python+selenium多线程爬虫爬取boss直聘
python+selenium多线程爬虫爬取boss直聘
- 1.环境准备
- 2.获取列表页url
- 3. 正式爬取
1.环境准备
1.搭建python环境(强烈建议安装 Anaconda)
2.pip install selenium(其他依赖模块也一样)
3.Chrome driver安装(具体安装方法自行百度)
4.还需要一个开发工具如:pyCharm(也可以用Anaconda 的jupyter notebook)
2.获取列表页url
分析页面
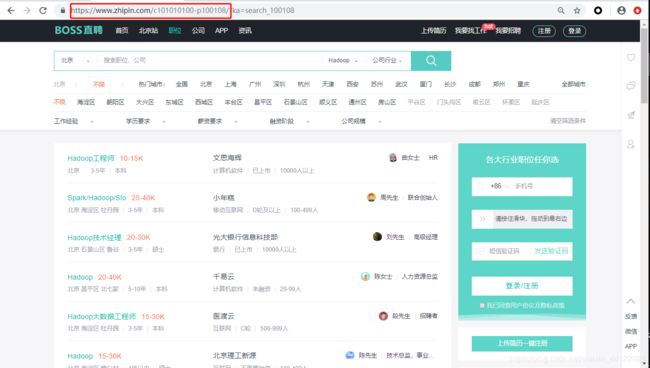
列表页访问地址:www.zhipin.com/城市编码-职位编码/所以我们要获得全部城市的编码和职位的编码
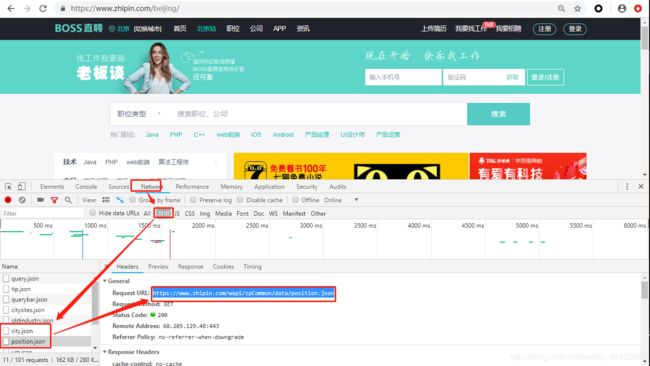
F12 => network =>xhr =>city.json/position.json 这两个接口地址可直接获取全部城市和职位信息,然后拼接一下可得到列表页url列表
准备工作好了,就可以开始了;
3. 正式爬取
直接上代码
# -*- coding: utf-8 -*-
import os
import time
import datetime
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
from selenium import webdriver
import pandas as pd
import re
import threading
from toolz import apply
location = os.getcwd() + '/fake_useragent.json'
ua = UserAgent(path=location)
# 构造请求头User-Agent 利用python的 fake_useragent 随机获得User-Agent
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache - control': 'max - age = 0',
'referer': 'https://www.zhipin.com/',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': ua.random,
'X-Requested-With': 'XMLHttpRequest'
}
mutex1 = threading.Lock()
mutex2 = threading.Lock()
data_out_path = '../data/boss_position_detail.csv'
log_out_path = '../data/boss_spider_log.txt'
url_in_path = '../data/new_list.txt'
executable_path = 'H:\study\Anaconda3\Scripts\chromedriver.exe'
# df保存到本地文件
def to_local_csv(df, path):
# 多个线程共享文件,要加锁
mutex1.acquire()
df.to_csv(path, mode='a', index=False, header=False, sep='\u0001')
mutex1.release()
# 自己写的简单保存日志的方法,用于程序运行的监控
def save_log(text):
with open(log_out_path, 'a', encoding='UTF-8') as f:
# 多个线程共享文件,要加锁
mutex2.acquire()
f.write(text + '\n')
mutex2.release()
# 读取文件,获得url列表
def read_url():
with open(url_in_path, 'r', encoding='utf-8') as f:
url_new = []
for line in f.readlines():
url_new.append(line.strip())
return url_new
# url_list:需要爬取的url列表,split_num:线程数
# 我没有稳定的代理ip 所以没设置代理,所以线程数别太多(自己用5个线程爬挺稳定的)
def split_url(url_list, split_num):
thread_list = []
# 每个线程需处理的list 大小
list_size = (len(url_list) // split_num) if (len(url_list) % split_num == 0) else ((len(url_list) // split_num) + 1)
# 开启线程
for i in range(split_num):
# 获得当前线程需要处理的url
url_list_split = url_list[
i * list_size:(i + 1) * list_size if len(url_list) > (i + 1) * list_size else len(url_list)]
thread = threading.Thread(target=get_driver, args=(url_list_split,))
thread.setName("线程" + str(i))
thread_list.append(thread)
# 在子线程中运行任务
thread.start()
print(thread.getName() + "开始运行")
# 所有线程结束以后再结束
for _item in thread_list:
_item.join()
def get_driver(url_list_split):
# 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox')
options.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(executable_path=executable_path, options=options)
driver.maximize_window()
# 获得当前线程的name 用于监控线程运行情况
thr_name = threading.current_thread().name
count = len(url_list_split)
num = 0
for position_url in url_list_split:
num += 1
page_url = position_url + '?page=1'
try:
# 获得详情页
position_detail_list = get_detail(driver, page_url, [])
# list 转换为DataFrame
df = pd.DataFrame(position_detail_list)
# 将爬取结果保存到csv
to_local_csv(df, data_out_path)
print(position_url + '保存成功 ' + thr_name + '共需处理' + str(count) + '个网址,已保存' + str(num) + '个。')
save_log(position_url + '保存成功 ' + thr_name + ' ' + datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
except Exception as e:
print(position_url + '保存失败\n' + str(e))
save_log(position_url + '保存失败\n' + str(e))
# 爬取完毕关闭 driver
driver.close()
print(thr_name + "执行完毕")
# 核心方法,获得详情页并访问详情页
def get_detail(driver, page_url, position_detail_list):
match = re.match(r'https://www.zhipin.com/(.*)/\?page=(.*)', page_url, re.M | re.I)
driver.get(page_url)
bs = BeautifulSoup(driver.page_source, "html.parser")
job_primary_list = bs.select('div.job-primary')
for job_primary in job_primary_list:
# 详情页地址
job_url = 'https://www.zhipin.com' + str(job_primary.find('h3', class_='name').a['href'])
time.sleep(0.01)
# 爬取详情页
driver.get(job_url)
bs_detail = BeautifulSoup(driver.page_source, "html.parser")
if len(bs_detail.select('div.tag-all')) > 0:
company_welfare = "|".join(i.text for i in bs_detail.select('div.tag-all')[0].find_all('span'))
else:
company_welfare = None
position_detail_list.append({
'city_position': match.group(1),
'job_name': job_primary.select('div.job-title')[0].text,
'salary': job_primary.select('span.red')[0].text,
'address_experience_degree': "|".join(str(i) for i in job_primary.p.find_all(text=True)),
'company_name': job_primary.find_all('h3')[1].a.text,
'company_info': "|".join(str(i) for i in job_primary.find_all('p')[1].find_all(text=True)),
'page': match.group(2),
'job_url': job_url,
'company_welfare': company_welfare,
'position_description': bs_detail.select('div.text')[0].text.strip()
})
print(page_url + '爬取成功')
# 如果有下一页,递归爬取
if bs.select('a.next'):
if 'javascript:;' != bs.select('a.next')[0]['href']:
next_url = 'https://www.zhipin.com' + bs.select('a.next')[0]['href']
get_detail(driver, next_url, position_detail_list)
time.sleep(0.01)
return position_detail_list
def main():
# 获得需爬取列表页url 列表
url_list = read_url()
split_url(url_list, 5)
if __name__ == '__main__':
start = datetime.datetime.now()
save_log('爬取开始:' + start.strftime("%Y-%m-%d %H:%M:%S"))
print('爬取开始:' + start.strftime("%Y-%m-%d %H:%M:%S"))
main()
end = datetime.datetime.now()
save_log('爬取结束:' + end.strftime("%Y-%m-%d %H:%M:%S") + '\n' + '总共用时' + str((end - start).seconds) + '秒')
print('爬取结束:' + end.strftime("%Y-%m-%d %H:%M:%S"))
print('总共用时' + str((end - start).seconds))
我的url_in_path

fake_useragent.json 可自行百度
爬取结果:

至此一个多线程爬虫程序就完成了