本文大约 5900 字,阅读需要大约 15 分钟
最近打算系统学习和整理机器学习方面的知识,会将之前看的 Andrew Ng 在 course 课程笔记以及最近看的书籍《hands-on-ml-with-sklearn-and-tf》结合起来,简单总结下机器学习的常用算法,由于数学功底有限,所以可能不会也暂时不能过多深入公式和算法原理,所以就做成一个入门系列吧。
这是本系列的第一篇,也是机器学习概览的上半部分
1 . 什么是机器学习
简单的定义,机器学习是通过编程让计算机从数据中进行学习的科学(和艺术)。
但还有另外两种定义,一个更广义的定义:
机器学习是让计算机具有学习的能力,无需进行明确编程。 —— 亚瑟·萨缪尔,1959
和一个工程性的定义:
计算机程序利用经验 E 学习任务 T,性能是 P,如果针对任务 T 的性能 P 随着经验 E 不断增长,则称为机器学习。 —— 汤姆·米切尔,1997
一个简单的例子,也是经常提及的例子:垃圾邮件过滤器。它可以根据垃圾邮件(比如,用户标记的垃圾邮件)和普通邮件(非垃圾邮件,也称作 ham)学习标记垃圾邮件。用来进行学习的样例称作训练集。每个训练样例称作训练实例(或样本)。在这个例子中,任务 T 就是标记新邮件是否是垃圾邮件,经验E是训练数据,性能 P 需要定义:例如,可以使用正确分类的比例。这个性能指标称为准确率,通常用在分类任务中。
2. 为什么要用机器学习
为什么要用机器学习方法呢?
原因如下:
需要进行大量手工调整或需要拥有长串规则才能解决的问题:机器学习算法通常可以简化代码、提高性能。
问题复杂,传统方法难以解决:最好的机器学习方法可以找到解决方案。
环境有波动:机器学习算法可以适应新数据。
洞察复杂问题和大量数据
一些机器学习的应用例子:
数据挖掘
一些无法通过手动编程来编写的应用:如自然语言处理,计算机视觉、语音识别等
一些自助式的程序:如推荐系统等
理解人类是如何学习的
3. 机器学习系统的类型
机器学习有多种类型,可以根据如下规则进行分类:
-
是否在人类监督下进行训练(监督,非监督,半监督和强化学习)
是否可以动态渐进学习(在线学习 vs批量学习)
它们是否只是通过简单地比较新的数据点和已知的数据点,或者在训练数据中进行模式识别,以建立一个预测模型,就像科学家所做的那样(基于实例学习 vs基于模型学习)
3.1 监督/非监督学习
第一种分类机器学习的方法是可以根据训练时监督的量和类型进行分类。主要有四类:监督学习、非监督学习、半监督学习和强化学习。
3.1.1 监督学习
监督学习,顾名思义就是带有监督的学习,而监督就是体现在训练数据都是有标签的,所有在训练模型的时候可以根据数据的真实标签不断调整模型,从而得到一个性能更好的模型。
监督学习主要有两个常见的典型的任务--分类和回归。
3.1.1.1 分类
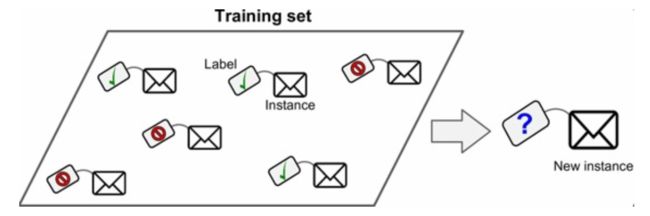
分类问题主要就是预测新数据的类别问题。例如上文提到的垃圾邮件过滤器就是一个二分类问题,将邮件分为垃圾邮件还是正常的邮件,如下图所示。
3.1.1.2 回归
回归问题主要是预测目标数值。比如给定预测房价的问题,给定一些特征,如房子大小、房间数量、地理位置等等,然后预测房子的价格。如下图所示:
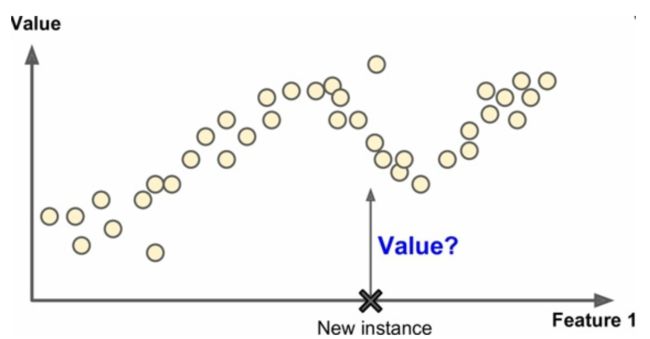
注意,一些回归算法也可以用来进行分类,反之亦然。例如,逻辑回归通常用来进行分类,它可以生成一属于每个类别的概率值,然后选择最大概率的类别作为预测的类别。
常用的监督学习算法有:
K近邻算法
线性回归
逻辑回归
支持向量机(SVM)
决策树和随机森林
神经网络
3.1.2 非监督学习
和监督学习相反,非监督学习就是采用没有标签的数据集。
非监督主要有四个典型的任务,分别是聚类、降维、异常检测和关联规则学习。
3.1.2.1. 聚类
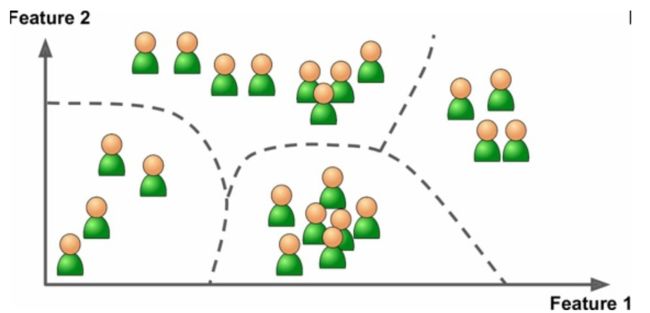
聚类就是将数据根据一定的规则分成多个类,通常是采用相似性。比如对于博客访客的聚类,通过聚类算法,检测相似性访客的分组,如下图所示。不需要告诉算法访客是哪个类别,它会自动根据访客的属性找到相互间的关系,比如它可能找出访客的职业关系,将访客分为有 40% 的是上班族,有 50% 的是学生,或者对于技术博客,可能就是根据开发方向,划分为前端、后台、移动开发、人工智能等等。甚至,如果采用层次聚类分析算法,还可以继续对上述的分类进行更加详细的划分。这种做法可以帮助博主知道自己博客的主要群体是谁,更好规划自己博客发表的文章应该以什么方向为主。
可视化算法也是极佳的非监督学习案例:给算法大量复杂的且不加标签的数据,算法输出数据的2D或3D图像。如下图所示,算法会试图保留数据的结构(即尝试保留输入的独立聚类,避免在图像中重叠),这样就可以明白数据是如何组织起来的,也许还能发现隐藏的规律。

3.1.2.2. 降维
降维的目的是简化数据、但是不能失去大部分信息。做法之一是合并若干相关的特征。例如,汽车的里程数与车龄高度相关,降维算法就会将它们合并成一个,表示汽车的磨损。这叫做特征提取。
此外,在采用机器学习算法训练的时候,可以对训练集进行降维,这样有助于提高训练速度,降低占用的硬盘和内存空间,有时候也能提高算法的性能,但必须选择合适的降维算法,否则性能实际上是很有可能会下降的。
3.1.2.3. 异常检测
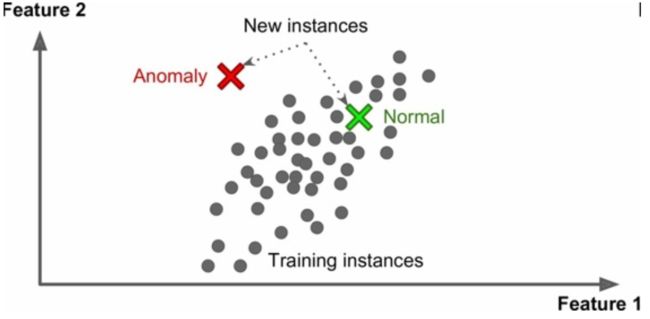
另一个重要的非监督任务是异常检测(anomaly detection)。例如,检测异常的信用卡转账以防欺诈,检测制造缺陷,或者在训练之前自动从训练数据集去除异常值。异常检测的系统使用正常值训练的,当它碰到一个新实例,它可以判断这个新实例是像正常值还是异常值。
3.1.2.4. 关联规则学习
最后,另一个常见的非监督任务是关联规则学习,它的目标是挖掘大量数据以发现属性间有趣的关系。例如,假设你拥有一个超市。在销售日志上运行关联规则,可能发现买了烧烤酱和薯片的人也会买牛排。因此,你可以将这些商品放在一起。
下面是一些最重要的非监督学习算法:
-
聚类
K 均值
层次聚类分析(Hierarchical Cluster Analysis, HCA)
期望最大值
-
可视化和降维
主成分分析(Principal Component Analysis, PCA)
核主成分分析
局部线性嵌入(Locally-Linear Embedding, LLE)
t-分布邻域嵌入算法(t-distributed Stochastic Neighbor Embedding, t-SNE)
-
关联性规则学习
Apriori 算法
Eclat算法
3.1.3 半监督学习
一些算法可以处理部分带标签的训练数据,通常是大量不带标签数据加上小部分带标签数据。这称作半监督学习。如下图所示,图中灰色圆点表示没有标签的数据,仅有几个三角形和正方形点表示带标签的数据。
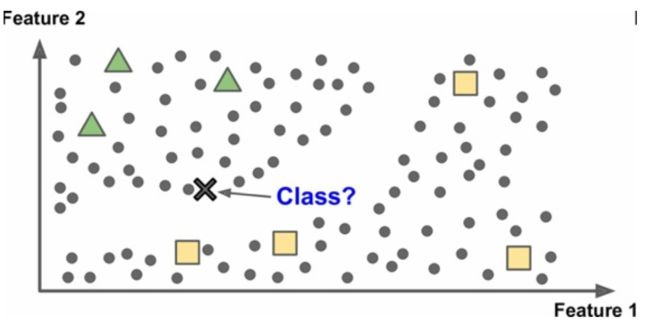
多数半监督学习算法是非监督和监督算法的结合。例如,深度信念网络(deep belief networks)是基于被称为互相叠加的受限玻尔兹曼机(restricted Boltzmann machines,RBM)的非监督组件。RBM 是先用非监督方法进行训练,再用监督学习方法进行整个系统微调。
半监督学习的示例,如一些图片存储服务,比如 Google Photos,是半监督学习的好例子。一旦你上传了所有家庭相片,它就能自动识别相同的人 A 出现了相片1、5、11 中,另一个人 B 出现在了相片 2、5、7 中。这是算法的非监督部分(聚类)。现在系统需要的就是你告诉这两个人是谁。只要给每个人一个标签,算法就可以命名每张照片中的每个人,特别适合搜索照片。
3.1.4强化学习
强化学习和上述三种学习问题是非常不同的。学习系统在这里被称为智能体( agent),可以对环境进行观察,选择和执行动作,获得奖励(负奖励是惩罚,见下图)。然后它必须自己学习哪个是最佳方法(称为策略,policy),以得到长久的最大奖励。策略决定了智能体在给定情况下应该采取的行动 。
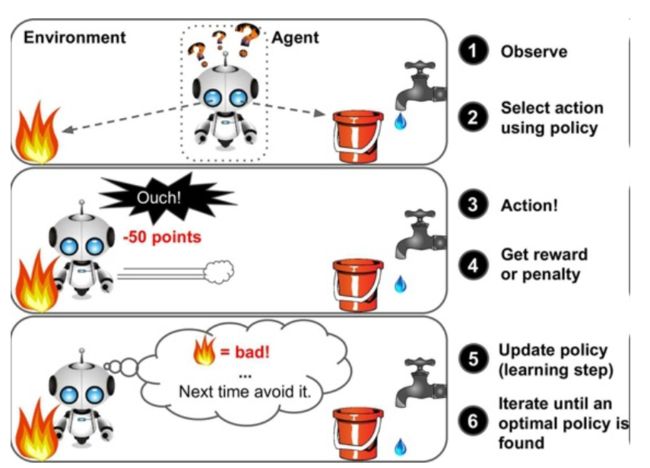
目前强化学习的应用还不算非常广,特别是结合了深度学习的强化学习,主要是应用在机器人方面,当然最著名的一个应用就是 DeepMind 的 AlphaGo 了,它是通过分析数百万盘棋局学习制胜策略,然后自己和自己下棋。要注意,在比赛中机器学习是关闭的;AlphaGo 只是使用它学会的策略。
3.2 批量和在线学习
第二种分类机器学习的准则是,它是否能从导入的数据流进行持续学习。也就是如果导入的是持续的数据流,机器学习算法能否在不断采用新数据来训练已经训练好的模型,并且新的模型对新旧数据都还有很好的性能。
3.2.1 批量学习
在批量学习中,系统不能进行持续学习:必须用所有可用数据进行训练。这通常会占用大量时间和计算资源,所以一般是线下做的。首先是进行训练,然后部署在生产环境且停止学习,它只是使用已经学到的策略。这称为离线学习。
对于批量学习算法来说,当获取到新数据的时候,就需要重新重头训练整个数据集,然后更新模型,如果是应用该算法系统,那就相当于需要更新系统,需要停掉旧版本的系统,重新上线新版本的系统。
当然,一般训练、评估、部署一套机器学习的系统的整个过程可以自动进行,所以即便是批量学习也可以适应改变。只要有需要,就可以方便地更新数据、训练一个新版本。并且对于更新周期,可以选择每 24 小时或者每周更新一次。
但是,批量学习还是存在下面的缺点:
实时性差,即对于需要快速适应变化的系统,比如预测股票变化、电商推荐系统等,就不适合采用批量学习算法;
耗费大量计算资源,用全部数据训练需要大量计算资源(CPU、内存空间、磁盘空间、磁盘 I/O、网络 I/O 等等),特别是训练集特别大的情况,更加凸显这个问题的严峻性;
无法应用在资源有限的设备上,比如需要自动学习的系统,但是如果采用智能手机,每次采用大量训练数据重新训练几个小时是非常不实际的。
3.2.2 在线学习
批量学习的缺陷和问题可以通过采用在线学习算法来解决。
在在线学习中,是用数据实例持续地进行训练,可以一次一个或一次几个实例(称为小批量)。每个学习步骤都很快且廉价,所以系统可以动态地学习到达的新数据。
在线学习虽然名字带着在线两个字,但是实际上它的训练过程也是离线的,因此应该说是持续学习或者增量学习。
在线学习有下面几个优点:
实时性好。在线学习算法非常适合接收连续流的数据,然后自动更新模型,实时性比批量学习更好;
可以节省大量计算资源。在线学习算法在学习新数据后,可以扔掉训练数据,从而节省大量存储空间;此外,训练得过程不需要加载所有训练数据,对于内存、CPU 等资源的要求也大大减少;
实现核外学习(out-of-core learning)。当内存不足以加载训练集的时候,可以采用在线学习算法多次训练,每次加载一部分训练集,即将一部分训练集当做新数据不断加载,直到训练完所有数据。
在线学习也存在两个挑战:
学习速率问题。学习速率是在线学习的一个重要参数,它反映了在线学习算法有多快地适应数据的改变,必须选择一个合适的学习速率,因为学习速率过大,系统可以很快适应新数据,但是也容易遗忘旧数据,比如图像分类问题,训练了一个 50 类分类器后,增加新的 10 类数据,一旦学习速率过快,系统只会记住新的 10 个类别,忘记了前面的 50 个类别的数据。相反的,如果你设定的学习速率低,系统的惰性就会强:即,它学的更慢,但对新数据中的噪声或没有代表性的数据点结果不那么敏感。
坏数据的影响。如果采用坏数据训练,会破坏系统的性能。要减小这种风险,你需要密集监测,如果检测到性能下降,要快速关闭(或是滚回到一个之前的状态)。你可能还要监测输入数据,对反常数据做出反应(比如,使用异常检测算法)。
3.3 基于实例 vs 基于模型学习
第三种分类机器学习的方法是判断它们是如何进行归纳推广的。大多机器学习任务是关于预测的。这意味着给定一定数量的训练样本,系统需要能推广到之前没见到过的样本。对训练数据集有很好的性能还不够,真正的目标是对新实例预测的性能。
有两种主要的归纳方法:基于实例学习和基于模型学习。
3.3.1 基于实例学习
基于实例学习是系统先用记忆学习案例,然后使用相似度测量推广到新的例子,如下图所示:
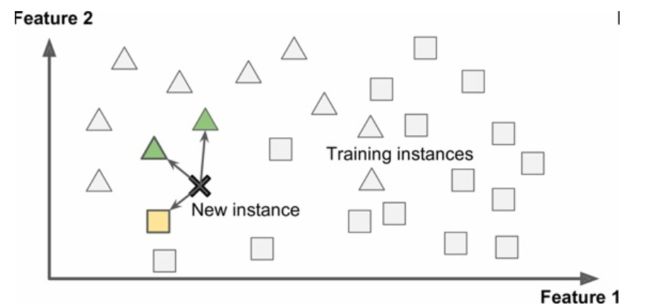
这种学习算法可以说是机器学习中最简单的算法了,它实际上就是采用存储的数据集进行分类或者回归,典型的算法就是 KNN 算法,即 K 近邻算法,它就是将新的输入数据和已经保存的训练数据采用相似性度量(一般采用欧式距离)得到最近的 K 个训练样本,并采用 K 个训练样本中类别出现次数最多的类别作为预测的结果。
所以,这种算法的缺点就比较明显了:
一是对存储空间的需求很大,需要占用的空间直接取决于实例数量的大小;
二是运行时间比较慢,因为需要需要与已知的实例进行比对。
3.3.2 基于模型学习
和基于实例学习相反的就是基于模型学习:建立这些样本的模型,然后使用这个模型进行预测。如下图所示:
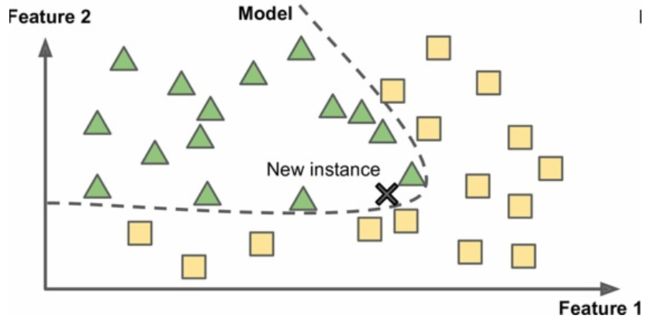
基于模型学习算法的流程一般如下所示:
研究数据。先对数据进行分析,这可能包含清洗数据、特征筛选、特征组合等等
选择模型。选择合适的模型,从简单的线性回归、逻辑回归,到慢慢复杂的随机森林、集成学习,甚至深度学习的卷积神经网络模型等等
用训练数据进行训练。也就是寻找最适合算法模型的参数,使得代价函数取得最小值。
使用模型对新案例进行预测(这称作推断)。预测结果非常好,就能上线系统;如果不好,就需要进行错误分析,问题出现在哪里,是数据问题还是模型问题,找到问题,然后继续重复这个流程。
4. 小结
最后,总结下:
机器学习就是让机器通过学习数据得到解决更好解决某些问题的能力,而不需要确定的代码规则;
机器学习的应用非常广泛,包含图像、自然语言处理、语音、推荐系统和搜索等方面,每个方面还有更加具体详细的应用方向;
机器学习按照不同的划分标准可以分为不同的学习类型,包括监督和非监督学习、批量和在线学习,基于实例和基于模型学习;
最常见的监督学习任务是分类和回归;
常见的非监督学习任务是聚类、降维、异常值检测和关联规则学习;
以上就是本文的主要内容和总结,欢迎关注我的微信公众号--机器学习与计算机视觉 或者扫描下方的二维码,和我分享你的建议和看法,指正文章中可能存在的错误,大家一起交流,学习和进步!
