = pd.read_csv('train.csv')
data_test = pd.read_csv('test.csv')
data_train = data_train_raw.copy(deep=True)
#查看数据
'''
data_train数据构成
891*12:
PassengerId:乘客Id,int
Survived:是否幸存,int,标记,0最多
Pclass:乘客等级,int,3等级最多
Name:乘客名字,文本
Sex:性别,文本
Age:年龄,float,有空缺,714个,mean=29.69,min=0.42,max=80,集中在38以下
Sibsp;兄弟姐妹个数,int,min=0,max=8,0最多
Parch:父母小孩个数,int,min=0,max=6,0最多
Ticket:票号,文本+数值
Fare:票价,float,mean=32.2,min=0,max=512.32,集中在31以下
Cabin:客舱,文本+数值,有空缺,204个
Embarked:登船港口,文本,有空缺,889个,S港明显高于其他
'''
#print(data_train_raw.head(5))
#print(data_train_raw.info())
#print(data_train_raw.describe(include='all'))
'''
data_test数据构成
418*11
无标记Survived
Fare,Age,Cabin有缺失,Cabin缺失严重
'''
#print(data_test.info())
#清洗数据
'''
对Age、Fare、Embarked进行中位数填充
去掉PassengerId,Ticket,Cabin
'''
dataset_cleaner = [data_train,data_test]
for dataset in dataset_cleaner:
dataset['Age'].fillna(dataset['Age'].median(),inplace=True)
dataset['Embarked'].fillna(dataset['Embarked'].mode()[0],inplace=True)
med = dataset['Fare'].median()
dataset['Fare'].fillna(med,inplace=True)
#对过高的Fare进行中值替换
dataset['Fare'].apply(lambda x:med if x>=300 else x)
columns_drop = ['PassengerId','Ticket','Cabin']
dataset.drop(columns_drop,axis=1 ,inplace=True)
#print(data_train.isnull().sum())
#print(data_test.isnull().sum())
#特征工程
for dataset in dataset_cleaner:
#年龄按值分元
dataset['Agebin'] = pd.cut(dataset['Age'],5)
#对Fare按频率分元
dataset['Farebin']=pd.qcut(dataset['Fare'],4)
#获取name中的title
dataset['Title'] = dataset['Name'].apply(lambda x: x.split('.')[0].split(',')[1].strip())
#对次数少的title进行合并
name_count = dataset['Title'].value_counts()<10
dataset['Title'] = dataset['Title'].apply(lambda x:'Misc' if name_count.loc[x]==True else x)
#家族大小
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
dataset['IsAlone'] = 1
dataset.IsAlone[dataset.FamilySize>1] = 0
columns_drop = ['Name','Age','Fare','SibSp','Parch']
dataset.drop(columns_drop,axis=1,inplace=True)
#文本数值化
for dataset in dataset_cleaner:
label = LabelEncoder()
dataset['Sex_code'] = label.fit_transform(dataset['Sex'])
dataset['Agebin_code'] = label.fit_transform(dataset['Agebin'])
dataset['Farebin_code'] = label.fit_transform(dataset['Farebin'])
dataset['Title_code'] = label.fit_transform(dataset['Title'])
dataset['Embarked_code'] = label.fit_transform(dataset['Embarked'])
columns_drop = ['Sex','Agebin','Farebin','Title','Embarked']
dataset.drop(columns_drop,axis=1,inplace=True)处理后的结果如下:

我们看看几个算法的表现:
#提取标记
train_y = np.array(data_train['Survived'])
train_x = np.array(data_train.drop('Survived',axis=1))
rf = RandomForestClassifier()
et = ExtraTreesClassifier()
gb = GradientBoostingClassifier()
MLA = [rf,et,gb]
for mla in MLA:
mla.fit(train_x,train_y)
accuracy = cross_val_score(mla,train_x,train_y,cv=5)
accuracy_mean = np.mean(accuracy)
print('mla:',mla.__class__.__name__,'accuracy_mean:',accuracy_mean)结果:

这里使用默认的参数,精度大约都在0.81左右。
下面介绍本文重点:stacking
过程图如下:
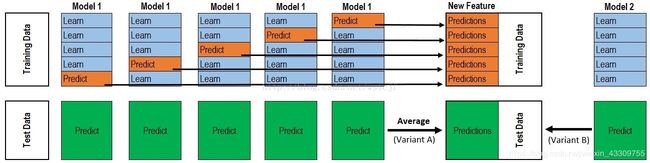
第一次看见是懵逼,我用人话来解释一下:
假设我们的train集大小为1000(train_x=1000,train_y=1000),test集大小为100(test_x=100,test_y=100对我们来说是未知的)。把train集进行KFold,这里假设为5(就是把数据集分成5份),我们每次用其中四份作为base_model1的训练集(base_model.fit(4*批训练集),用产生的模型base_model1对剩下的一份进行预测,预测结果为base_model_predict(大小200);同时也对完整的test集预测,结果为test_predict(大小100)。所以一次下来会产生5*base_model_predict,拼接成train(1000)和5*test_predict(500)。然后对5份test_predcict求平均(大小变为100)。这样一个base_model1会产生大小1000的train2和大小100的test2。如果有三个这样的base_model,就会产生3*train2的数据集,大小为3*1000和3*test2大小为3*100,将它们作为第二层的数据。
假如第二层只有一个模型model,使用第二层的数据进行拟合(model.fit(3*train2,train_y)),再进行预测(model.predcit(3*test2))
是不是有点乱,好好捋一捋。
代码如下:
#提取标记
data_labels = np.array(data_train['Survived'])
data_train = np.array(data_train.drop('Survived',axis=1))
#stacking集成
#第一层
#5折
kf = KFold(n_splits = 5, random_state=42, shuffle=False)
def get_out_fold(clf, x_train, y_train, x_test):
base_model_pre = np.zeros((np.shape(x_train)[0]))
test2 = np.zeros((5,np.shape(x_test)[0]))
for i, (train_index, test_index) in enumerate(kf.split(x_train)):
x_tr,x_te = x_train[train_index],x_train[test_index]
y_tr,y_te = data_labels[train_index],data_labels[test_index]
clf.fit(x_tr, y_tr)
base_model_pre[test_index] = clf.predict(x_te)
test2[i,:] = clf.predict(x_test)
test2 = test2.mean(axis=0)
return base_model_pre.reshape(-1,1),test2.reshape(-1,1)
#三个基学习器
rf = RandomForestClassifier()
et = ExtraTreesClassifier()
gb = GradientBoostingClassifier()
base_rf_train,rf_test2 = get_out_fold(rf, data_train, data_labels, data_test)
base_et_train,et_test2 = get_out_fold(et, data_train, data_labels, data_test)
base_gb_train,gb_test2 = get_out_fold(gb, data_train, data_labels, data_test)
#第二层
#进行拼接
train2 = np.c_[base_rf_train,base_et_train,base_gb_train]
test2 = np.c_[rf_test2,et_test2,gb_test2]
#第二层学习器
gbm = XGBClassifier( n_estimators= 2000, max_depth= 4,
min_child_weight= 2, gamma=0.9,
subsample=0.8, colsample_bytree=0.8).fit(train2,data_labels)
predictions = gbm.predict(test2)
#呈递结果
gender = pd.read_csv('gender_submission.csv')
gender['Survived'] = predictions
gender.to_csv('stacking.csv',index=False)在测试集结果大概在0.79.