python 爬取裁判文书网
19年4月版完整代码github地址:https://github.com/Monster2848/caipanwenshu
目标网站
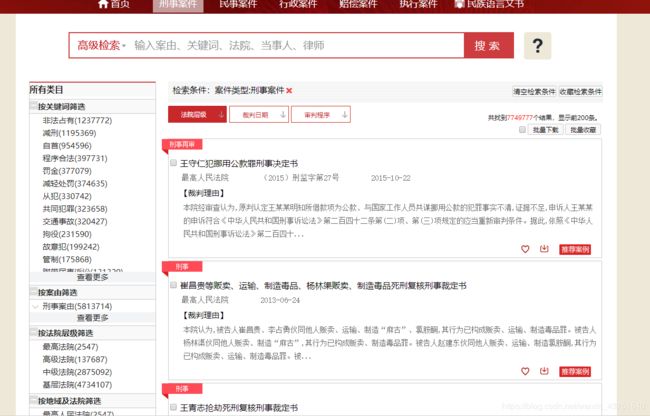
发现这个请求中有返回数据

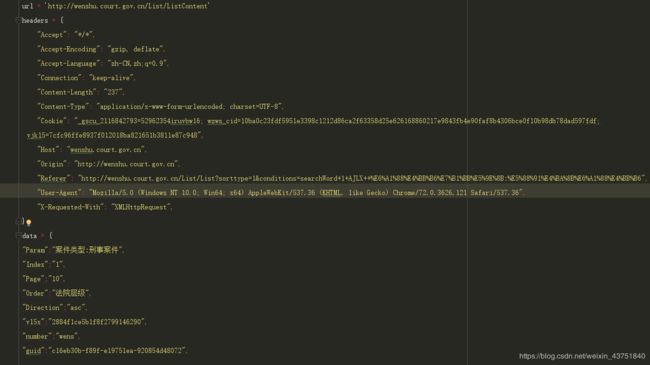
先带齐所有参数模拟浏览器发起一次请求
![]()
拿到了数据
测试一下发现header可以缩减一点,但是cookie一定要传

这里的vl5x 和guid应该是个加密参数,找一下出处
搜索一下

打个断点调试一下

发现函数本体

取出来第一段eval,在console里运行一下,把里面需要的_fxxx和de函数也贴过来一起

解完一层之后里面还有一层

贴出来,删掉eval继续

格式化一下
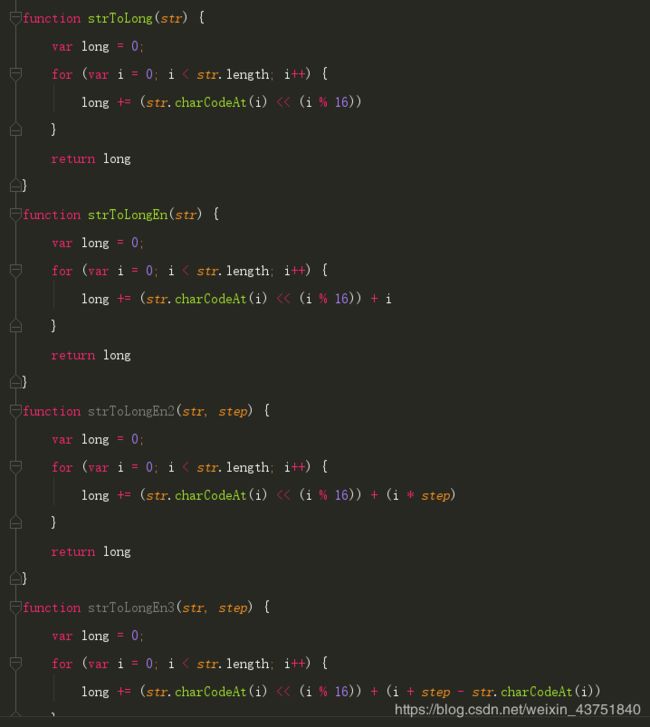
下面几个用同样的方法得到

最后一个eval

把js文件用js2py运行,发现少getCookie,在文件里找到getCookie
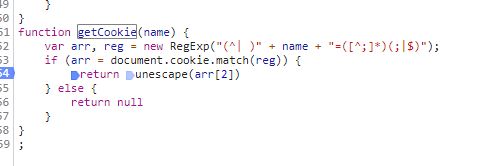
这个本质上是从cookie里获取一个键为‘vjkl5’的字符串然后正则匹配
研究了一下感觉cookie不好找,给函数传个定值,测试下别的
==========================================================
继续运行
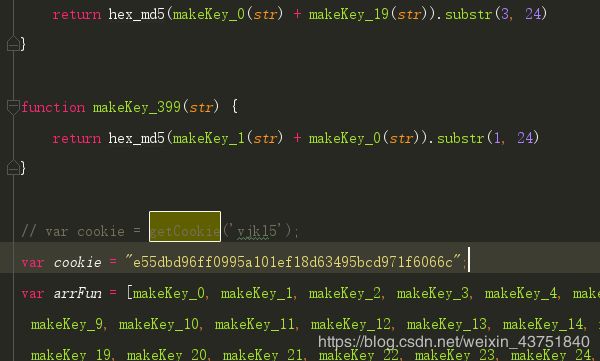
发现少hex_md5,

继续回去找
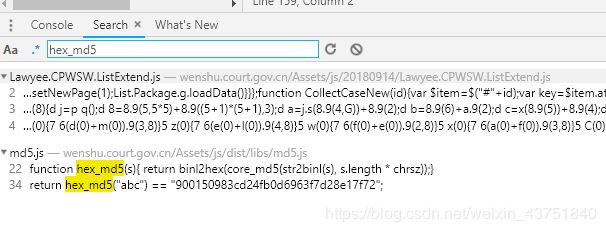
贴过来

继续
然后少Base64
![]()
感觉这样一个个找太慢了,研究下路径,把这几个加密文件都复制过来

![]()
不报错了,cookie先放一下
![]()
接下来是guid
首先找到函数

格式化一下,发现可以直接拿来用


执行一下拿到guid
![]()
接下来开始找cookie
cookie肯定是设置进去的,把浏览器的cookie清掉,再次请求试试
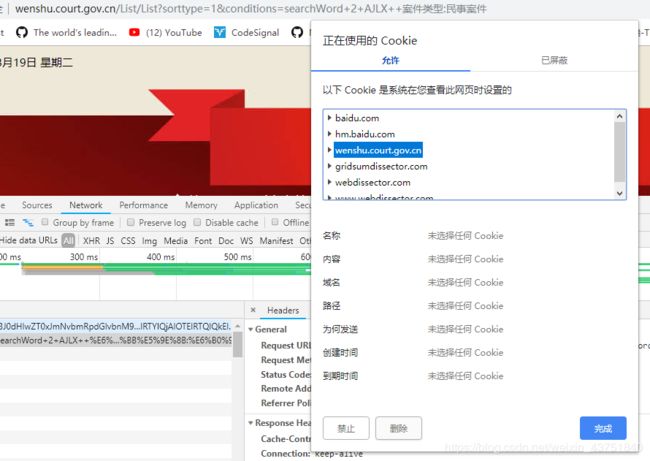
发现了这个vjkl5是在这里设置的

但是需要这个wzws_cid
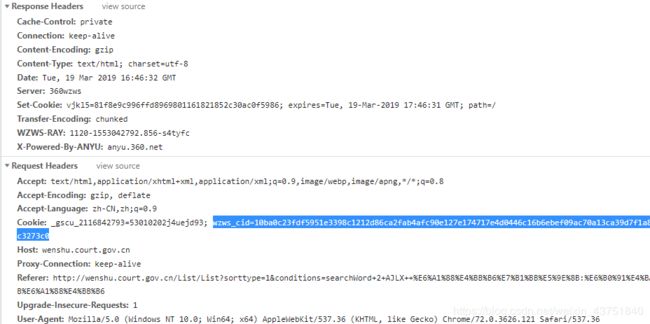
发现是在首页的这个WZWSRELw==请求中设置的
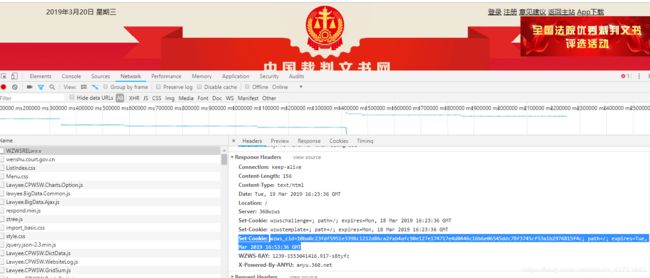
发起这个请求需要带上cookie,需要参数wzws_cid(原始的),wzwstemplate,wzwschallenge
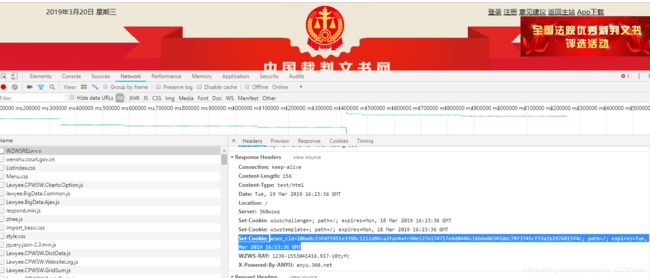
不带参数对主页发起请求

得到一串js代码,格式化一下

发现cookie的参数就是从这里生成的
然后多请求两次发现,第二,三的参数每次不一样

这样的话就不能手动解包,想办法在代码中解包,拿到这个参数
先写个思路测试下

p是最后的返回值,先定义一个变量aaa,把p的值传给aaa,在执行完之后就能拿到返回的值,这里的return后面要加个字符串,不然会报错
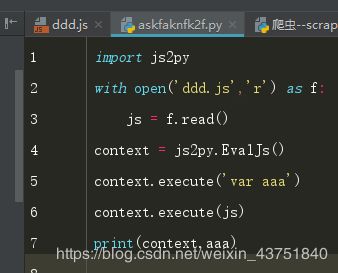
获得了正常函数
![]()
写到代码里

执行一下刚刚获得的函数,拿到新cookie的参数

带上cookie请求http://wenshu.court.gov.cn//WZWSRELw==获得新的wzws_cid

再进行若干请求后,获得列表数据,处理一下

===================================================================
开始爬详情页
详情页主要是带上之前的cookie请求http://wenshu.court.gov.cn/WZWSREL2NvbnRlbnQvY29udGVudD9Eb2NJRD0xM2Q0YzAxYS0wNzM0LTRlYzEtYmJhYy02NThmOGJiOGVjNjImS2V5V29yZD0= 获得一个新的wzws_cid,并且在响应头中可以获得DocID

带上这两个参数去请求http://wenshu.court.gov.cn/CreateContentJS/CreateContentJS.aspx?DocID=13d4c01a-0734-4ec1-bbac-658f8bb8ec62 就可以获得数据
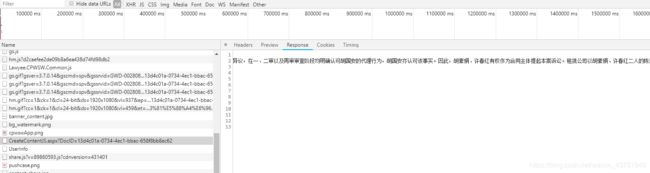
返回的数据是一段js代码
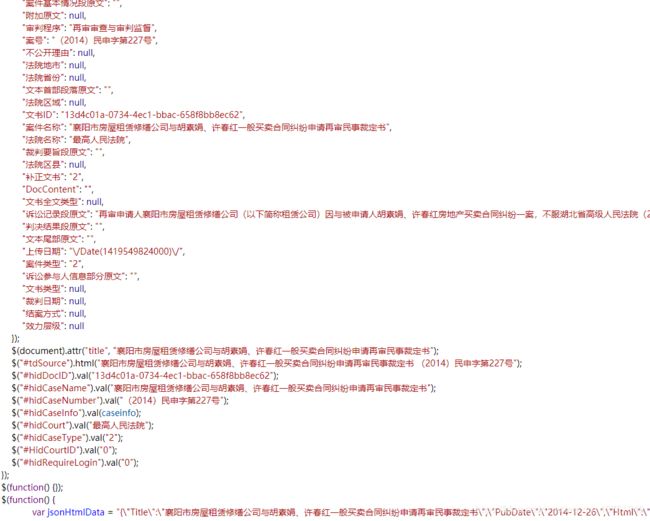
对数据进行提取
标题信息

内容信息

代码如下:
import json
import re
from pprint import pprint
import js2py
import requests
import time
from bs4 import BeautifulSoup
# 请求首页,获得第一个wzws_cid
resp = requests.get(
url="http://wenshu.court.gov.cn/",
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
},
# proxies=proxies
)
print(resp.cookies)
wzws_cid = requests.utils.dict_from_cookiejar(resp.cookies)["wzws_cid"]
# print("wzws_cid:",wzws_cid)
# 抓取响应中的js代码
raw_func = re.findall(r'',resp.text,re.DOTALL)[0]
# print(raw_func)
sub_text = '''aaa=p;return "'zifuchuan'"'''
courl_func = re.sub('return p',sub_text,raw_func) # 把原文中的return p 替换
# print(courl_func)
context = js2py.EvalJs()
context.execute('var aaa') # 定义个变量获取函数的返回值
context.execute(courl_func) # 执行替换好的函数
unpacked_cofunc = context.aaa # 拿到函数
# print(context.aaa)
code = re.findall(r'(.*)function HXXTTKKLLPPP5',context.aaa)[0]
# print(code)
context.execute(code)
js = '''
var cookieString = "";
var wzwstemplate_result = KTKY2RBD9NHPBCIHV9ZMEQQDARSLVFDU(template.toString());
console.log(cookieString)
var confirm = QWERTASDFGXYSF();
var wzwschallenge_result = KTKY2RBD9NHPBCIHV9ZMEQQDARSLVFDU(confirm.toString());
console.log(cookieString)
console.log(dynamicurl)
'''
context.execute(js)
new_cookies = {
"wzws_cid":wzws_cid,
"wzwstemplate":context.wzwstemplate_result,
"wzwschallenge":context.wzwschallenge_result
}
# print("new_cookies:",new_cookies)
new_url = "http://wenshu.court.gov.cn" + context.dynamicurl
# print("new_url:",new_url)
resp = requests.get(
url=new_url,
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
"Referer":"http://wenshu.court.gov.cn/"
},
cookies=new_cookies,
allow_redirects=False,
# proxies=proxies
)
wzws_cid = requests.utils.dict_from_cookiejar(resp.cookies)["wzws_cid"] #获得了新的cid
# print("wzws_cid 计算后的:",wzws_cid)
# 带着新的cid请求首页
session = requests.session()
resp = session.get(
url="http://wenshu.court.gov.cn/",
cookies = {
"wzws_cid":wzws_cid
},
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
"Referer":"http://wenshu.court.gov.cn/"
},
# proxies=proxies
)
# resp = session.post(
# url="http://wenshu.court.gov.cn/Index/GetAllCountRefresh?refresh=", # 获得首页标题
# headers={
# "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
# "Referer":"http://wenshu.court.gov.cn/",
# "X-Requested-With":"XMLHttpRequest"
# }
# )
# print(resp.text)
# print("*"*100)
time.sleep(0.1)
# 请求列表页setcookie
resp = requests.get(
url="http://wenshu.court.gov.cn/List/List?sorttype=1&conditions=searchWord+1+AJLX++%E6%A1%88%E4%BB%B6%E7%B1%BB%E5%9E%8B:%E5%88%91%E4%BA%8B%E6%A1%88%E4%BB%B6",
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
"Referer":"http://wenshu.court.gov.cn/",
"X-Requested-With":"XMLHttpRequest"
},
cookies={
"wzws_cid": wzws_cid
},
# proxies=proxies
)
# 从cookie中获取生成加密参数需要的值
vjkl5 = requests.utils.dict_from_cookiejar(resp.cookies)["vjkl5"]
# print("vjkl5:",vjkl5)
# 生成加密字符串vl5x和guid
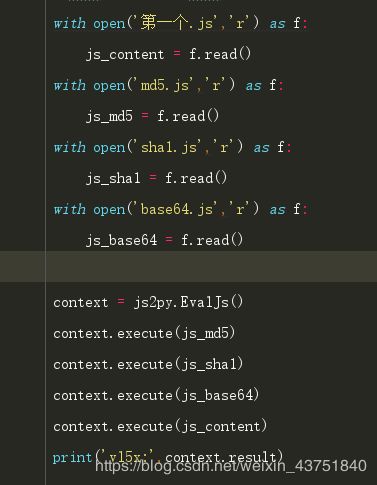
with open('第一个.js','r') as f:
js_content = f.read()
with open('md5.js','r') as f:
js_md5 = f.read()
with open('sha1.js','r') as f:
js_sha1 = f.read()
with open('base64.js','r') as f:
js_base64 = f.read()
with open('guid文件.js','r') as f:
js_guid = f.read()
context = js2py.EvalJs()
context.execute(js_md5)
context.execute(js_sha1)
context.execute(js_base64)
context.vjkl5 = vjkl5
context.execute(js_content)
context.execute(js_guid)
# print('vl5x:',context.result)
# print('guid:',context.guid)
# 整理参数向列表页发送post请求
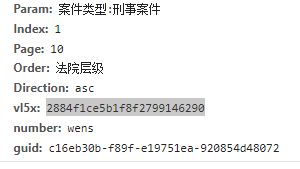
data = {
"Param":"案件类型:刑事案件",
"Index":"1",
"Page":"10",
"Order":"法院层级",
"Direction":"asc",
"vl5x":context.result,
"number":"wens",
"guid":context.guid
}
# print("data:",data)
resp = requests.post(
url="http://wenshu.court.gov.cn/List/ListContent",
data=data,
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
"Referer":"http://wenshu.court.gov.cn/List/List?sorttype=1&conditions=searchWord+1+AJLX++%E6%A1%88%E4%BB%B6%E7%B1%BB%E5%9E%8B:%E5%88%91%E4%BA%8B%E6%A1%88%E4%BB%B6",
"X-Requested-With":"XMLHttpRequest"
},
cookies={
"wzws_cid": wzws_cid,
"vjkl5":vjkl5
},
# proxies=proxies
)
# 保存获取的列表数据
with open('list_data.txt','wb') as f:
f.write(resp.content)
# 处理一下数据
context.data = resp.text
context.execute('datalist = eval(data)')
with open('Base_64.js','r',encoding='utf-8') as f:
context.execute(f.read())
with open('rawdeflate.js','r',encoding='utf-8') as f:
context.execute(f.read())
with open('pako.js','r',encoding='utf-8') as f:
context.execute(f.read())
datalist = json.loads(context.datalist)
# print(datalist)
for row in datalist:
# pprint(row)
pass
# RunEval = datalist[0]["RunEval"]
# doc_id =''
# for item in datalist[2:]:
# # print(item)
# doc_id += item["文书ID"]
# # print(doc_id)
#
# data = {
# 'runEval': RunEval,
# 'docIds': doc_id
# }
#
# print(data)
#
# resp = requests.post(
# url = 'http://wenku.jwzlai.com/common/decode/docId',
# headers={
# "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
# },
# data = data
#
# )
#
# print(resp.text)
# 破解情页
detail_url1 = 'http://wenshu.court.gov.cn/WZWSREL2NvbnRlbnQvY29udGVudD9Eb2NJRD0xM2Q0YzAxYS0wNzM0LTRlYzEtYmJhYy02NThmOGJiOGVjNjImS2V5V29yZD0='
resp = requests.get(
url=detail_url1,
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
},
cookies=new_cookies,
allow_redirects=False,
# proxies=proxies
)
# print(resp.cookies)
# print(resp.headers)
wzws_cid3 = requests.utils.dict_from_cookiejar(resp.cookies)["wzws_cid"]
location = resp.headers['Location']
print(wzws_cid3)
print(location)
DocID = re.search(r'/content/content\?DocID=(.*?)&KeyWord=',location).group(1)
print(DocID)
detail_url2 = 'http://wenshu.court.gov.cn/CreateContentJS/CreateContentJS.aspx?DocID='+DocID
resp = requests.get(
url=detail_url2,
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
"Referer": "http://wenshu.court.gov.cn/content/content?DocID={}&KeyWord=".format(DocID)
},
cookies={
"wzws_cid": wzws_cid3
},
# proxies=proxies
)
# print(resp.text)
bbb = re.search(r'(.*)var jsonData',resp.text,re.DOTALL).group(1)
content_dict = re.search(r'JSON.stringify\((.*?\).*?)\)',bbb,re.DOTALL).group(1)
content_dict = json.loads(content_dict)
pprint(content_dict)
content_html = re.search(r'jsonHtmlData = (.*)\;',bbb,re.DOTALL).group(1)
content_html = json.loads(content_html)
html_raw = re.search(r'"Html":"(.*?)"',content_html,re.DOTALL).group(1)
soup = BeautifulSoup(html_raw,'lxml')
txt_list = soup.select('div')
for txt in txt_list:
print(txt.get_text())