地震数据爬取——Scrapy爬虫框架应用
文章目录
- 一、前言
- 二、Scrapy框架爬取微博
- 三、数据清洗
- 四、数据展示
- 1.地震次数
- (1)省级维度
- (2)市级维度
- (3)县、区维度
- 2.震级分布
- (1)省级维度
- (2)市级维度
- (3)县、区维度
- 3.时间分布
一、前言
近日四川省宜宾市长宁县发生6.0级地震,周边地区震感强烈。天灾无情人有情,一方有难八方援。四川人民在面对自然灾害时表现出了坚强。
地震成因是地震学科中的一个重大课题。目前有如大陆漂移学说、海底扩张学说等。现在比较流行的是大家普遍认同的板块构造学说。板块与板块的交界处,是地壳活动比较活跃的地带,也是火山、地震较为集中的地带。那么我们国家地震的多发区域是哪些地方呢?笔者爬取了"中国地震台网速报"微博的内容,做了简单的分析。
二、Scrapy框架爬取微博
众所周知,Scrapy项目的结构是这样的
本次爬虫主要是从"中国地震台网速报"这个微博爬取,爬取内容只涉及时间和微博内容,所以items.py如下
import scrapy
class WeiboItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
time = scrapy.Field()
txt = scrapy.Field()
为了方便,爬取目标网址选取了微博的手机网页版,即m.weibo.com。微博手机版向下翻页是Ajax请求,返回的结果是json文件。spider如下
import scrapy
import json
from weibo.items import WeiboItem
class EarthquakeSpider(scrapy.Spider):
name = 'earthquake'
allowed_domains = ['m.weibo.cn']
start_urls = [
'https://m.weibo.cn/api/container/getIndex?uid=1904228041&luicode=10000011&lfid=100103type%3D3%26q%3D%E5%9C%B0%E9%9C%87%E9%80%9F%E6%8A%A5%26t%3D0&type=uid&value=1904228041&containerid=1076031904228041&page=' +
str(i) for i in range(1, 2039)
]
def parse(self, response):
js = json.loads(response.text)
weibo_items = js.get('data').get('cards')
for weibo_item in weibo_items:
item = WeiboItem()
item['time'] = weibo_item.get('mblog').get('created_at')
item['txt'] = weibo_item.get('mblog').get('text')
yield item
爬取结果存储在MongoDB数据库中,所以pipelines.py如下
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db, mongo_col):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
self.mongo_col = mongo_col
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB'),
mongo_col=crawler.settings.get('MONGO_COL')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
self.col = self.db[self.mongo_col]
def process_item(self, item, spider):
self.col.insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()
全局配置settings.py文件中,有关MongoDB的设置如下
ITEM_PIPELINES = {
'weibo.pipelines.MongoPipeline': 300,
}
MONGO_URI = 'localhost'
MONGO_DB = 'weibo'
MONGO_COL = '中国地震台网速报'
本次爬虫并未设置代理、未伪造浏览器头等等,数据清洗也是单独进行的。
三、数据清洗
清洗过程省略。。。
最终获得了自2012年4月自今共6847条地震数据。
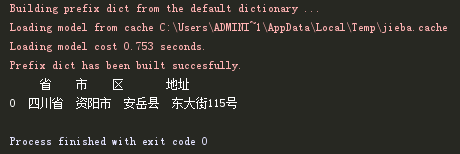
由于震源位置是类似于"四川资阳市安岳县"的字符串,需要将其拆分为省、市、县三级。Python最出名的就是库很全,所以这里给大家推荐一个库——cpca,可以很轻松的拆分地址。具体用法很简单
import cpca
lst = ['四川资阳市安岳县东大街115号']
df = cpca.transform(lst) # lst必须为list
返回结果如下
四、数据展示
1.地震次数
(1)省级维度

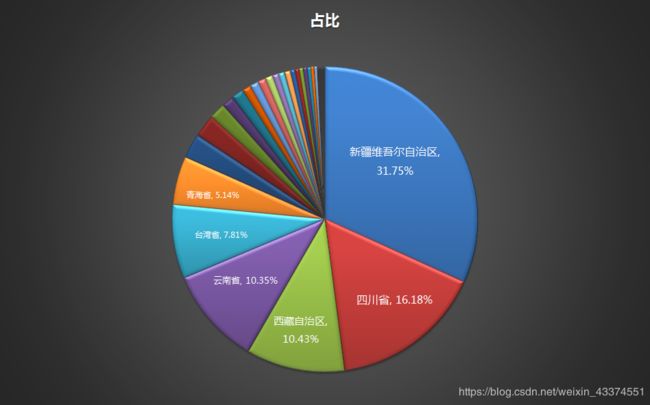
从数据可以看到近7年来国内地震的主要分布,比较集中的前6个省份占比80%以上。新疆排在第一,是因为新疆面积较大,且处于印度板块和欧亚板块碰撞的前沿地带。新疆有五大地震带,由北向难分别是阿尔泰地震带、北天山地震带、南天山地震带、西昆仑山地震带和阿尔金山地震带。四川排在第二,主要是因为四川位于龙门山地震带上,所以地震较多。
(2)市级维度


排名前40的市中,四川有雅安市、宜宾市、绵阳市、广元市、内江市和成都市,应该多普及地震避险知识。
(3)县、区维度
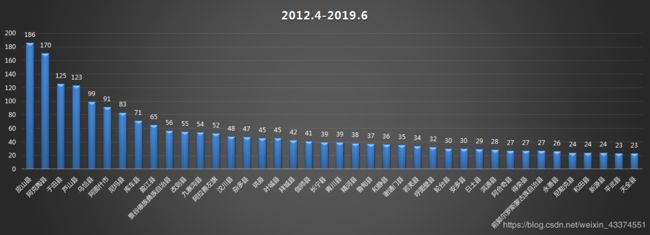
2.震级分布
根据震级我们有如下划分
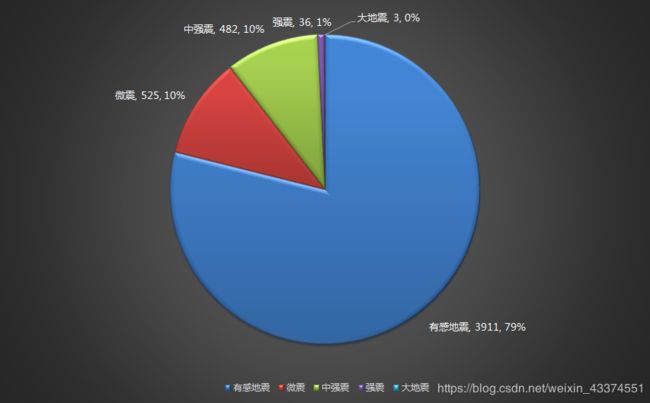
近7年主要还是3-4.5级的有感地震,其次是4.5-6级的中强震,再次是6-7级的强震。
(1)省级维度

6级强震以上有以下几个省份

(2)市级维度

6级强震以上有以下几个市
(3)县、区维度

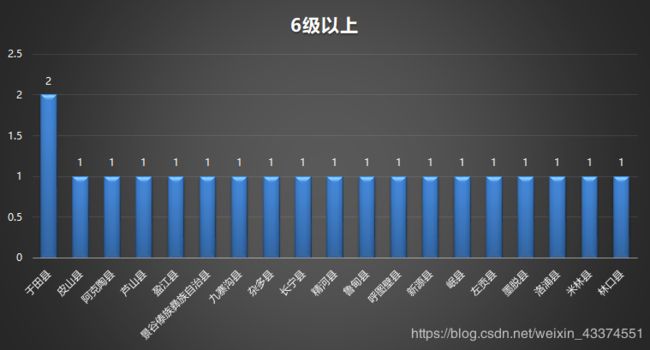
6级强震以上有以下几个县
3.时间分布
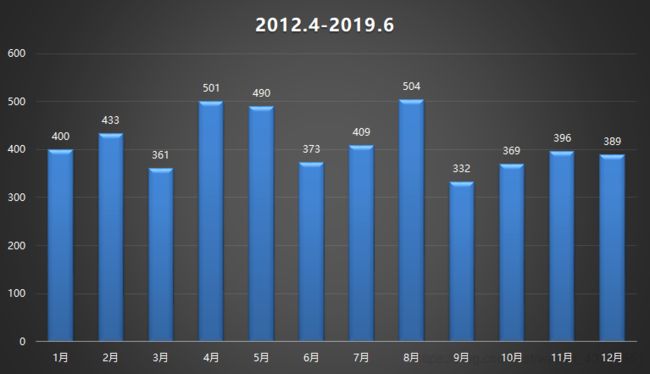
从时间上来看,4、5、8月略微地震次数多一些,但实际上并没有太大的差别。
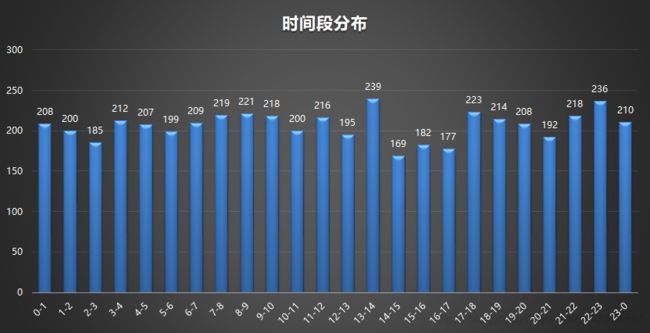
从时间段来看,下午比较少,其实也没太大区别。
最后说一下,遇到地震千万不要惊慌,平房、低层的人应充分利用时间,头顶枕头、沙发靠垫或安全帽等能保护头部的物品,跑至屋外空旷宽敞地;高层楼房内的人,要迅速远离外墙、门窗和阳台,选择厨房、卫生间、楼梯间等开间小而不易倒塌的空间避震。千万不要乘坐电梯,不要盲目跳楼!