OpenShift 4 之AMQ Streams(2) - 用Kafka Connect访问数据源
Kafka Connect是一种可扩展的和可靠的连接Kafka框架与外部系统的框架。通过不同的Connector可以访问如数据库,键值存储,搜索索引和文件系统等不同的数据源。

本示例将配置Kafka Connect,从文件中读出数据然后发送到Topic上,最后再通过Consumer读出来。
- 创建内容如下的kafka-connect.yaml文件。
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaConnect
metadata:
name: my-connect
spec:
replicas: 1
resources:
requests:
memory: 512Mi
cpu: 200m
limits:
memory: 2Gi
cpu: 500m
readinessProbe:
initialDelaySeconds: 120
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 120
timeoutSeconds: 5
bootstrapServers: my-cluster-kafka-bootstrap:9092
config:
key.converter: org.apache.kafka.connect.storage.StringConverter
value.converter: org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable: false
value.converter.schemas.enable: false
- 执行命令创建Kafka Connect,然后查看相关资源的状态,可以看到有Deployment、ReplicaSet、Service和Pod资源。
$ oc apply -f kafka-connect.yaml -n kafka
$ oc get all -l strimzi.io/cluster=my-connect
NAME READY STATUS RESTARTS AGE
pod/my-connect-connect-75ddc48968-wd2bb 1/1 Running 1 8m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/my-connect-connect-api ClusterIP 172.30.49.47 <none> 8083/TCP 8m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/my-connect-connect 1/1 1 1 8m
NAME DESIRED CURRENT READY AGE
replicaset.apps/my-connect-connect-75ddc48968 1 1 1 8m
- 下载Kafka Connect访问的数据文件到data目录中。
$ curl -LO https://raw.githubusercontent.com/liuxiaoyu-git/OpenShift-HOL/master/uber.csv
$ mkdir data
$ mv uber.csv data/
- 为了演示,我们将数据文件传到容器内部。
$ oc project kafka
$ oc rsync data/ my-connect-connect-75ddc48968-wd2bb:/tmp
sending incremental file list
./
./uber.csv
- 进入运行Kafka Connect的Pod,确认数据文件,然后创建source-plugin.json文件。它使用了/tmp/uber.csv作为FileStreamSource类型的Connect数据源,并将数据发送到名为my-topic-2的Kafka Topic。
$ oc rsh my-connect-connect-75ddc48968-wd2bb
$ ls /tmp/uber.cvs
$ cat <<EOF >> /tmp/source-plugin.json
{
"name": "source-test",
"config": {
"connector.class": "FileStreamSource",
"tasks.max": "3",
"topic": "my-topic-2",
"file": "/tmp/uber.csv"
}
}
EOF
$ exit
- 创建内容如下的my-topic2.yaml文件,其中定义了名为my-topic-2的KafkaTopic。
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaTopic
metadata:
name: my-topic-2
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 3
replicas: 2
config:
retention.ms: 7200000
segment.bytes: 1073741824
- 执行命令创建名为my-topic2的KafkaTopic,然后查看其状态。
$ oc apply -f my-topic2.yaml -n kafka
$ oc get kafkatopic my-topic2 -n kafka
NAME PARTITIONS REPLICATION FACTOR
my-topic2 3 2
- 创建内容如下的connector-consumer.yaml,
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: connector-consumer
name: connector-consumer
spec:
replicas: 1
template:
metadata:
labels:
app: connector-consumer
spec:
containers:
- name: connector-consumer
image: strimzi/hello-world-consumer:latest
resources:
limits:
cpu: "2"
memory: 2Gi
requests:
cpu: "1"
memory: 1Gi
env:
- name: BOOTSTRAP_SERVERS
value: my-cluster-kafka-bootstrap:9092
- name: TOPIC
value: my-topic-2
- name: GROUP_ID
value: my-hello-world-consumer
- name: LOG_LEVEL
value: "INFO"
- name: MESSAGE_COUNT
value: "1000"
- 执行命令,部署可从my-topic-2读取数据的Kafka Consumer,然后查看Pod运行情况。
$ oc apply -f connector-consumer.yaml -n kafka
$ oc get pod -l app=connector-consumer -n kafka
NAME READY STATUS RESTARTS AGE
connector-consumer-6c487d477d-rcl28 1/1 Running 0 49s
- 查看Kafka Consumer的Pod日志,确认当前没有持续从my-topic-2接收到数据。
$ oc logs $(oc get pod -n kafka -l app=connector-consumer -o=jsonpath='{.items[0].metadata.name}') -n kafka -f
[main] INFO org.apache.kafka.clients.consumer.ConsumerConfig - ConsumerConfig values:
allow.auto.create.topics = true
auto.commit.interval.ms = 5000
auto.offset.reset = earliest
bootstrap.servers = [my-cluster-kafka-bootstrap:9092]
。。。
。。。
8521 [main] INFO org.apache.kafka.clients.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-my-hello-world-consumer-1, groupId=my-hello-world-consumer] Successfully joined group with generation 69
8524 [main] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=consumer-my-hello-world-consumer-1, groupId=my-hello-world-consumer] Adding newly assigned partitions: my-topic-2-0
8535 [main] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=consumer-my-hello-world-consumer-1, groupId=my-hello-world-consumer] Found no committed offset for partition my-topic-2-0
8561 [main] INFO org.apache.kafka.clients.consumer.internals.SubscriptionState - [Consumer clientId=consumer-my-hello-world-consumer-1, groupId=my-hello-world-consumer] Resetting offset for partition my-topic-2-0 to offset 0.
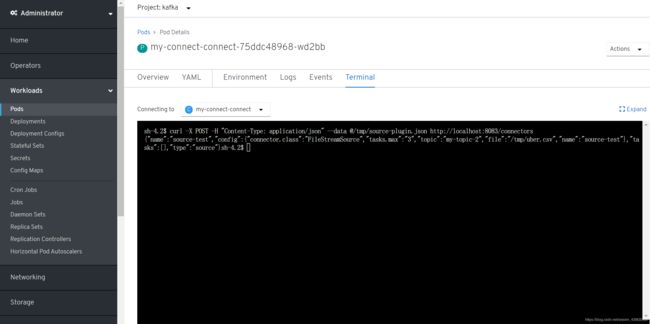
- 进入OpenShift控制台中的Administrator视图,在kafak项目中通过Workloads -> Pods找到名为my-connect-connect-xxxxxxxxx-xxxxx的Pod,然后在Terminal中执行以下命令,把uber.cvs文件发给Kakfa Connect处理。
% curl -X POST -H "Content-Type: application/json" --data @/tmp/source-plugin.json http://localhost:8083/connectors
12. 最后在(10)步的窗口确认有不断的新日志输出,这些是从my-topic-2接受到的数据,这些数据就用Kafka Connect读到的uber.csv文件内容。
。。。
2020-04-10 12:12:14 INFO KafkaConsumerExample:46 - value: 2014-08-01 01:55:00,40.7703,-73.9685,B02682
2020-04-10 12:12:14 INFO KafkaConsumerExample:43 - Received message:
2020-04-10 12:12:14 INFO KafkaConsumerExample:44 - partition: 0
2020-04-10 12:12:14 INFO KafkaConsumerExample:45 - offset: 1169
2020-04-10 12:12:14 INFO KafkaConsumerExample:46 - value: 2014-08-01 01:55:00,40.7182,-73.9892,B02682
2020-04-10 12:12:14 INFO KafkaConsumerExample:43 - Received message:
2020-04-10 12:12:14 INFO KafkaConsumerExample:44 - partition: 0
2020-04-10 12:12:14 INFO KafkaConsumerExample:45 - offset: 1170
2020-04-10 12:12:14 INFO KafkaConsumerExample:46 - value: 2014-08-01 01:56:00,40.73,-73.9807,B02598
2020-04-10 12:12:14 INFO KafkaConsumerExample:43 - Received message:
2020-04-10 12:12:14 INFO KafkaConsumerExample:44 - partition: 0
2020-04-10 12:12:14 INFO KafkaConsumerExample:45 - offset: 1171
2020-04-10 12:12:14 INFO KafkaConsumerExample:46 - value: 2014-08-01 01:57:00,40.7466,-73.9814,B02598
。。。