大数据【企业级360°全方位用户画像】匹配型标签开发
写在前面: 博主是一名软件工程系大数据应用开发专业大二的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:http://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
经过了用户画像,标签系统的介绍,又经过了业务数据调研与ETL处理之后,本篇博客,我们终于可以迎来【企业级用户画像】之标签开发。

文章目录
- 导入pom依赖
- HBase元数据样例类
- HBase数据源source
- 性别标签主程序
- 定义主程序入口,并连接jdbc
- 读取MySQL四级标签
- 读取MySQL五级标签
- 读取Hbase中的数据
- 标签匹配
- 将最终结果写入到Hbase
- 完整源码
- 小结
我们根据标签的计算方式的不同,我们将所有的标签划分成3种不同的类型:
■ 匹配型:通过匹配对应的值来确定标签结果
■ 统计型:按照一定的范围进行汇总分类得到标签结果
■ 挖掘型:需要通过多个维度利用一定的算法才能得到的标签
如果是匹配和统计型标签,我们只需要从数据库中将对应的业务数据查询出来,分析即可。但如果涉及到了挖掘型标签,就不可避免地涉及到机器学习的算法使用。
但标签开发流程大体如下:
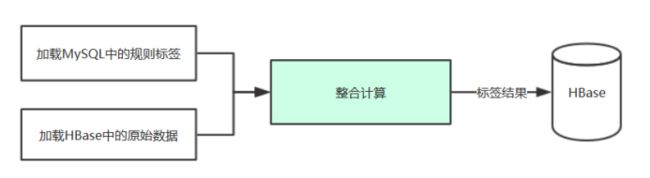
根据流程,我们的开发思路如下:
从MySQL中获取4级和5级的数据:id和rule
从4级rule中获取HBase数据源信息
从5级rule中获取匹配规则
加载HBase数据源
根据需求进行标签计算
数据落地
由于篇幅问题,本篇博客我们先来介绍匹配型标签的开发代码书写。
导入pom依赖
<properties>
<scala.version>2.11.8scala.version>
<spark.version>2.2.0spark.version>
<hbase.version>1.2.0-cdh5.14.0hbase.version>
<solr.version>4.10.3-cdh5.14.0solr.version>
<mysql.version>8.0.17mysql.version>
<slf4j.version>1.7.21slf4j.version>
<maven-compiler-plugin.version>3.1maven-compiler-plugin.version>
<build-helper-plugin.version>3.0.0build-helper-plugin.version>
<scala-compiler-plugin.version>3.2.0scala-compiler-plugin.version>
<maven-shade-plugin.version>3.2.1maven-shade-plugin.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-mllib_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.scalanlpgroupId>
<artifactId>breeze_2.11artifactId>
<version>0.13version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>${hbase.version}version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-commonartifactId>
<version>${hbase.version}version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>${hbase.version}version>
dependency>
<dependency>
<groupId>org.apache.solrgroupId>
<artifactId>solr-coreartifactId>
<version>${solr.version}version>
dependency>
<dependency>
<groupId>org.apache.solrgroupId>
<artifactId>solr-solrjartifactId>
<version>${solr.version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>${mysql.version}version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>${slf4j.version}version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-simpleartifactId>
<version>${slf4j.version}version>
dependency>
<dependency>
<groupId>cn.itcast.up29groupId>
<artifactId>commonartifactId>
<version>1.0-SNAPSHOTversion>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojogroupId>
<artifactId>build-helper-maven-pluginartifactId>
<version>${build-helper-plugin.version}version>
<executions>
<execution>
<phase>generate-sourcesphase>
<goals>
<goal>add-sourcegoal>
goals>
<configuration>
<sources>
<source>src/main/javasource>
<source>src/main/scalasource>
sources>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>${maven-compiler-plugin.version}version>
<configuration>
<encoding>UTF-8encoding>
<source>1.8source>
<target>1.8target>
<verbose>trueverbose>
<fork>truefork>
configuration>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>${scala-compiler-plugin.version}version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<archive>
<manifest>
<mainClass>cn.itcast.up29.TestTagmainClass>
manifest>
<manifestEntries>
<Class-Path>.Class-Path>
manifestEntries>
archive>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
<repositories>
<repository>
<id>clouderaid>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
repositories>
HBase元数据样例类
为了方便在后面主程序中对元数据信息进行封装调用,我们这里先提前定义好所需要使用到的样例类。
case class HBaseMeta (
inType: String,
zkHosts: String,
zkPort: String,
hbaseTable: String,
family: String,
selectFields: String,
rowKey: String
)
object HBaseMeta{
val INTYPE = "inType"
val ZKHOSTS = "zkHosts"
val ZKPORT = "zkPort"
val HBASETABLE = "hbaseTable"
val FAMILY = "family"
val SELECTFIELDS = "selectFields"
val ROWKEY = "rowKey"
}
case class TagRule(
id:Int,
rule:String
)
HBase数据源source
因为我们在进行标签的开发过程中,需要读取Hbase中的数据,若使用常规的方法,从hbase 客户端读取效率较慢,所以我们本次将hbase作为【数据源】,这样读取效率较快。
将hbase作为【数据源】来进行操作,我们需要提前定义工具类。

图示工具类代码较多,这里就不贴出来了,感兴趣的朋友可以后台找我获取。
性别标签主程序
在准备好了样例类和工具类代码后,我们正式开始写主程序的代码。因为本篇博客是对匹配型标签进行开发,这里我们以人口属性标签分类下的性别标签为例进行开发。
定义主程序入口,并连接jdbc
根据流程图,我们需要先读取MySQL中的数据,所以我们先连接JDBC。这里为了后续对MySQL元数据信息的一个封装,还定义了一个方法进行数据的封装。
object GenderTag {
// 程序的入口
def main(args: Array[String]): Unit = {
// 1. 创建SparkSQL
// 用于读取mysql , hbase等数据
val spark: SparkSession = SparkSession.builder().appName("GenderTag").master("local[*]").getOrCreate()
//2 连接mysql 数据库
//url: String, table: String, properties: Properties
// 设置Spark连接MySQL所需要的字段
var url: String ="jdbc:mysql://bd001:3306/tags_new2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&user=root&password=123456"
var table: String ="tbl_basic_tag" //mysql数据表的表名
var properties:Properties = new Properties
//连接mysql
val mysqlConn: DataFrame = spark.read.jdbc(url,table,properties)
}
//将mysql中的四级标签的rule 封装成HBaseMeta
//方便后续使用的时候方便调用
def toHBaseMeta(KVMap: Map[String, String]): HBaseMeta = {
//开始封装
HBaseMeta(KVMap.getOrElse("inType",""),
KVMap.getOrElse("zkHosts",""),
KVMap.getOrElse("zkPort",""),
KVMap.getOrElse("hbaseTable",""),
KVMap.getOrElse("family",""),
KVMap.getOrElse("selectFields",""),
KVMap.getOrElse("rowKey","")
)
}
}
读取MySQL四级标签
通过读取MySQL中的四级标签,我们可以为读取hbase数据做准备(因为四级标签的属性中含有hbase的一系列元数据信息)。又因为通过查询数据库获取到的结果类型不利于我们样例类的封装,所以我们还需要导入隐式转换,方便将其进行格式的转变。
//引入隐式转换
import spark.implicits._
//引入java 和scala相互转换
import scala.collection.JavaConverters._
//引入sparkSQL的内置函数
import org.apache.spark.sql.functions._
//3 读取Mysql数据库的四级标签
// 为读取hbase数据做准备
val fourTagsDS: Dataset[Row] = mysqlConn.select("id","rule").where("id=4")
// 这个字符串读取数据不好用 inType=HBase##zkHosts=192.168.10.20##zkPort=2181##hbaseTable=tbl_users##family=detail##selectFields=id,gender
// 将上述数据转为样例类,以便于后面读取数据
// 遍历四级标签数据fourTags
val KVMap: Map[String, String] = fourTagsDS.map(row => {
// 获取到rule的值
val RuleValue: String = row.getAs("rule").toString
/*
inType=HBase##
zkHosts=192.168.10.20##
zkPort=2181##
hbaseTable=tbl_users##
family=detail##
selectFields=id,gender
*/
//使用“##”对数据继续切分
val KVMaps: Array[(String, String)] = RuleValue.split("##").map(kv => {
val arr: Array[String] = kv.split("=")
//zkHosts 192.168.10.20 , zkPort 2181
(arr(0), arr(1))
})
KVMaps
}).collectAsList().get(0).toMap
// 考虑到KVMaps的返回值类型为Dataset[Array[(String, String)]]
// 为了后续方便调用,我们这里引入隐式转换,使用collectAsList将其转换成List,再转换成的Map
println(KVMap)
/*
Map(selectFields -> id,gender, inType -> HBase, zkHosts -> 192.168.10.20, zkPort -> 2181, hbaseTable -> tbl_users, family -> detail)
*/
//开发toHBaseMeta方法 将KVMap 封装成为样例类HBaseMeta
var hbaseMeta:HBaseMeta=toHBaseMeta(KVMap)
读取MySQL五级标签
获取完了四级标签,我们这里再来获取五级标签。同样,为了方便后续使用,也使用到了隐式转换所提供的方法,将查询的结果转换成了List类型。
//4 读取mysql数据库中的五级标签
// 匹配性别
val fiveTagsDS: Dataset[Row] = mysqlConn.select('id ,'rule).where("pid=4")
// 获取出id 和 rule
// 将FiveTagsDS 封装成样例类TagRule
val fiveTageList: List[TagRule] = fiveTagsDS.map(row => {
// row 是一条数据
// 获取出id 和 rule
val id: Int = row.getAs("id").toString.toInt
val rule: String = row.getAs("rule").toString
// 封装样例类
TagRule(id,rule)
}).collectAsList() // 将DataSet转换成util.List[TagRule] 这个类型遍历时无法获取id,rule数据
.asScala.toList // 将util.List转换成list 需要隐式转换 import scala.collection.JavaConverters._
// for(a<- fiveTageList){
// println(a.id+" "+a.rule)
// }
//5 1
//6 2
读取Hbase中的数据
通过前面对于四级标签的一个查询,我们将Hbase元数据信息以及封装成了一个样例类。这里在进行连接的时候,直接通过对象.的形式进行调用,确实简单方便了许多。
// 5. 根据mysql数据中的四级标签, 读取hbase数据
// 若使用hbase 客户端读取效率较慢,将hbase作为【数据源】,读取效率较快
val hbaseDatas: DataFrame = spark.read.format("com.czxy.tools.HBaseDataSource")
// hbaseMeta.zkHosts 就是 192.168.10.20 和 下面是两种不同的写法
.option("zkHosts",hbaseMeta.zkHosts)
.option(HBaseMeta.ZKPORT, hbaseMeta.zkPort)
.option(HBaseMeta.HBASETABLE, hbaseMeta.hbaseTable)
.option(HBaseMeta.FAMILY, hbaseMeta.family)
.option(HBaseMeta.SELECTFIELDS, hbaseMeta.selectFields)
.load()
// 展示一些数据
hbaseDatas.show(5)
/*
+---+------+
| 1| 2|
| 10| 2|
|100| 2|
|101| 1|
|102| 2|
标签匹配
已经获取到了MySQL中五级标签和Hbase数据库中的内容,我们就可以进行标签的一个匹配。
// 6 标签匹配
// 根据五级标签数据和hbase数据进行标签匹配 得到最终的标签
// 编写udf函数 例如输入是1,2 返回不同性别对应的id值5或者6
val GetTagId: UserDefinedFunction = udf((gender: String) => {
// 设置标签默认值
var id: Int = 0
// 遍历五级标签
for (ruleOb <- fiveTageList) {
// 当用户数据的gender与五级标签的id相等
// 那么返回五级标签的id
if (gender == ruleOb.rule) {
id = ruleOb.id
}
}
id
})
// 标签匹配
val userTags: DataFrame = hbaseDatas.select('id.as("userId"),GetTagId('gender).as("tagsId"))
// 输出查看效果
userTags.show()
/*
+------+------+
|userId|tagsId|
+------+------+
| 1| 6|
| 10| 6|
| 100| 6|
*/
将最终结果写入到Hbase
已经得到结果,我们将其存储进Hbase进行保存。
//7 将最终的标签写入Hbase
userTags.write.format("com.czxy.tools.HBaseDataSource")
.option("zkHosts", hbaseMeta.zkHosts)
.option(HBaseMeta.ZKPORT, hbaseMeta.zkPort)
.option(HBaseMeta.HBASETABLE,"test")
.option(HBaseMeta.FAMILY, "detail")
.option(HBaseMeta.SELECTFIELDS, "userId,tagsId")
.save()
完整源码
为了方便大家阅读,这里贴出完整源码。
import java.util.Properties
import com.czxy.bean.{HBaseMeta, TagRule}
import org.apache.spark.sql._
import org.apache.spark.sql.expressions.UserDefinedFunction
/*
* @Auther: Alice菌
* @Date: 2020/6/4 15:26
* @Description:
流年笑掷 未来可期。以梦为马,不负韶华!
*/
/* Gender 用于性别标签的计算 */
object GenderTag {
// 程序的入口
def main(args: Array[String]): Unit = {
// 1. 创建SparkSQL
// 用于读取mysql , hbase等数据
val spark: SparkSession = SparkSession.builder().appName("GenderTag").master("local[*]").getOrCreate()
//2 连接mysql 数据库
/* spark.read.format("jdbc")
.option("","")
.option("","")
.load() */
//url: String, table: String, properties: Properties
// 设置Spark连接MySQL所需要的字段
var url: String ="jdbc:mysql://bd001:3306/tags_new2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&user=root&password=123456"
var table: String ="tbl_basic_tag" //mysql数据表的表名
var properties:Properties = new Properties
//连接mysql
val mysqlConn: DataFrame = spark.read.jdbc(url,table,properties)
//引入隐式转换
import spark.implicits._
//引入java 和scala相互转换
import scala.collection.JavaConverters._
//引入sparkSQL的内置函数
import org.apache.spark.sql.functions._
//3 读取Mysql数据库的四级标签
// 为读取hbase数据做准备
val fourTagsDS: Dataset[Row] = mysqlConn.select("id","rule").where("id=4")
// 这个字符串读取数据不好用 inType=HBase##zkHosts=192.168.10.20##zkPort=2181##hbaseTable=tbl_users##family=detail##selectFields=id,gender
// 将上述数据转为样例类,以便于后面读取数据
// 遍历四级标签数据fourTags
val KVMap: Map[String, String] = fourTagsDS.map(row => {
// 获取到rule的值
val RuleValue: String = row.getAs("rule").toString
/*
inType=HBase##
zkHosts=192.168.10.20##
zkPort=2181##
hbaseTable=tbl_users##
family=detail##
selectFields=id,gender
*/
//使用“##”对数据继续切分
val KVMaps: Array[(String, String)] = RuleValue.split("##").map(kv => {
val arr: Array[String] = kv.split("=")
//zkHosts 192.168.10.20 , zkPort 2181
(arr(0), arr(1))
})
KVMaps
}).collectAsList().get(0).toMap
// 考虑到KVMaps的返回值类型为Dataset[Array[(String, String)]]
// 为了后续方便调用,我们这里引入隐式转换,使用collectAsList将其转换成List,再转换成的Map
println(KVMap)
/*
Map(selectFields -> id,gender, inType -> HBase, zkHosts -> 192.168.10.20, zkPort -> 2181, hbaseTable -> tbl_users, family -> detail)
*/
//开发toHBaseMeta方法 将KVMap 封装成为样例类HBaseMeta
var hbaseMeta:HBaseMeta=toHBaseMeta(KVMap)
//println( hbaseMeta.hbaseTable+" "+ hbaseMeta.family+" "+ hbaseMeta.selectFields)
/*
tbl_users detail id,gender
*/
//4 读取mysql数据库中的五级标签
// 匹配性别
val fiveTagsDS: Dataset[Row] = mysqlConn.select('id ,'rule).where("pid=4")
// 获取出id 和 rule
// 将FiveTagsDS 封装成样例类TagRule
val fiveTageList: List[TagRule] = fiveTagsDS.map(row => {
// row 是一条数据
// 获取出id 和 rule
val id: Int = row.getAs("id").toString.toInt
val rule: String = row.getAs("rule").toString
// 封装样例类
TagRule(id,rule)
}).collectAsList() // 将DataSet转换成util.List[TagRule] 这个类型遍历时无法获取id,rule数据
.asScala.toList // 将util.List转换成list 需要隐式转换 import scala.collection.JavaConverters._
// for(a<- fiveTageList){
// println(a.id+" "+a.rule)
// }
//5 1
//6 2
// 5. 根据mysql数据中的四级标签, 读取hbase数据
// 若使用hbase 客户端读取效率较慢,将hbase作为【数据源】,读取效率较快
val hbaseDatas: DataFrame = spark.read.format("com.czxy.tools.HBaseDataSource")
// hbaseMeta.zkHosts 就是 192.168.10.20 和 下面是两种不同的写法
.option("zkHosts",hbaseMeta.zkHosts)
.option(HBaseMeta.ZKPORT, hbaseMeta.zkPort)
.option(HBaseMeta.HBASETABLE, hbaseMeta.hbaseTable)
.option(HBaseMeta.FAMILY, hbaseMeta.family)
.option(HBaseMeta.SELECTFIELDS, hbaseMeta.selectFields)
.load()
// 展示一些数据
hbaseDatas.show(5)
/*
+---+------+
| 1| 2|
| 10| 2|
|100| 2|
|101| 1|
|102| 2|
*/
// 6 标签匹配
// 根据五级标签数据和hbase数据进行标签匹配 得到最终的标签
// 编写udf函数 例如输入是1,2 返回不同性别对应的id值5或者6
val GetTagId: UserDefinedFunction = udf((gender: String) => {
// 设置标签默认值
var id: Int = 0
// 遍历五级标签
for (ruleOb <- fiveTageList) {
// 当用户数据的gender与五级标签的id相等
// 那么返回五级标签的id
if (gender == ruleOb.rule) {
id = ruleOb.id
}
}
id
})
// 标签匹配
val userTags: DataFrame = hbaseDatas.select('id.as("userId"),GetTagId('gender).as("tagsId"))
// 输出查看效果
userTags.show()
/*
+------+------+
|userId|tagsId|
+------+------+
| 1| 6|
| 10| 6|
| 100| 6|
*/
//7 将最终的标签写入Hbase
userTags.write.format("com.czxy.tools.HBaseDataSource")
.option("zkHosts", hbaseMeta.zkHosts)
.option(HBaseMeta.ZKPORT, hbaseMeta.zkPort)
.option(HBaseMeta.HBASETABLE,"test")
.option(HBaseMeta.FAMILY, "detail")
.option(HBaseMeta.SELECTFIELDS, "userId,tagsId")
.save()
}
//将mysql中的四级标签的rule 封装成HBaseMeta
//方便后续使用的时候方便调用
def toHBaseMeta(KVMap: Map[String, String]): HBaseMeta = {
//开始封装
HBaseMeta(KVMap.getOrElse("inType",""),
KVMap.getOrElse("zkHosts",""),
KVMap.getOrElse("zkPort",""),
KVMap.getOrElse("hbaseTable",""),
KVMap.getOrElse("family",""),
KVMap.getOrElse("selectFields",""),
KVMap.getOrElse("rowKey","")
)
}
}
小结
本篇博客主要为大家提供了匹配型标签如何进行开发的一个步骤流程。每一步对应的源码也都有详细的注释,相信有一定大数据基础的朋友是能够看懂的。后续博主会更新其他类型标签开发的博客,敬请期待
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波
