利用python对csv文件进行简单的数据分析
利用python对csv文件进行简单的数据分析
在通过爬虫爬取数据后,将数据放到csv文件里,为了方便观察,可以对数据进行简单的分析。下面我将对爬取的51job招聘数据中的薪资进行求平均值以及中位数操作
1.爬取数据
下面是我借用的爬取51job代码,稍加修改
# -*- coding:utf8 -*-
# 使用 xpath 方法对 51job 进行职位爬取
import requests
import json
import re
import csv
from lxml import etree
BASE_DOMAIN = 'https://search.51job.com'
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
}
Recruitments = []
def parse_page(url):
# url = 'https://search.51job.com/list/120200,000000,0000,00,9,99,python,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
resp = requests.get(url,headers=HEADERS)
text = resp.content.decode('gbk')
tree = etree.HTML(text)
PositionAndCompany = tree.xpath("//div[@class='el']//span/a/@title")
Company = PositionAndCompany[1::2]
Position = PositionAndCompany[::2]
Workplace = tree.xpath("//div[@class='el']//span[@class='t3']/text()")
Payroll = tree.xpath("//div[@class='el']//span[@class='t4']/text()")
Releasetime = tree.xpath("//div[@class='el']//span[@class='t5']/text()")
for value in zip(Position,Company,Workplace,Payroll,Releasetime):
Position,Company,Workplace,Payroll,Releasetime = value
Recruitment = {
'职位':Position,
'公司':Company,
'工作地点':Workplace,
'薪资':Payroll,
'发布时间':Releasetime,
}
Recruitments.append(Recruitment)
with open('51job.json', 'w', encoding='utf-8') as fp:
json.dump(Recruitments, fp, ensure_ascii=False)
fileHeader = ["Dutystation", "MinSalary", "MaxSalary"]
csvFile = open("51job.csv", "w")
writer = csv.writer(csvFile, lineterminator='\n')
writer.writerow(fileHeader)
with open('51job.csv', 'w', encoding='utf-8') as csv_file:
for Recruitment in Recruitments:
s=Recruitment["薪资"]
#正则表达式匹配:
res1=re.compile(r'.*?(?=-)')
ret1=res1.findall(s)
#print(s)
min=ret1[0]
res2=re.compile(r'(?<=-).*?(?=[万千元])')
ret2=res2.findall(s)
max=ret2[0]
salary=s[-3]
time=s[-1]
#统一单位(万/月):
if(salary=="千"):
min=float(min)*0.1
max=float(max)*0.1
salary="万"
if(salary=="元"):
min=float(min)*0.01
max=float(max)*0.01
salary="万"
if(time=="年"):
min=float(min)/12
max=float(max)/12
time="月"
#假定每月30天
if(time=="日"):
min=float(min)*30
max=float(max)*30
time="月"
min=float(min)
max=float(max)
min=round(min,2)
max=round(max,2)
# fp.write('{} {} {} {} {}\n'.format(
# Recruitment["工作地点"][0:2],
# min,max,salary,time
# ))
s1=Recruitment["工作地点"][0:2]
#将爬取处理后的数据存入51job.csv
d=[s1, min, max]
writer.writerow(d)
def spider():
# 前50页济南北京上海广东深圳的python招聘页的url
base_urls = 'https://search.51job.com/list/120200%252C010000%252C020000%252C030200%252C040000,000000,0000,00,9,99,python,2,{}.html'
for x in range(1,3):
page_url = base_urls.format(x)
parse_page(page_url)
print('第%s页爬取完成' % x)
def main():
spider()
if __name__ == '__main__':
main()
爬取后的数据存入51job.csv
效果如下:

2.数据分析
数据已经存入51job.csv中 下面我们对51job.csv中的最高最低薪资求平均值和中位数
新建一个date analysis.py
利用numpy中的 mean() 函数和 median() 求平均数和中位数
代码如下
import csv
import numpy as np
with open('51job.csv') as csv_file:
row = csv.reader(csv_file, delimiter=',')
next(row) # 读取首行
price1 = [] # 建立一个数组来存储薪资数据
price2 = []
# 读取除首行之后每一行的第二列数据,并将其加入到数组price1之中
# 读取除首行之后每一行的第三列数据,并将其加入到数组price2之中
for r in row:
price1.append(float(r[1])) # 将字符串数据转化为浮点型加入到数组之中
price2.append(float(r[2]))
#最低薪资的平均值 中位数
minAVG=np.mean(price1)
minAVG=round(minAVG,2)
minMED=np.median(price1)
minMED=round(minMED,2)
print('最低薪资的平均数=', minAVG)
print('最低薪资的中位数=', minMED)
#最高薪资的平均值 中位数
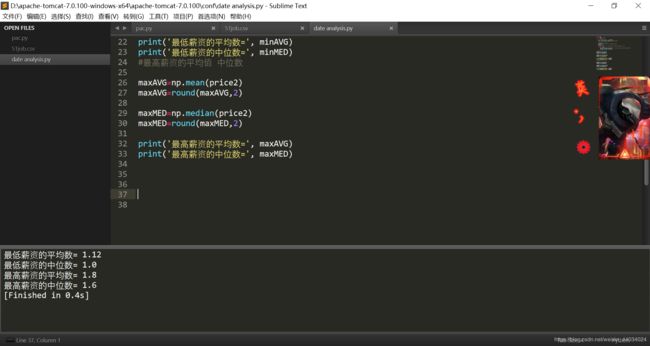
maxAVG=np.mean(price2)
maxAVG=round(maxAVG,2)
maxMED=np.median(price2)
maxMED=round(maxMED,2)
print('最高薪资的平均数=', maxAVG)
print('最高薪资的中位数=', maxMED)
运行效果如下:
这是我进行简单数据分析时的步骤,如果有不恰当的地方,欢迎留言指正