最近在学习斯坦福2017年秋季学期的《强化学习》课程,感兴趣的同学可以follow一下,Sergey大神的,有英文字幕,语速有点快,适合有一些基础的入门生。
今天主要总结上午看的有关DQN的一篇论文《Human-level control through deep reinforcement learning》,在Atari 2600 games上用DQN网络训练的,训练结果明,DQN能够比较稳定的收敛到Human-level的游戏水平。
前言
目前,强化学习已经在现实中很多复杂的情形中取得小小胜利,尤其是在可人工构建有效特征、可全观测的低维状态空间等领域。当然也在一些任务场景中碰了不少的壁:智能体必须学会从高维的“感官”输入中,识别并“感知”外界环境的特征表示,并从过去的经验中,学习以及迁移适应新的环境。这对人和动物来说,是与生俱来的能力,是和我们层级的感知系统与自我强化学习的神秘结合有关。
论文摘要
本文提出了一种Deep Q-Network(DQN),借助 端到端(end-to-end) 的强化学习方法能够直接从高维的输入中,学习一种很优的策略(policy)。输入是游戏的实时图像(当前状态S),借助卷积神经网络捕捉局部特征的关联性,输出所有可能采取动作A的概率分布,论文引入了经验回放(Experience Replay)。
思路
Action-Value Function
DQN中,借助了深度神经网络来拟合动作-值函数,即折扣累计回报:
![]()
其中π是要采取的策略,即在观察到状态s时,按照策略采取动作a。
![]()
强化学习过程常常不稳定,而且训练时易于发散(diverge),尤其当神经网络采用非线性函数逼近Q时。主要有以下原因:
- 在训练时,输入的观察序列(样本)之间具有关联性。比如后个序列样本,是紧着前一个样本的。
- Q函数小小的更新可能给策略(policy)带来很大的波动(更新前后策略分布明显有别),并进一步改变数据分布(策略影响下一步动作选取)
- 动作-值函数Q与目标值(target value)的关联性。目标值定义如下:
![]()
经验回放
借助深度网络来拟合Q函数这里就不做赘述了,详见下文的网络图。论文作者在模型训练中加入了 经验回放(Expericen Replay),这里解释一下这个非常有用的概念(敲黑板~~):
在训练过程中,会维护一个序列样本池Dt= {e1, ...., et},其中et=(st, at, rt, st+1),et就是在状态st下,采取了动作at,转移到了状态st+1,得到回报rt,这样就形成了一个样本(经验),一般样本池大小有限制(设为N)
回放的意思,就是在训练中,比如让agent玩游戏,并不是把样本按照时间顺序喂给网络,而是在一局游戏未结束之前,把生成的样本(经验)都更新地扔进经验池中,从池中平均采样minBatch个,作为训练样本
这样,通过回放,就可以减少上面提到的因为前后样本存在关联导致的强化学习震荡和发散问题。还有以下好处:
- 保证了每个样本在权重更新中,都有足够的可能被利用多次,提高样本利用率
- 直接从连续的样本学习会导致震荡问题,随机从样本池抽取,可以打乱这种关联性
- 形象化解释是,当agent在上一个样本最后采取的动作是left时,在采样中,可以只从状态为left的样本中进行采样,保证训练的分布更具有有效性
Double Q-network 迭代
因为在逼近Q函数时,由于目标值函数与下个状态的最优动作对应的Q函数有关,而动作选取又依赖于策略π的更新,因此二者相互关联。
在DQN中我们用网络拟合Q(s, a; θ),其中θ是网络中权重参数,Q-learning的迭代更新使用如下的loss函数:
![]()
其中θi是第 i 步Q-network参数;θ-是计算第i步的目标值(target value)。 一般θi更新C步,θ-才更新一步。
算法细节
预处理
论文是基于Atari 2600视频帧图像数据,210×160像素,128色,不作处理的话,对计算内存要求太高。
首先,取前后两帧图像的最大值。因为有些闪烁的像素只出现在偶数帧,不出现在奇数帧
然后,从RGB数据中提取亮度作为Y通道值,并将图像缩放到84×84
作者最后也采用最相邻的m(取值为4)帧图像,进行堆叠(stack),生成最后的输入图像。(堆叠??相邻m帧取平均?)
构建模型
1.输入
网络输入是84×84×4的经过预处理后的图像
2.卷积层和全连接层
输入是游戏的视频帧,通过3层卷积层,后接2层全连接层,最后输出当前状态(视频帧)在采取的所有动作的Q值函数。作者在论文中提到,此模型尽可能的少的进行先验假设。
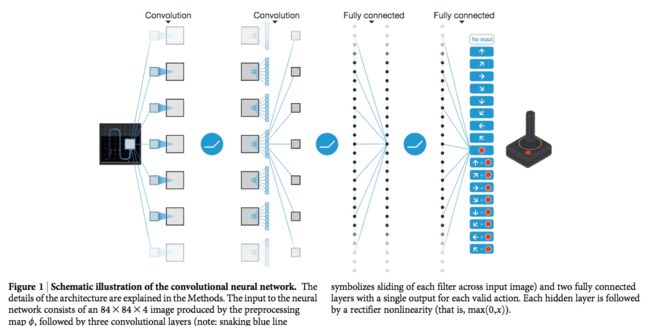
- 第一层卷积—— 32 filters of 8×8, 步长4,Relu 激活
- 第二层卷积——64 filters of 4×4,步长2,Relu 激活
- 第三层卷积——64 filters of 3×3,步长1,Relu 激活
- 全连接层——512隐藏层单元,Relu 几乎
- 输出层——与action的数目有关系
训练细节
需要提到的第一点,在训练过程中,作者clipping了rewards。具体操作是:正向回报clip到1,负向回报clip到-1,0表示无回报。
为什么要clip?(黑人问号脸o(╯□╰)o)
以这种方式处理回报值,可以限制误差传导的幅度,更容易保证在不同的游戏之间保持相同的学习率。同时,不clip的话会影响agent的性能,因为不同的量级回报会导致求导问题(不可导??)
实验中采用了RMSProb的梯度优化方法,mini-batch设置为32。在选取贪心策略的参数时,在前1M帧从1.到0.1递减,之后保持0.1不变。
同时,在每个episode训练时,采用k-th跳步法,即每隔k个帧进行样本选择,这样在相同的时间里,可以训练k次。
loss function
最优动作-值函数遵循一个重要的条件:贝尔曼等式
对于状态 s’ 的所有可能动作 a’ ,Q(s’, a’)是最优值,则最优的策略是最大化r+γQ(s’, a’)
![]()
因此借助贝尔曼进行Q的迭代更新:
![]()
但实际上,这种方式并不可行。因为动作-值函数是对每个序列进行独立评估的,并未涉及任何生成过程。因此,更常用函数逼近方法来估计动作-值函数,比如线性函数逼近,或者借助神经网络进行非线性函数逼近。
![]()
在迭代过程中计算均方差:
![]()
进一步约化为:
![]()
在监督学习中,目标值在训练过程中是确定的。但是在这里,目标值依赖于网络权重,在每一步的梯度优化中,我们固定先前迭代的参数θi-,去优化Loss函数。上式中的最后一项,是目标值方差,一般常忽略不作处理(不依赖与θi)。
对loss函数求导:
![]()
训练过程
采用经验回放的Deep Q-learning算法。训练过程如下:

在训练过程中,采用贪心策略,即在网络输出得到的所有动作值函数Q时,并非以直接选取最大值对应的动作,而是采取ξ-greedy policy,即可能以很小的概率选取其他动作,以保证探索空间的多样性。在追踪平均每个episode的得分情况,可以看出Q函数能够稳定的收敛到一定值。
- model-free——算法直接使用模拟器的样本解决强化学习任务,并没有显式的估计回报和transition dynamics P(r, s’|s, a)
- off-policy——算法学习的是贪心策略 a=argmaxQ(s,a’;θ),按照行为分布来确保状态空间的足够性探索
小结
- 在论文中,作者还提到DQN能够学习到相对长期的策略(提到在小霸王里消砖的那款游戏:agent可以通过强化学习学到,优先把一个角打通,然后就会在天花板里来回谈,以获得很高的回报)
- 盛赞了一下提出的DQN网络以很少的先验知识,简单的网络,相同的模型算法,就能在多样的环境中(多款游戏),仅借助像素信息和游戏得分,得到human-level的agent。
- Replay算法很好使,减少训练的震荡性
- 独立的target value网络(其实就是复制了一下Q-network参数,延迟C step 进行更新)